
8 天前
8 天前
给一张静态蛋糕图,要让它掉在地上Q弹晃动——放在以前,得花几小时逐帧调参数,让模型搞懂‘蛋糕不是石头’。现在,北京理工大学联合团队的PhysGM模型,只需要1分钟,就能从单张图片生成完全符合物理规律的4D动态视频:蛋糕会晃、沙堆会散、石头会硬邦邦砸地。它跳过了传统模型耗时的逐场景优化,直接把大语言模型里的偏好优化思路搬进了物理仿真。这背后到底藏着什么门道?
过去要让AI生成符合物理规律的动态,核心难题是‘猜参数’:给一张图片,模型得先重建3D结构,再反复试错调整杨氏模量、泊松比这些物理参数,靠分数蒸馏采样(SDS)一点点逼近真实效果,光优化一个场景就得几小时。PhysGM把这个逻辑彻底反过来了。
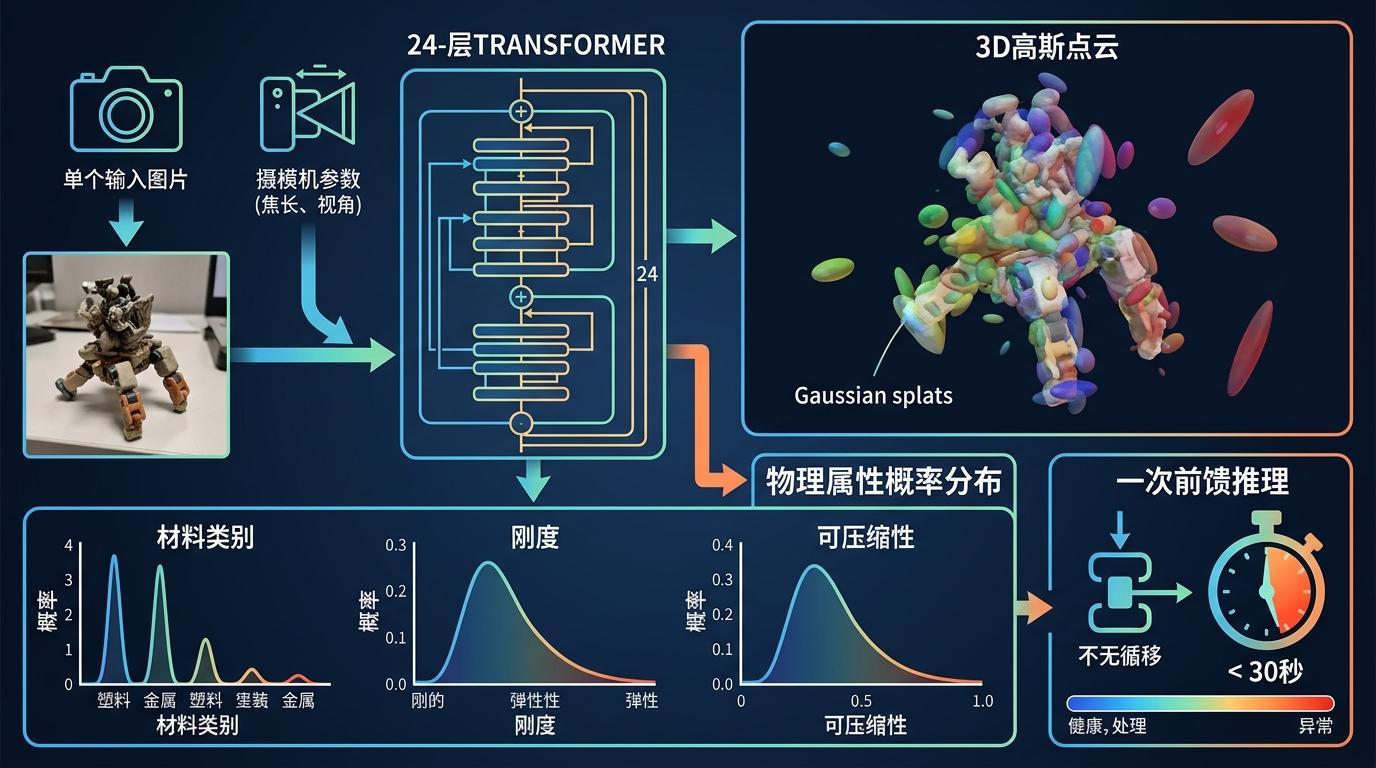
它用一个24层Transformer做核心,输入单张图片和相机参数后,同时输出两个关键结果:一个是3D高斯点云——用一堆带颜色、位置和形状的‘光斑’快速重建物体的3D结构;另一个是物理属性的概率分布,直接给出材料类别、刚度和可压缩性的可能范围。整个过程是一次前馈推理,不用迭代,30秒内就能拿到所有参数。
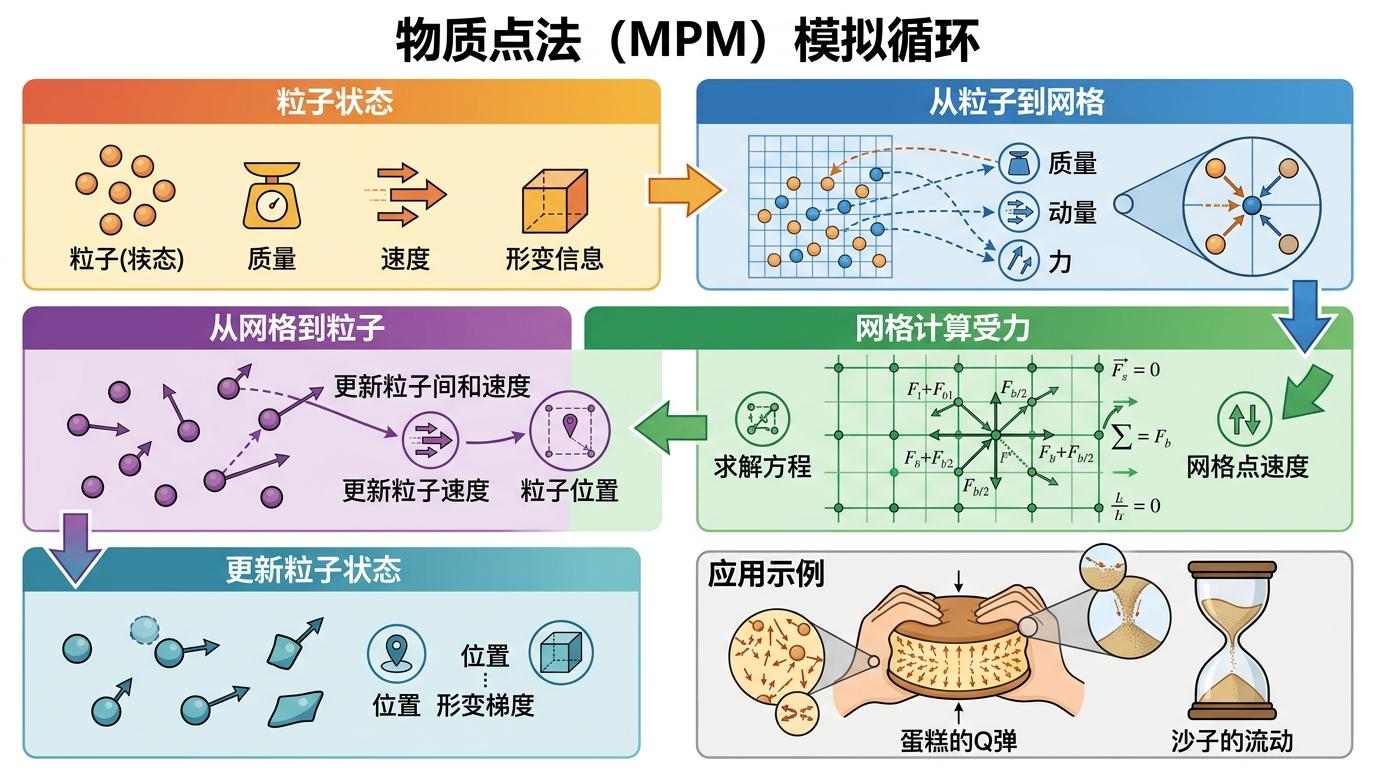
接下来是**物质点法(MPM)**的舞台——你可以把它想象成给每个高斯点安上‘物理大脑’:每个点携带质量、速度和形变信息,先把这些信息映射到背景网格上计算受力,再把网格的受力结果还给每个点更新状态。蛋糕的Q弹、沙子的流动,全靠这套粒子-网格的双向传递实现。
光有参数还不够,怎么保证生成的动态符合人类对‘真实’的感知?PhysGM最巧妙的一步,是把大语言模型里的**直接偏好优化(DPO)**搬进了物理生成领域——这相当于给模型装了个‘自动评分器’。
它会从物理参数的概率分布里采样好几组可能,用MPM分别生成动态视频,再用SAM-2分割物体、CoTracker-3提取运动轨迹,把这些生成视频和真实物理视频比‘相似度’:轨迹越贴合、形变越自然,就标记为‘胜者’,反之就是‘败者’。模型会在训练中不断强化对‘胜者’参数的偏好,慢慢学会生成更符合人类直觉的物理动态。
这个过程完全不用可微分的物理引擎——传统方法要让物理引擎支持反向传播,得把整个仿真过程拆成可求导的数学模块,耗时又复杂。DPO跳过了这一步,用‘选优’代替‘调参’,不仅训练效率提升了一个数量级,还让物理动态的真实感直接跳了级:在用户测试里,带DPO的PhysGM生成结果被选中的概率是传统方法的3倍多。
有意思的是,团队还专门建了个5万规模的PhysAssets数据集当‘练手素材’——用多模态大模型给3D资产自动标注物理属性,再生成对应的仿真视频。相当于给模型喂了5万个‘物体-物理-动态’的标准答案,让它先学会‘看东西猜物理’,再用DPO打磨细节。
PhysGM把物理驱动的4D生成从‘小时级’拉到了‘分钟级’,但它还不是完美的。
首先是MPM的计算瓶颈:虽然参数预测快,但要做高分辨率的复杂仿真——比如百万粒子级的沙堆流动——还是得消耗不少算力,离实时生成还有距离。其次是‘仿真到现实’的 gap:模型学的是数据集里的物理规律,遇到真实世界里的极端情况,比如冻硬的沙堆、半融化的巧克力,可能还是会‘摸不准’。
更关键的是,它目前还只能处理单物体或简单多物体场景,要是给一张满是人和家具的客厅照片,模型还没法准确区分每个物体的物理属性,更别说模拟它们之间的复杂碰撞了。不过这些问题,反而更能体现PhysGM的价值:它给物理生成领域搭了个‘快推理+偏好调优’的框架,剩下的就是往里面填更精细的物理模型和更丰富的训练数据。
当我们谈论AI‘懂物理’,本质上是在让虚拟世界和现实世界的规则对齐。以前要实现这种对齐,得靠工程师逐场景‘教’;现在PhysGM证明,AI可以通过数据和偏好学习,直接‘悟’到物理规律。
这不仅是速度的提升,更是思路的转变——从‘让AI适应物理引擎’,变成‘让物理引擎适应AI的学习方式’。未来,也许我们给一张设计图,AI就能直接生成符合力学规律的动态仿真;给一张老照片,它就能还原出当年风吹过屋檐、树叶落在地上的真实动态。
虚拟与现实的边界,正在被‘懂物理’的AI慢慢揉碎。
点击充电,成为大圆镜下一个视频选题!