对抗知识焦虑,从看懂这条开始
App 下载
大模型卡壳在数据:北大团队用流水线破局
模型训练数据|Hugging Face|数据治理|DataFlow工具|北京大学DCAI团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型训练数据|Hugging Face|数据治理|DataFlow工具|北京大学DCAI团队|大语言模型|人工智能
当大模型已经能自己写代码、解高数题,像自动驾驶一样跑通推理链时,给它喂数据的环节却还停留在手工坊时代——数据科学家们靠零散的Python脚本、东拼西凑的正则表达式,在TB级的文本里摸黑找可用的训练素材。等模型训练几周后才发现数据里藏着偏见,又得推倒重来,试错成本高到离谱。
就是这个让全球开发者头疼的痛点,被北京大学DCAI团队的DataFlow精准命中。这份技术报告刚发布就登顶Hugging Face每日论文榜首,开源仓库星标迅速破3000。为什么一套数据治理工具能引发这么大的共鸣?答案藏在大模型研发的一个关键拐点里。
2026年的大模型行业,已经走到了「堆参数边际效益递减」的临界点——OpenAI、Google的新一代模型,把参数和训练数据量翻了倍,性能提升却连GPT-3到GPT-4的十分之一都不到。行业共识悄悄转向了「数据中心范式」:决定模型上限的不再是算力,而是数据的「语义密度」——也就是每一条训练数据里包含的有效知识量。
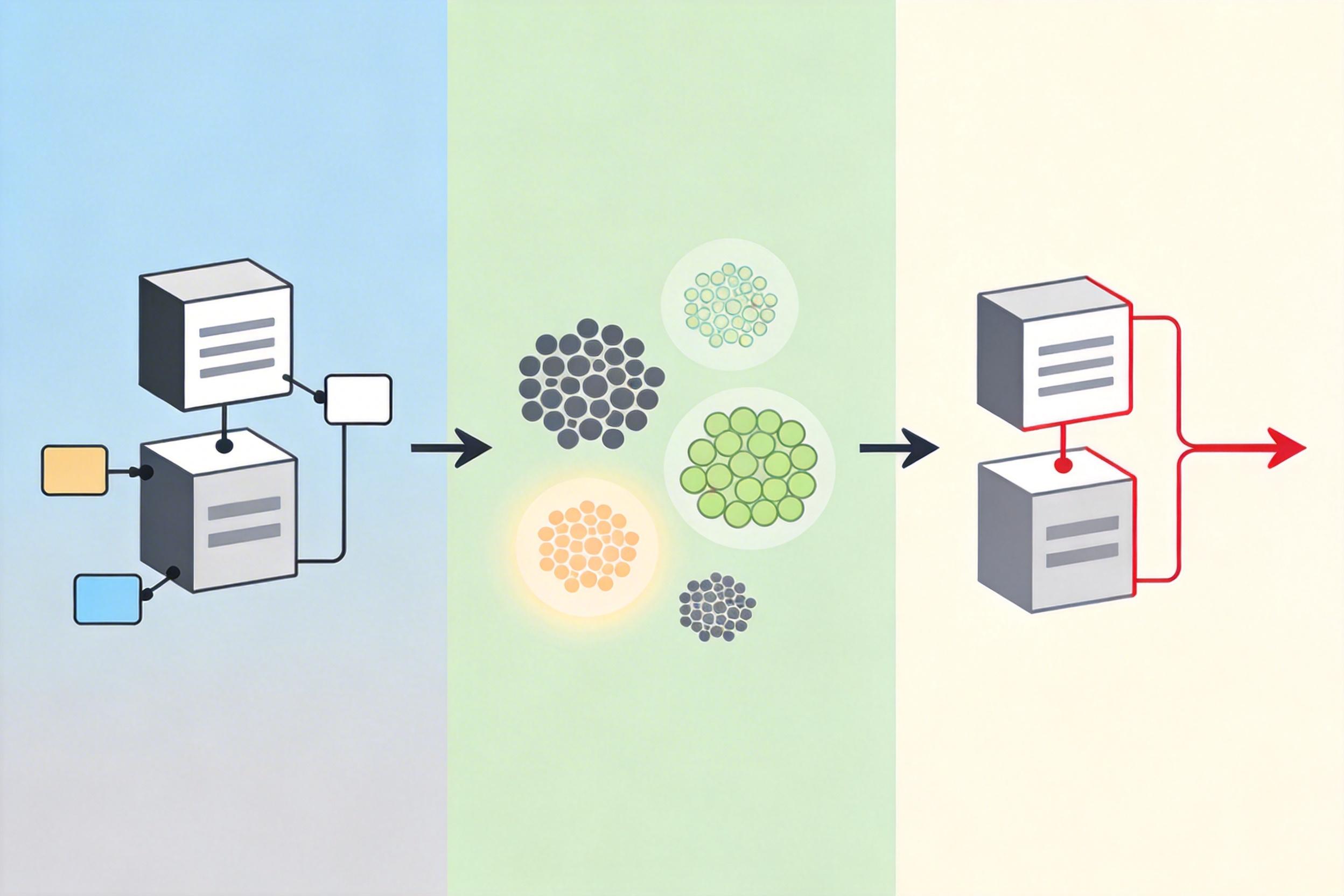
但现实是,数据准备的效率远远跟不上模型的进化。传统的ETL(抽取、转换、加载)工具靠确定性规则清洗数据,比如把日期统一格式、删除重复值,但大模型需要的是高维语义判断——比如筛选能训练数学推理能力的优质习题,或者生成符合代码规范的训练样本,这必须让模型自己参与进来评估、过滤甚至生成数据,也就是「模型在环」。
之前的零散脚本根本玩不转这套逻辑:调用大模型的代码散落在各个文件里,不同项目的处理逻辑没法复用,数据在流水线里变成了黑盒——你不知道哪一步出了问题,只能等模型训练出结果才发现数据质量不行。DataFlow就是瞄准这个「模型自动驾驶,数据手工推车」的矛盾,打造了一套像PyTorch一样的数据流编程框架。
DataFlow的核心逻辑,是把数据处理的每一个环节都拆成了标准化的「算子」——就像乐高积木,你可以用近200个内置算子,像搭积木一样拼出从原始文本到高质量训练数据的完整流水线。
比如你要做数学推理数据的清洗,不用自己写正则表达式筛选题目,直接用「数学题质量评估」算子,它会自动调用大模型去判断题目是否符合难度要求、答案是否正确;要生成代码训练数据,就用「代码逻辑验证」算子,自动检测代码是否能运行、是否符合规范。这些算子都和底层存储解耦,不管你的数据存在本地JSONL里,还是分布式数据库里,算子都能直接调用,不用改一行代码。
更关键的是它解决了「黑盒」问题。DataFlow的WebUI支持拖拉拽编排流水线,你能实时看到每一步处理后的中间结果——比如用「文本去重」算子后,剩下了多少条有效数据,有没有误删重要内容;还能实时监控处理进度,哪一步卡住了一目了然。甚至它还能像PyTorch一样做静态检查,在运行流水线前就告诉你哪个环节字段缺失、类型不对,把错误扼杀在摇篮里。
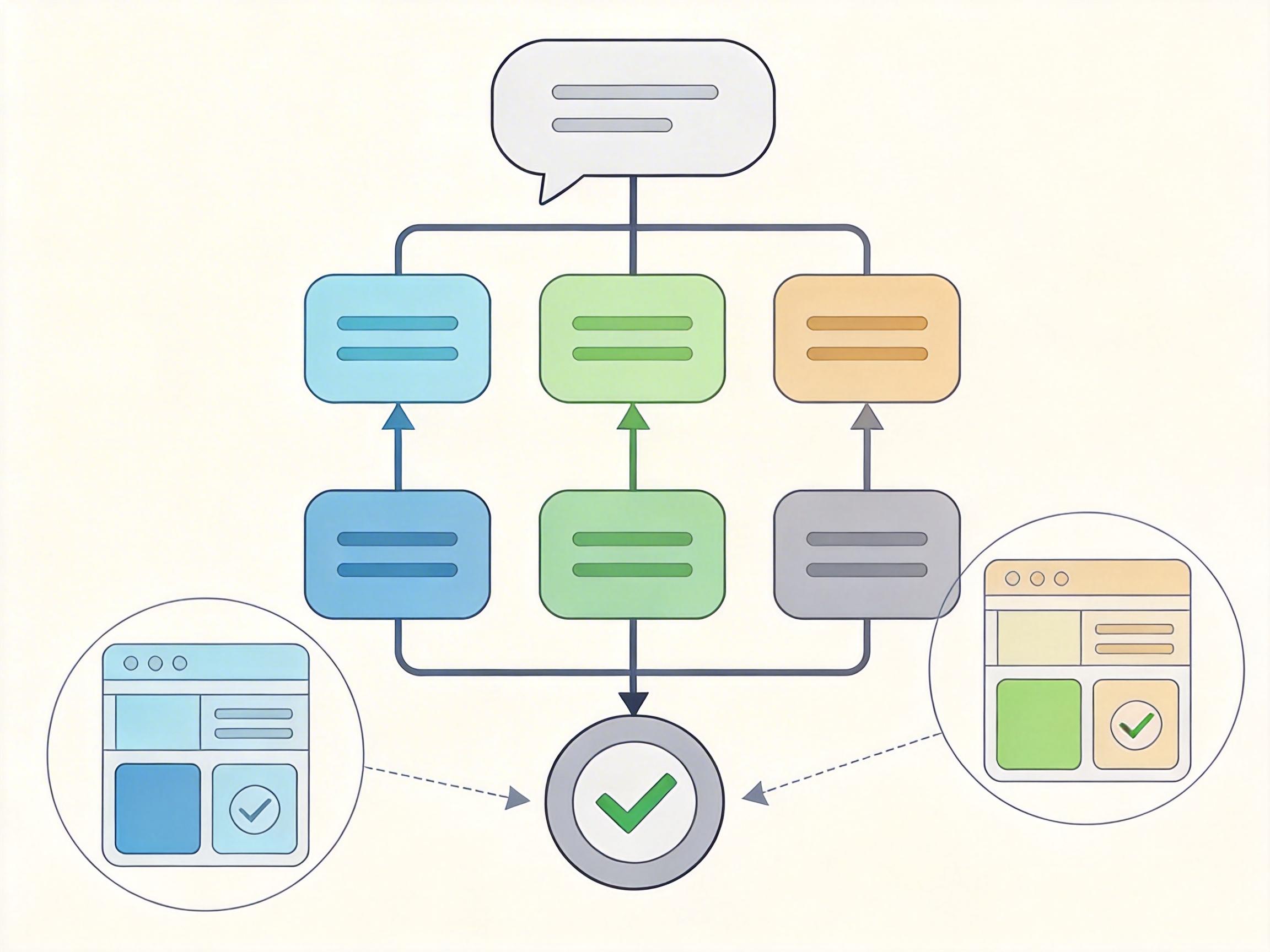
最让人惊喜的是DataFlow-Agent:你只要说一句「帮我生成高质量Python算法题数据」,它会自动拆解需求,从算子库里挑出合适的模块,拼出完整的流水线,还会自动验证结果是否符合要求。这相当于把数据工程从「写代码实现」,变成了「用自然语言定义逻辑」,门槛直接拉到了普通产品经理也能上手的程度。
DataFlow的威力,在实验数据里体现得淋漓尽致。用它生成的10K多领域合成样本微调模型,数学和代码领域的性能居然接近了官方用百万级指令数据训练的版本,而且通用知识能力没有退化。
在Text-to-SQL这个大模型落地的关键场景里,效果更惊人:用DataFlow生成的90K合成数据训练Qwen2.5-Coder-7B,Spider-dev基准的执行准确率从73.4%涨到了82.0%,BIRD-dev从50.9%提升到59.2%,在医疗场景的EHRSQL基准上,准确率更是从24.3%飙升到56.1%——涨幅超过30%。更夸张的是,DataFlow-50K的表现已经优于同规模的SynSQL,而90K的效果几乎追平了SynSQL的2.5M样本。
这就是小规模高质量数据的「杠杆效应」:之前大家都在比谁的数据多,现在才发现,只要数据的语义密度足够高,10条优质数据能顶得上1000条垃圾数据。不过DataFlow的自动化也不是万能的——在处理极端模糊的自然语言指令时,生成的代码一致性得分只有0.23,说明在最复杂的场景里,还是需要人工介入调整。
当大模型的「军备竞赛」告一段落,行业终于开始回头补数据治理的课。DataFlow的走红,本质上是开发者们对「工业级数据基础设施」的集体呼唤——就像当年PyTorch把深度学习从实验室带到了工业界,DataFlow正在把大模型的数据工程从「手工坊」推进到「流水线时代」。
未来的AI开发者,可能不用再精通复杂的模型架构,而是要学会用DataFlow这样的工具,从海量数据里淘出真正有价值的「金矿」。毕竟,模型只是容器,数据才是里面的燃料。数据的质量,终将定义AI的高度。