对抗知识焦虑,从看懂这条开始
App 下载
AI Agent不用从零搭,模块化拼出生产级系统
自动化操作|生产级系统|工具接入|模块化组件|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动化操作|生产级系统|工具接入|模块化组件|AI智能体|人工智能
当你让AI写一份行业报告,它能输出逻辑通顺的文字;但你让它直接调用数据库拉取最新数据、打开分析软件生成可视化图表、甚至自动发邮件给相关同事时,它大概率会卡住——要么找不到接口,要么权限不够,要么干脆不知道怎么操作。这正是当前AI Agent的普遍困境:能“思考”,却难“行动”;能聊一轮,却记不住你的长期需求。而2026年的AI圈已经找到破局的钥匙:不用从零搭建复杂系统,像拼乐高一样用模块化组件,就能快速组装出能干活、有记忆的生产级AI Agent。
你可以把AI Agent的“工具接入”想象成给手机装APP——没有这些接口,它就只是个能看不能用的模型外壳。过去要让AI操控真实软件,要么得等厂商开放API,要么得花大成本自己开发接口,门槛高到让很多团队望而却步。
现在有了更聪明的解法:把命令行(CLI)变成AI和真实世界的“通用翻译器”。比如香港大学团队开发的CLI-Anything,能把Blender、GIMP这类专业软件自动转换成AI能直接调用的命令行工具——就像给每个软件套上了一层AI能读懂的“操作手册”,不需要改一行原代码,就能让AI操控软件后台渲染、批量处理图片。还有OpenCLI,能直接复用你浏览器里的登录状态,让AI不用额外输入账号密码,就能操作你已经登录的社交媒体、办公平台,把接入成本降到几乎为零。
但真实的技术逻辑比这更精确:这类工具本质是在AI和软件之间搭建了一个“翻译层”,把AI的自然语言指令转换成标准化的机器能执行的命令,同时解决了权限验证、接口兼容等问题。这一步突破,让AI终于从“纸上谈兵”的参谋,变成了能动手干活的执行者。
你有没有过这样的经历:和AI聊了半小时项目细节,关掉对话再打开,它又要你从头说起?这是因为绝大多数AI只有“工作记忆”——就像电脑的临时缓存,对话结束就清空。但要让AI跟进一个持续半年的项目、记住你所有的偏好习惯,就必须给它装上“长期记忆”。
Mem0就是这样一个“记忆外挂”:它用向量数据库存储AI的对话历史和关键信息,用图数据库梳理信息之间的关联,还会像人脑一样自动“遗忘”过时信息、强化重要记忆。比如你让它跟进一个项目,它会记住三个月前你提过的预算上限、上周调整的核心需求,甚至能关联到你去年做过的类似项目的经验。实测显示,它比OpenAI自带的记忆功能准确率高26%,还能节省90%的Token成本。
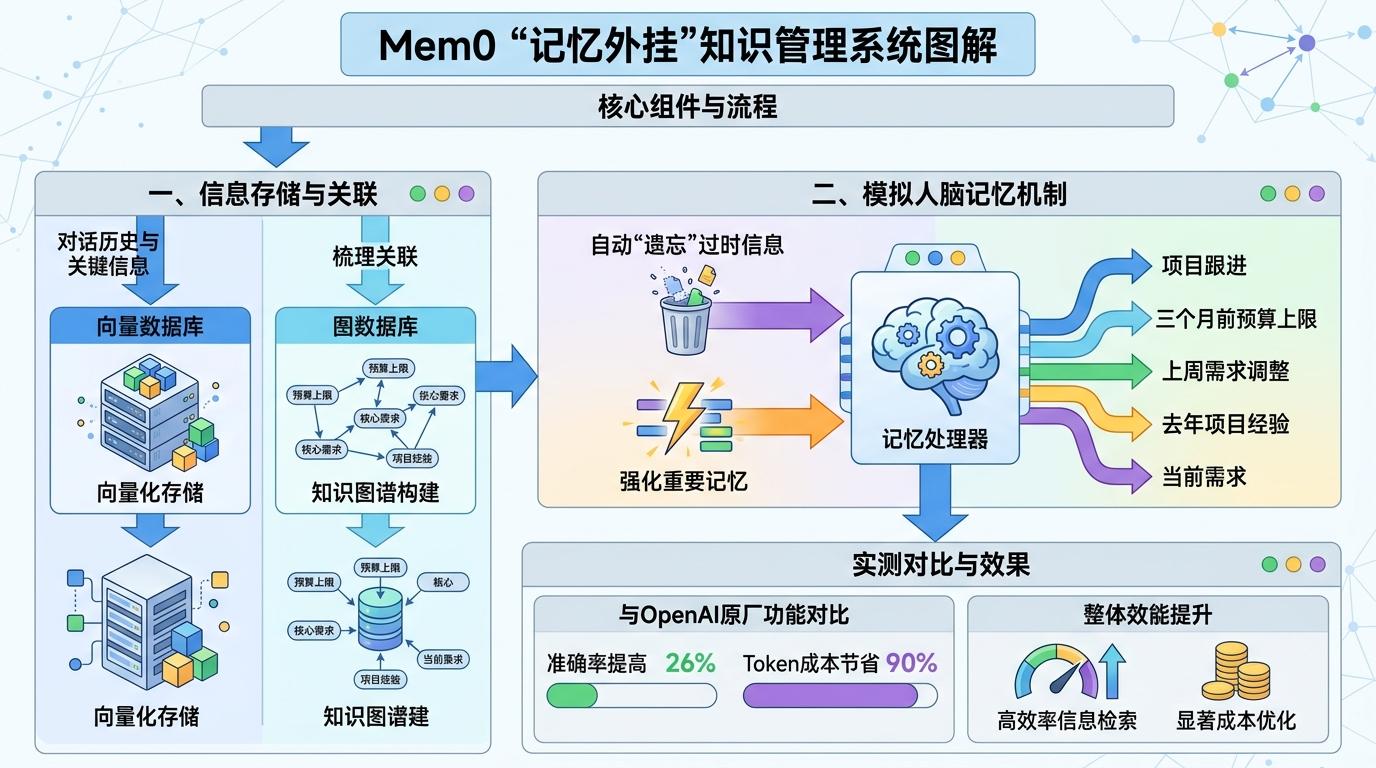
更进阶的是企业级的MemoryLake,它提出了“记忆护照”的概念——AI的记忆不再绑定某个平台,就像你的护照能在不同国家使用一样,AI的记忆可以在不同系统之间迁移。比如你从A平台换到B平台,不用再重新给AI交代一遍所有偏好,它的“记忆护照”会自动同步过去。不过这一技术目前还在早期阶段,如何保证记忆的隐私安全、避免信息冲突,都是待解决的难题。
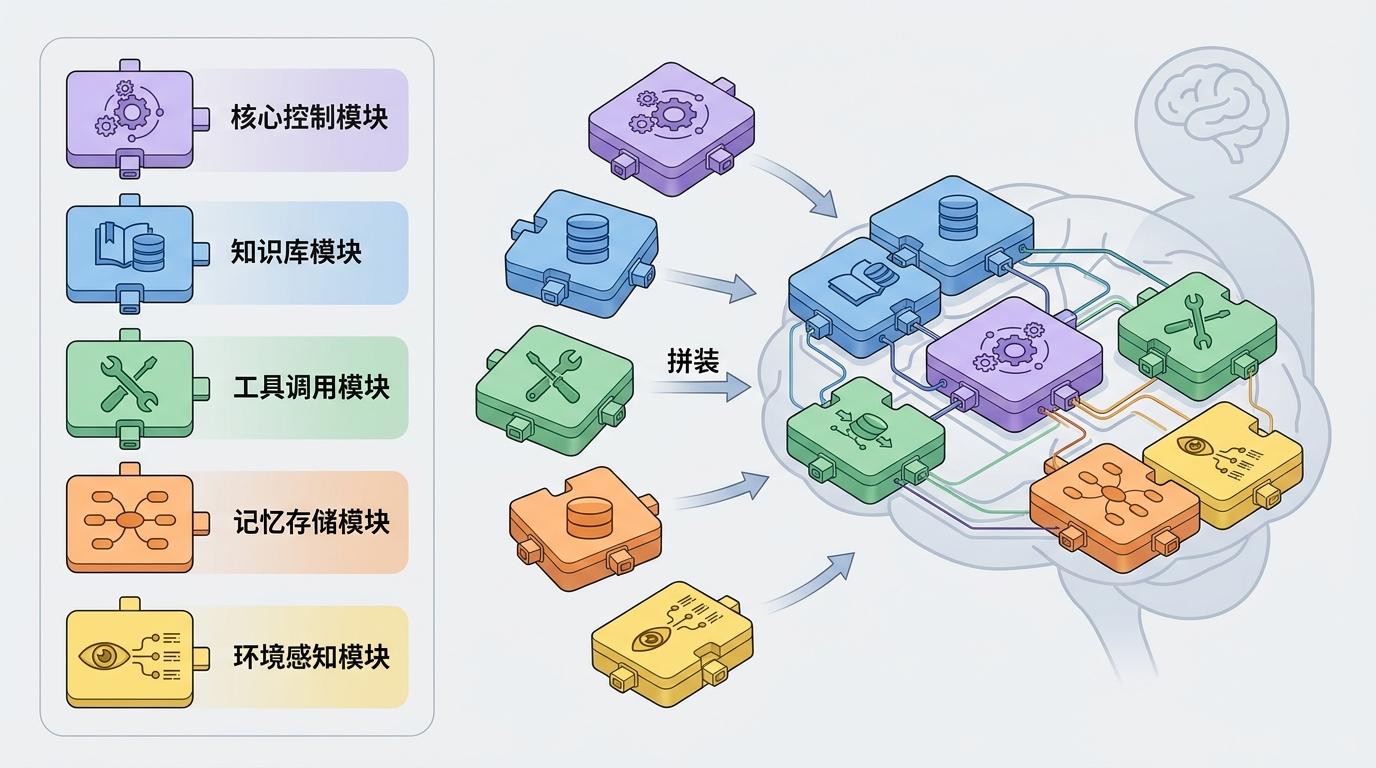
很多人以为模块化就是随便找几个开源工具拼在一起,其实不然。Harness架构的核心是“在正确的位置用正确的组件”——每个模块都有明确的分工,选对了能事半功倍,选错了反而会拖慢整个系统。
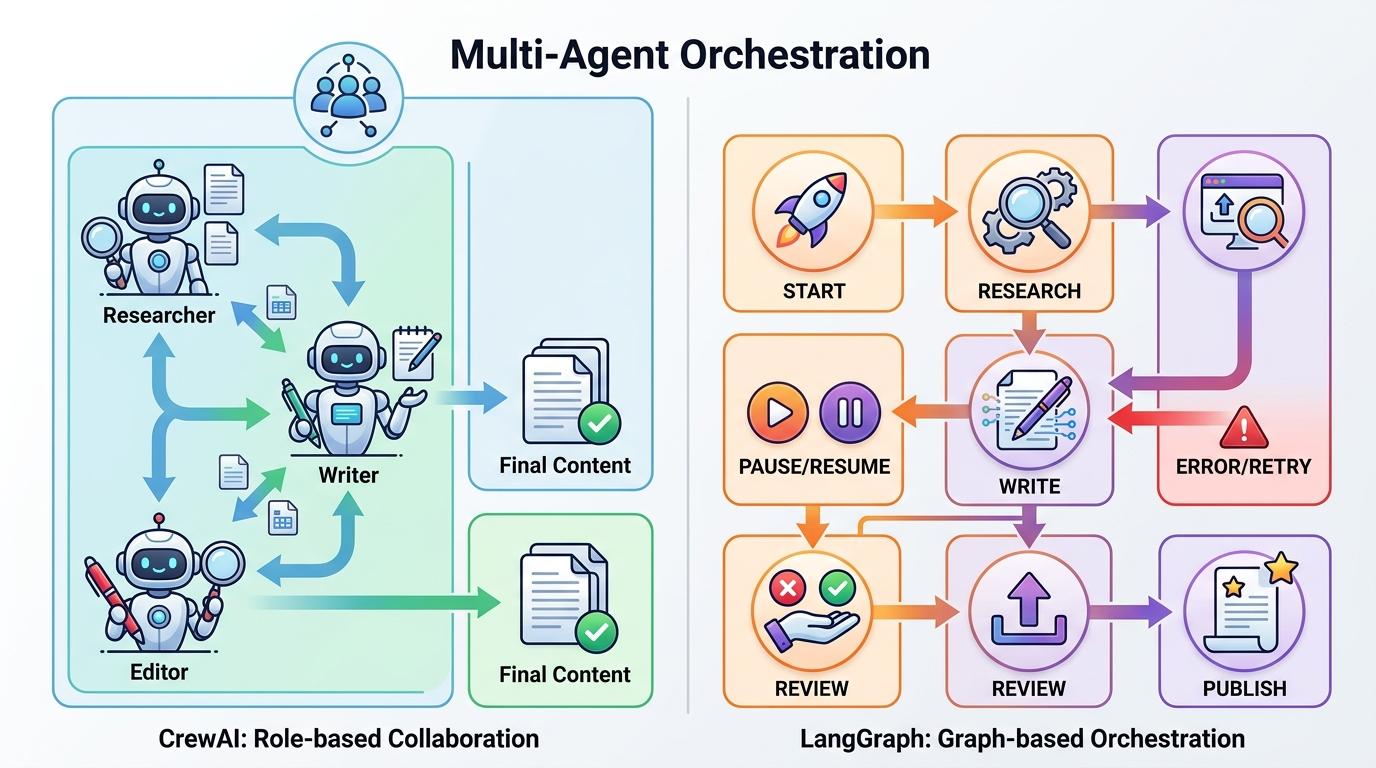
比如多Agent编排,如果你要做一个内容生产流水线,让AI分别扮演研究员、撰稿人、编辑,那CrewAI的“角色分工”模式最适合,它能让不同AI像团队一样协作;但如果你要做一个需要精确控制每一步流程、支持暂停恢复的长期任务,LangGraph的“图结构编排”更靠谱,每一个节点、每一条数据流向都在你的掌控之中。
还有容易被忽略的可观测性模块——就像给AI装了个“黑匣子记录仪”,能记录AI的每一步决策、每一次工具调用。比如Opik能精确统计每个AI任务的Token消耗,帮你把运营成本降下来;Langfuse能把AI的推理过程可视化,让你一眼看到它是怎么得出某个结论的,方便调试和优化。
但模块化也有它的局限:目前各个模块之间的标准还不统一,不同开源工具之间可能存在兼容性问题;而且对于超大规模的复杂任务,如何协调多个模块之间的协作,仍然是个挑战。
当我们谈论AI Agent的未来时,其实我们谈论的是“如何让AI真正融入工作流”。过去我们总想着要开发更强大的模型,现在才发现,把现有模型的能力用起来,反而更重要。
模块化架构就像是给AI Agent搭好了骨架,每个组件都是一块精心打磨的骨头,你不需要自己从头造骨头,只需要根据需求把它们拼起来就行。这不仅降低了AI Agent的开发门槛,也让小团队有了和大厂同台竞技的可能。
模块化不是终点,是让AI落地的起点。 未来的AI Agent,会像我们身边的同事一样,能干活、有记忆、懂协作,而这一切,从一块合适的“积木”开始。