对抗知识焦虑,从看懂这条开始
App 下载
AI终于能像人一样,边写教程边配插图了
同步生成|教程插图|原生统一架构|AI图文生成|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载同步生成|教程插图|原生统一架构|AI图文生成|多模态视觉|人工智能
你有没有过这种经历:用AI生成煎牛排教程,前两步还是油花四溅的菲力,第三步突然变成了带骨西冷;想做份太阳系图解,文字说明里的木星是气态巨行星,配图却画成了岩石质地。过去的AI图文工具,永远是文字归文字、图片归图片,像两个各说各话的搭档——直到最近,一套新架构打破了这个僵局。它让AI第一次像人一样,边构思文字逻辑,边同步画出对应画面,甚至能让牛排从生到熟保持同一块纹理,让太阳系的每颗行星都对应着准确的轨道说明。这不是简单的功能升级,而是多模态AI从「模块拼装」到「原生统一」的跨越。
你可以把传统多模态AI想象成一家分工僵化的公司:视觉部门负责「看」,把图片压缩成一堆抽象的语义标签;生成部门负责「画」,拿着这些标签去数据库里拼贴像素。两个部门之间靠一堆适配器传消息,信息在传递中不断损耗——要么为了保语义丢了像素细节,要么为了画得逼真,把文字里的逻辑丢得一干二净。
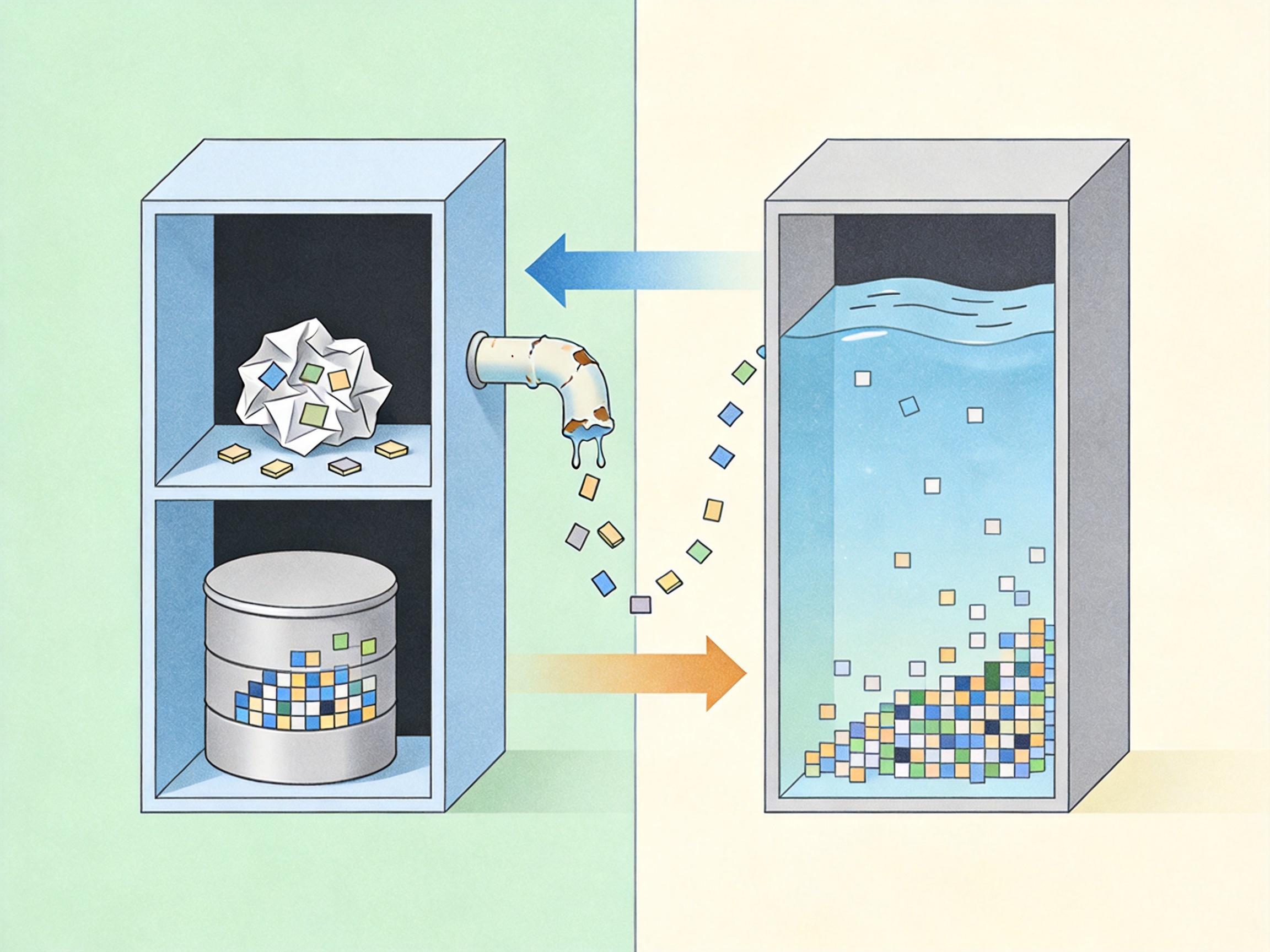
比如你要做一份带步骤的红烧肉教程,传统模型得先调用文本生成模块写出步骤,再把每一步的关键词单独喂给生图模型,最后手动把文字和图片拼在一起。中间只要有一个关键词传错,第三步的「冰糖炒色」就可能变成「白糖炒色」,配图里的冰糖也会变成白糖。更麻烦的是,每调用一次模块就要消耗一次算力,生成效率低不说,还很难保证角色和场景的连贯性。
这种「分裂」的架构,让AI在处理信息图、文字密集排版、多步骤教程这些需要图文深度配合的任务时,总是力不从心。直到NEO-unify架构出现,才把这两个部门彻底合并成了一个团队。
NEO-unify的核心逻辑很简单:拆掉视觉编码器和变分自编码器这两个中间部门,让AI直接用像素思考。
第一步,它用一个近似无损的视觉接口,把图片的输入和输出统一成同一种「视觉token」——就像把所有图片都翻译成了AI能直接读懂的通用语言,不用再经过压缩和解压缩的损耗。第二步,它用混合专家Transformer做主干,让理解和生成任务共享同一套底层神经网络:文本走自回归注意力,保证语言逻辑的连贯性;视觉走双向注意力,捕获图像的全局空间依赖。第三步,文本用自回归交叉熵目标训练,视觉用像素流匹配目标训练,两套任务在同一个框架里协同优化,就像同一个团队里的成员,既能写方案又能做设计,还能随时沟通调整。
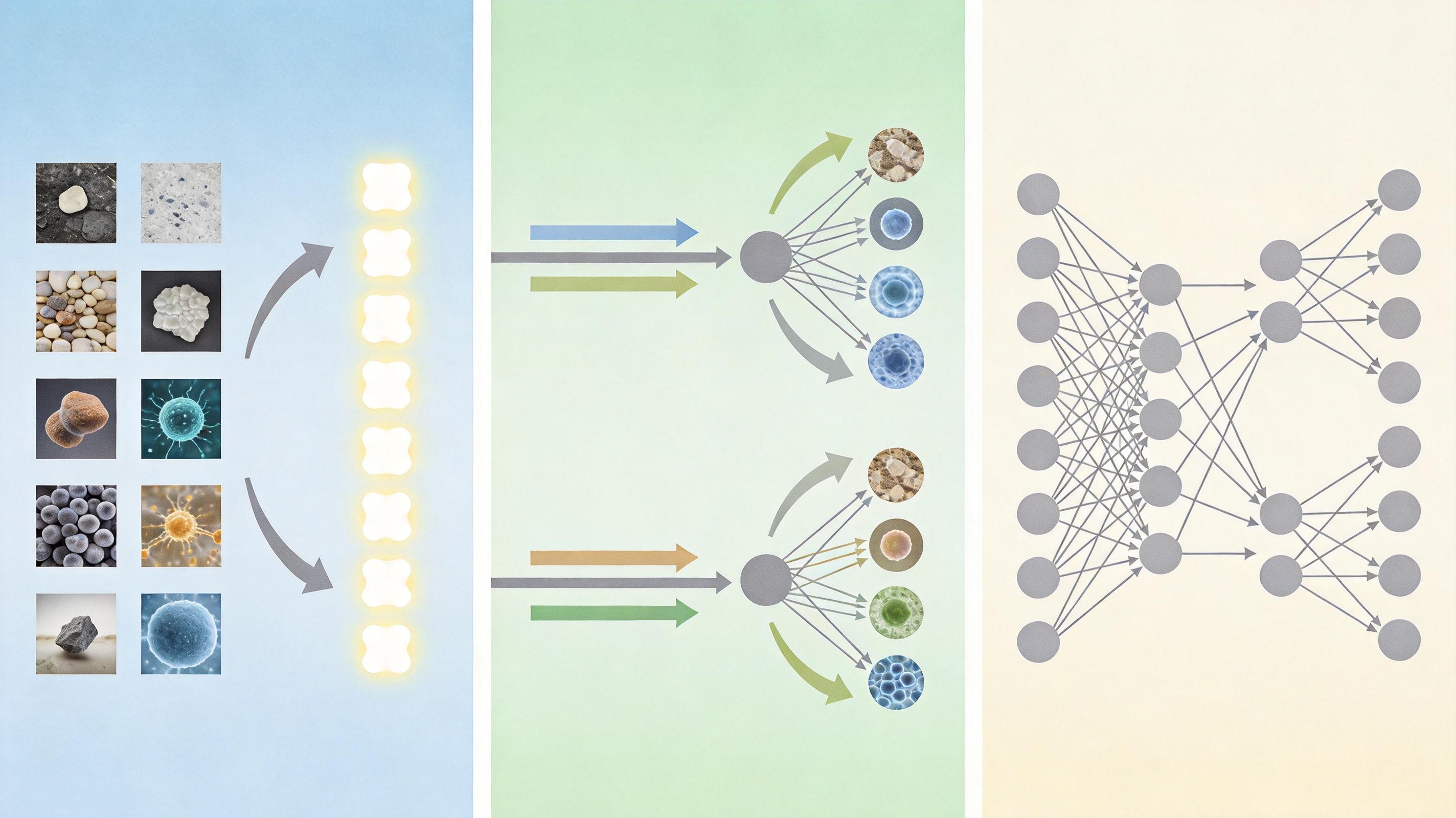
最关键的是,这套架构让文字和图像共享同一个上下文空间。当AI生成「煎牛排教程」时,它不用先写完所有文字再去生图,而是在构思「沥干水分」这个步骤的同时,就同步画出带着血水的生牛排;想到「煎至两面金黄」时,牛排的纹理和油花也会跟着同步变化。整个过程就像人在写教程时随手画插图,文字和图像从一开始就是一个有机整体,而不是事后拼接的两张皮。
这套架构带来的改变是直观的:在信息图、文字密集排版这些过去的AI生图硬骨头任务上,基于NEO-unify的模型已经能和顶尖闭源模型比肩。更重要的是,它的训练数据效率极高——只用3.9亿图文对,就达到了同类模型用数十亿数据才有的效果。端到端生成一张2048×2048的高分辨率图像,只需要9秒。
当然,它也有自己的局限:目前上下文最长支持32K token,复杂场景里的人物细节还不够稳定,长文本渲染偶尔会出现排版错误。但这些局限都被标注为「持续改进中」——毕竟,它打开的是一扇全新的门。
现在,你可以用它直接生成带准确轨道的太阳系图解,每颗行星都配着对应的属性说明;可以生成从轮廓到细节的完整绘画流程,让AI一步步教你画钢铁侠;甚至可以把自己的简历信息喂给它,直接生成一张排版精美的手绘风格海报。这些过去需要专业设计师或者多个工具配合才能完成的任务,现在一个模型就能搞定。
当我们谈论AI的多模态能力时,总是在说「理解」和「生成」,但很少有人关注「统一」——统一的思考逻辑,统一的上下文空间,统一的任务协同。NEO-unify架构的意义,就在于它让AI第一次拥有了这种「统一感」。
它不再是一个只会拼接模块的工具,而是一个能像人一样,用连贯的逻辑处理图文信息的「创作者」。这种变化,不仅会改变我们做设计、写教程、做科普的方式,更会为未来的具身智能打下基础——当机器人能同时「看」懂环境、「想」清逻辑、「做」出动作时,它的每一个决策,都会像我们写教程配插图一样,连贯而统一。
统一不是融合,而是共生。