对抗知识焦虑,从看懂这条开始
App 下载
雾霾里AI看不清目标?用语言给它当导航
图像语义消失|语言引导AI|雾天目标检测|云南大学|中国石油大学(华东)|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像语义消失|语言引导AI|雾天目标检测|云南大学|中国石油大学(华东)|自动驾驶|人工智能
想象你开着车扎进初春的山东海雾里——前方50米的行人只剩个模糊影子,连老司机都要攥紧方向盘。但比人眼更慌的是自动驾驶的AI:它面对的不是模糊,是「语义消失」——那些用来识别行人的边缘、纹理,全被雾气啃没了。过去工程师们总想着先给AI「修图」,把雾气P掉再检测,可结果要么背景清晰了行人还是糊的,要么修图带来的噪声反而让AI认错了目标。直到中国石油大学(华东)和云南大学的团队换了个思路:不修图,直接用语言给AI「指路」。
传统的思路像给AI配了个自动美颜相机:不管三七二十一先把整张图的雾气磨掉,再喂给目标检测模型。但问题恰恰出在「整张图」——雾气对画面的侵蚀是不均匀的:远处的行人可能只剩个轮廓,近处的路牌却还清晰。美颜式的增强对所有像素一视同仁,要么把背景的噪点一起放大,要么为了照顾全局把行人仅存的细节也磨没了。
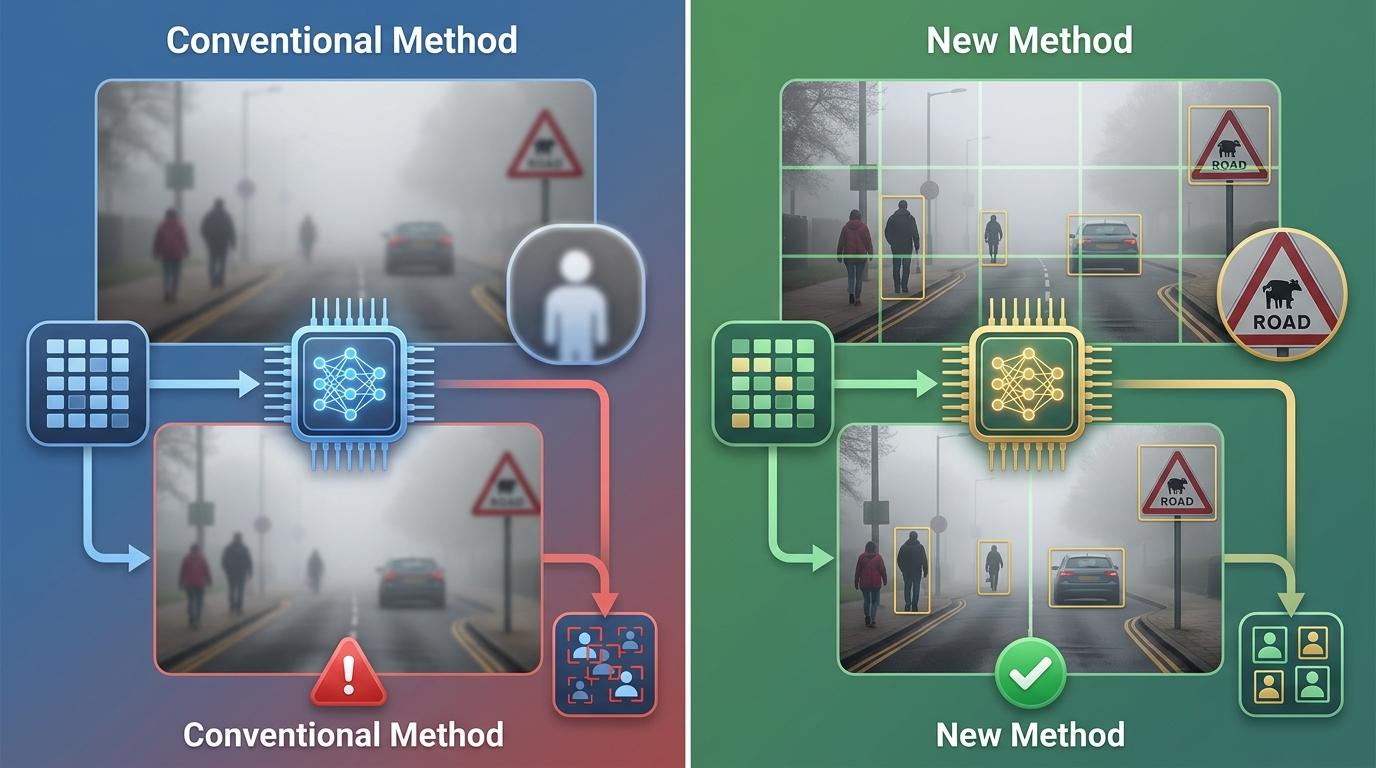
更糟的是,AI的检测模型认的不是「清晰的画面」,是「语义特征」。比如它靠「两条直立的腿+上半身轮廓」识别行人,而不是「一张清晰的人脸」。当修图算法把行人的腿磨成了和背景差不多的模糊块,哪怕整张图看起来更亮了,AI反而更找不到目标。有实验数据显示,用神经网络去雾后,目标检测的mAP(平均精度)反而下降了3.2个百分点——相当于每100个目标里多漏检3个。
这就像你给近视的人递了个放大镜,却没告诉他该看哪里——他可能把路边的石头看得清清楚楚,却错过了马路对面的行人。
新方法的核心,是让AI先搞懂「什么是看不见」——而这件事,语言比图像更擅长。
团队用到了OpenAI在2021年推出的CLIP模型,这个模型靠4亿对图文对训练出了一个本事:能把图像和语言映射到同一个语义空间里。比如它能准确判断,一张模糊的影子和「一张不包含行人的照片」这句话更像,还是和「一张包含行人的照片」更像。
具体操作起来像给每个目标做「语义体检」:针对图像里的每个疑似目标,生成一对互斥的语言提示——「一张包含行人的照片」和「一张不包含行人的照片」,然后用CLIP计算目标图像块和这两句话的相似度。如果目标和「不包含行人」的相似度更高,就说明这个目标的语义已经弱到快被雾气「吃掉」了,需要给它加个高权重,让AI在训练时重点盯着它学。
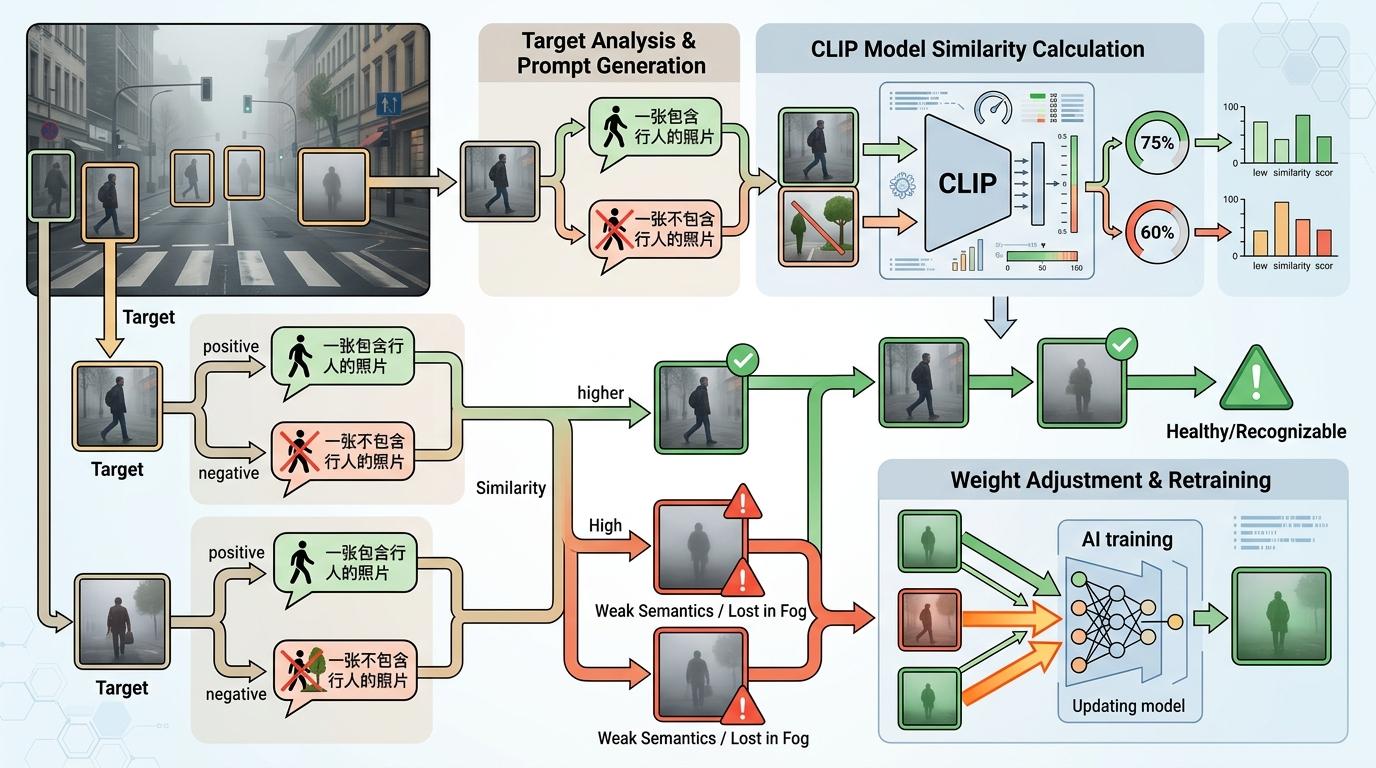
这个被称为AME(互斥近似)的权重计算方法,就像给AI配了个「视力表」:越模糊的目标,得分越高,训练时得到的关注就越多。而后续的FAME(微调互斥近似)机制,还能根据AI的学习进度动态调整权重——当AI已经能认出某个模糊目标了,就自动降低它的权重,避免过度训练导致的过拟合。
最终整合出的CLIP-CE损失函数,相当于给AI的训练过程装了个「导航」:不用先把路修平,直接告诉它哪里坑洼最多,该放慢脚步仔细看。
为了验证这个方法,团队专门造了个目前最大的合成雾天数据集HazyCOCO——61258张带雾的室外图像,比之前的同类数据集大5倍还多,而且用真实的深度数据生成雾气,比人工合成的更接近现实。
实验结果直接打脸了「先修图再检测」的传统思路:在HazyCOCO数据集上,新方法的mAP达到了44.92%,比用Focal Loss(专门针对难样本的损失函数)的传统方法高出5.25个百分点——相当于每100个模糊目标里,能多检出5个。在真实雾天的RTTS数据集上,新方法的mAP更是冲到了76.76%,比第二名高出6.56个百分点。
更关键的是通用性:不管是用经典的Faster R-CNN,还是基于Transformer的Deformable-DETR,加上这个CLIP-CE损失函数,性能都能稳定提升。甚至在低光照的Exdark数据集和水下的TrashCan数据集上,这个方法也能打败专门的图像增强算法——它本质上解决的不是「雾天」的问题,是「语义弱化」的问题,只要是目标特征被环境侵蚀的场景,它都能发挥作用。
当然,它也有局限:如果目标被雾气完全遮住,连CLIP都判断不出和「不包含目标」的区别,那这个方法也会失效。但在大多数真实的恶劣环境里,目标总还剩点语义尾巴——而这就足够让AI抓住了。
当我们习惯了用视觉的方法解决视觉的问题,这个研究像给所有人泼了盆冷水:AI需要的从来不是「更清晰的画面」,而是「更明确的语义」。就像在雾里开车,你不需要把整个世界都照亮,只需要看清前方的那一个人、那一辆车。
语言和视觉的融合,从来不是让AI学会「看图说话」这么简单——它是给AI打开了另一扇感知世界的门。当视觉信号失效时,语言能成为锚点;当图像模糊时,语义能成为灯塔。语义为锚,视觉为舟,AI才能在雾里航行。
未来或许我们不需要再纠结怎么给AI修图,而是要学会怎么和它对话——告诉它该看什么,而不是替它把世界变清晰。