对抗知识焦虑,从看懂这条开始
App 下载
一个词元统一两种视觉推理,效率翻5倍
词元机制|视觉推理|Meta团队|香港中文大学|ATLAS模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载词元机制|视觉推理|Meta团队|香港中文大学|ATLAS模型|多模态视觉|人工智能
做几何题时,你会在草稿纸上画辅助线、圈重点、标箭头——这些动作不是多余的,是帮你理清思路的关键。过去AI要完成同样的视觉推理,要么得生成整幅中间图像,要么得调用一堆外部工具,慢得像在翻一本厚重的词典。直到香港中文大学和Meta的团队拿出了ATLAS:只用一个普通的词元,就能让AI同时完成「明确的视觉操作」和「高效的隐式思考」,推理延迟直接从18秒压到3秒。这到底是怎么做到的?
在ATLAS出现之前,AI视觉推理有三条走不通的死胡同:
第一条是「统一模型」——让AI显式生成中间图像,比如画辅助线、标重点,思路直观但太费资源,生成一张中间图的算力够普通推理跑十次;第二条是「代理式推理」——让AI调用外部工具,比如专门的画线器、计数器,每一步都能追踪,但工具间的切换像在不同软件间来回切窗口,慢还容易出错;第三条是「隐式推理」——让AI在内部悄悄完成思考,不生成任何可见步骤,速度快但像个黑盒子,你永远不知道它是蒙对的还是真懂了。

这三个方案各有各的死穴:要么慢,要么复杂,要么不可信。AI要处理复杂的视觉推理,比如解几何题、分析多视角图像,总得在「效率」「可解释性」「成本」里三选二,直到ATLAS把这三个选项捏成了一个。
ATLAS的核心是「功能性词元」——这不是什么复杂的新模块,就是在AI的词表里加了5个简单的词:<|Shape|>(圈区域)、<|Line|>(画辅助线)、<|Arrow|>(标方向)、<|Text|>(加标注)、<|Manip|>(调图像)。
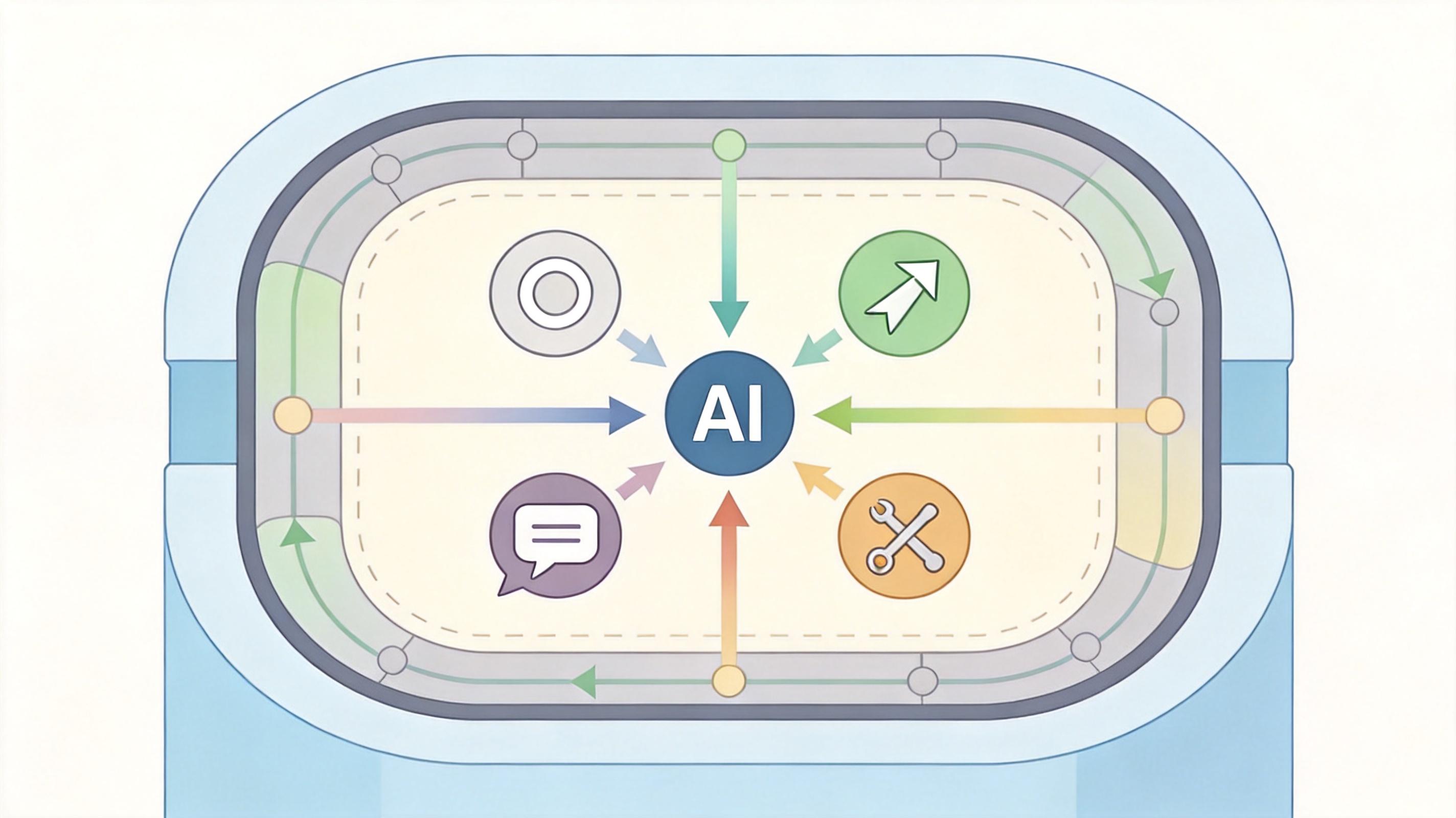
你可以把它想象成给AI的草稿纸加了快捷键:当AI需要圈出图像里的关键区域时,不用生成整幅标注图,只要输出<|Shape|>,它的内部就会自动激活对应的视觉操作,把注意力集中到目标区域;当需要画辅助线时,输出<|Line|>,内部就会完成几何关系的推导。这个词元既是AI告诉我们「我正在做什么」的操作指令,也是它在隐空间里完成思考的推理单元——一句话,它让AI的「操作」和「思考」变成了同一个动作。
更聪明的是,这些词元不需要额外的图像监督,就像普通的词一样,通过「预测下一个词」的标准训练就能学会。研究团队先在17.8万条视觉推理数据上做监督微调,教AI在合适的时机用这些词元;再用强化学习优化,答对题且合理用词元就给奖励,乱用词元或者输出太长就惩罚,避免AI为了刷奖励乱凑词。
但新问题又来了:在一整段推理里,功能性词元只占2%左右,大部分还是普通的文本词。用传统的强化学习训练时,奖励信号会被大量普通词稀释,就像在一大桶水里滴一滴墨水,关键词元根本学不到足够的信号——这就是「梯度稀释」问题。
团队专门设计了「隐锚定GRPO(LA-GRPO)」来解决这个问题:在训练时给功能性词元单独加一个「锚点」,如果某条推理答对了,而且某个词元起到了关键作用,就专门强化这个词元的生成概率。相当于老师改作业时,不仅看最终答案对不对,还会特意给那些关键的解题步骤打个五角星,告诉学生「这一步才是重点」。
实验结果很直接:在BLINK视觉推理基准上,基础模型的准确率只有22.8%,用了ATLAS-SFT后升到46%,加上LA-GRPO直接冲到51.3%;同时推理延迟从18.83秒降到3.8秒,显存占用也砍了近一半。更重要的是,注意力可视化显示,当AI输出<|Shape|>时,它的注意力真的会集中到要圈的区域,输出<|Line|>时会聚焦在几何关键点——这些词元不是摆样子的符号,是真的在帮AI思考。
我们总觉得AI要变聪明,就得堆参数、加模块、搞复杂的架构,但ATLAS给了一个反直觉的答案:有时候做减法反而更有效——把复杂的视觉操作压缩成一个词元,把割裂的操作和思考合并成一个动作,把冗余的流程砍掉只留最核心的逻辑。
一个词元即是操作,也是思考。这句话不仅是ATLAS的核心,更像是给多模态AI指了一条新的路:未来的AI不需要像人类一样「先想再做」,它可以把「想」和「做」变成同一个瞬间。当我们还在纠结AI的思考能不能被理解时,ATLAS已经用一个简单的词元,让AI的思考本身就成了可以被看见的操作。