对抗知识焦虑,从看懂这条开始
App 下载
仓库机器人不撞货架的秘密:离线多智能体协作突破
郭裕兰团队|MangoBench|离线多智能体强化学习|仓库机器人|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载郭裕兰团队|MangoBench|离线多智能体强化学习|仓库机器人|AI智能体|人工智能
电商大促的仓库里,上百台机器人在货架间穿梭、分拣、交接,全程没有碰撞;未来的城市道路上,自动驾驶车队像鱼群一样默契变道、避让,没有拥堵。这些场景离我们越来越近,但你可能不知道——让它们学会协作的最大难题,不是「怎么干活」,而是「不能试错」。撞一次货架、错一次变道,代价都是真金白银甚至生命。于是科学家们转向了「离线多智能体强化学习」:用已有的历史数据训练协作策略,而非让机器人在现实中反复试错。但这个领域一直卡在一个瓶颈:一到复杂任务,模型就集体「失智」。直到中山大学郭裕兰团队的MangoBench出现,才撕开了一道口子。
你可以把多智能体协作的训练想象成一群人搭积木:如果每次搭完只有「成功」或「失败」两个反馈,没人知道是哪块积木搭错了——这就是「奖励稀疏」问题。在现实任务中,机器人可能要做上百个动作才能拿到一次「完成任务」的奖励,根本不知道哪一步是对的。
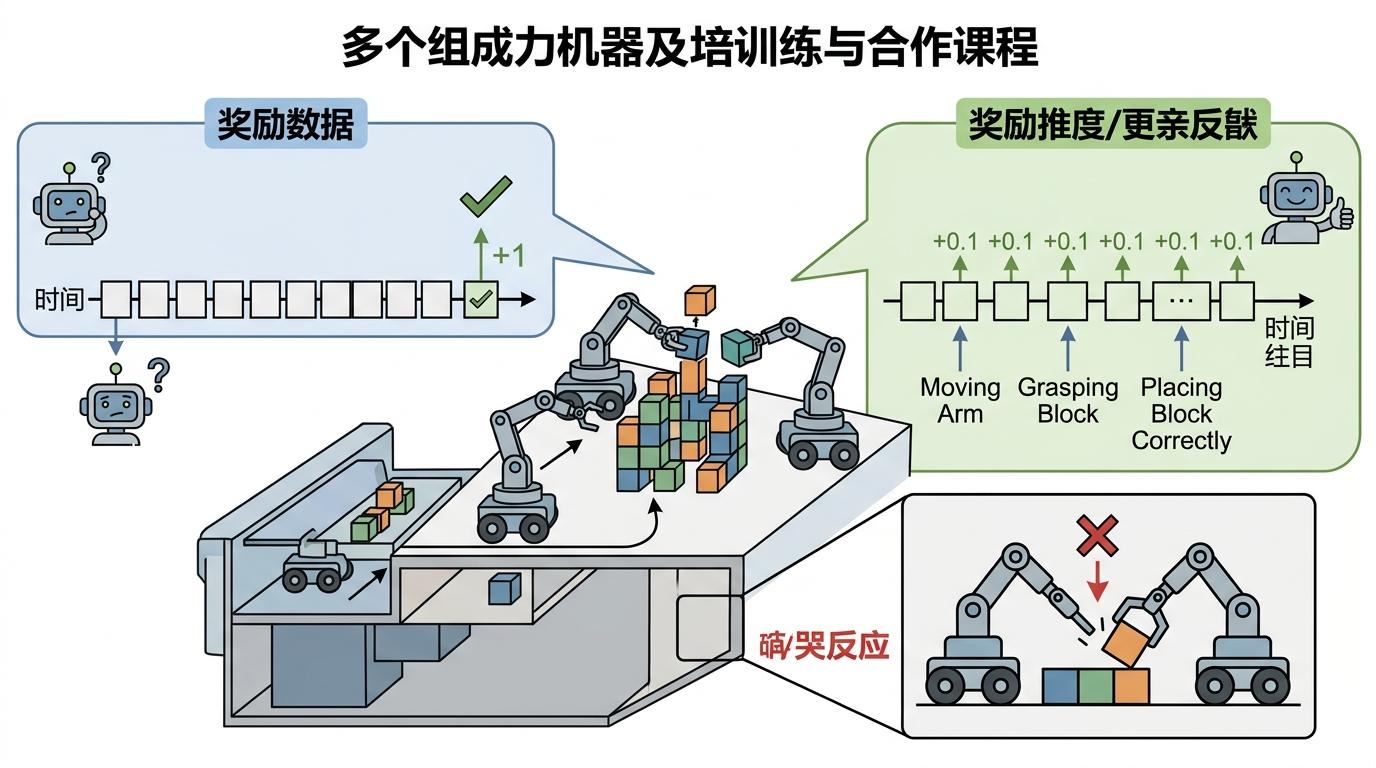
更麻烦的是「责任分配」:积木搭成了,到底是张三放的那块关键,还是李四调整的角度起了作用?多智能体系统里,成功的功劳没法精准拆分,失败的锅也不知道该谁背,导致模型越训练越混乱。 传统方法在实验室里看起来不错,一到真实的离线场景就拉胯:有的模型在简单迷宫里能让机器人找到路,到了复杂仓库就只会乱撞;有的方法在同步协作任务里表现还行,碰到需要按顺序配合的异步任务就彻底失效。
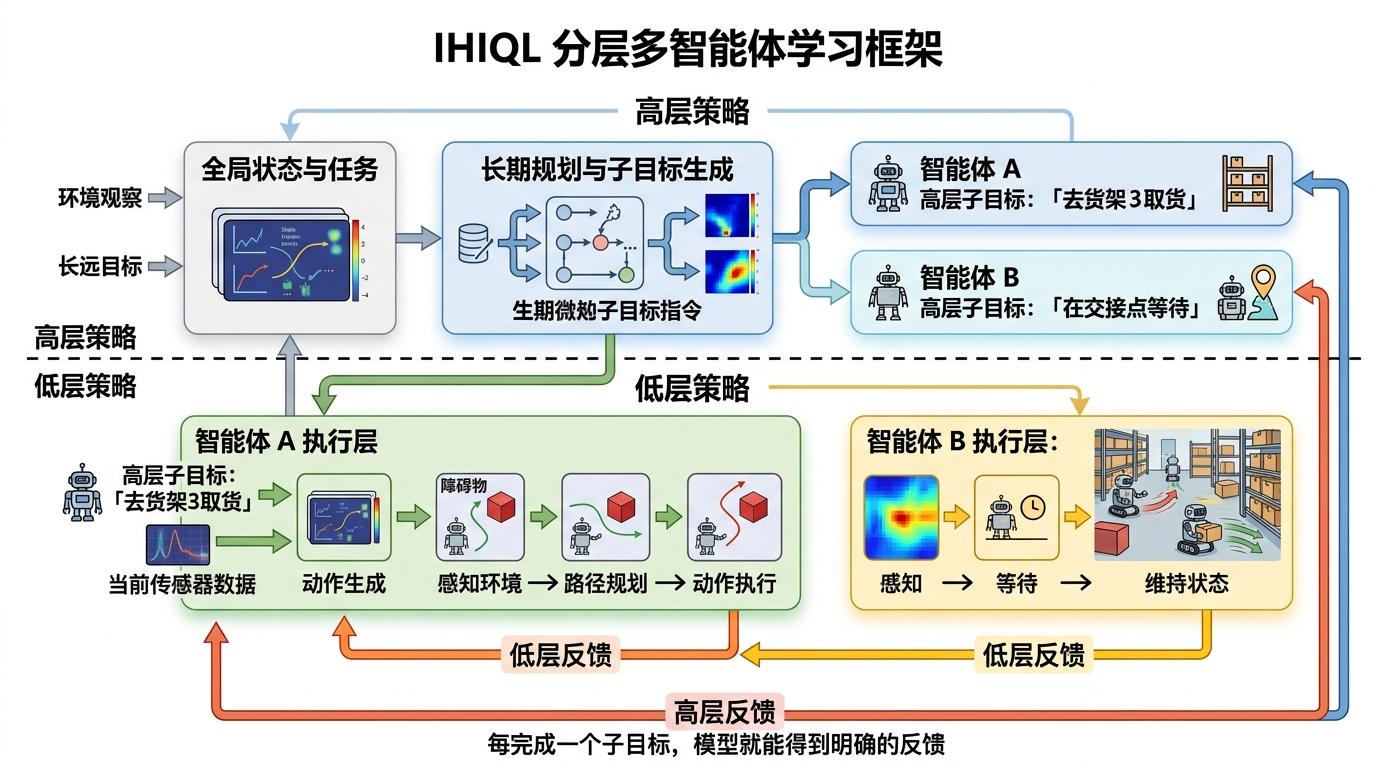
郭裕兰团队的破局思路,是把「奖励驱动」改成「目标驱动」——就像给搭积木的人一步步明确指令:先搭底座,再搭支架,最后封顶,每完成一步就给一个反馈。 他们提出的IHIQL分层方法,把复杂的多智能体任务拆成了多层子目标:高层策略负责规划「要做什么」,比如「机器人A去取货架3的货物,机器人B在交接点等待」;低层策略负责执行「怎么做」,比如「机器人A怎么避开障碍物」。每完成一个子目标,模型就能得到明确的反馈,不用等到最后才知道对错。
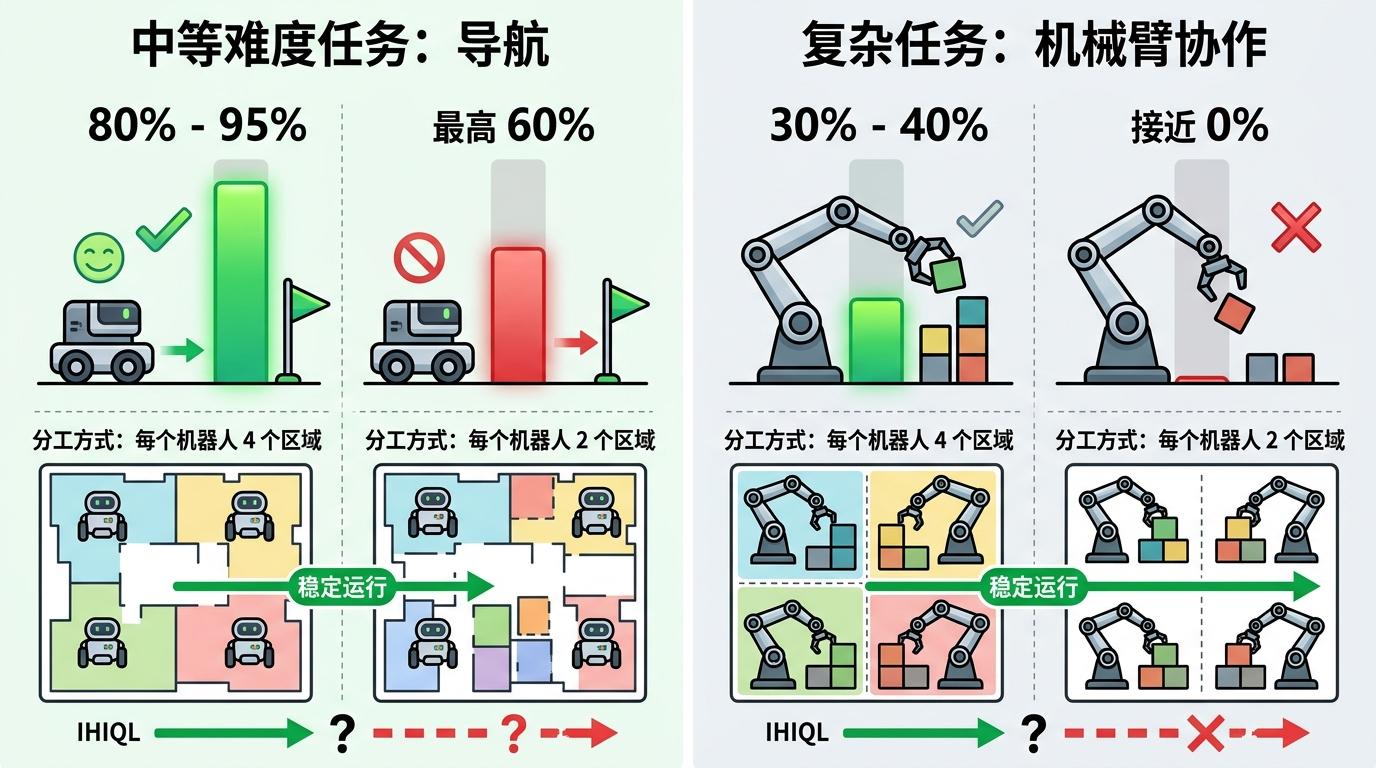
实验数据最能说明问题:在中等难度的导航任务里,IHIQL的成功率能达到80%-95%,而传统方法最高只有60%;到了复杂的机械臂异步协作任务,IHIQL虽然成功率降到30%-40%,但其他方法基本都接近0%。更关键的是,它对分工方式不敏感——不管是每个机器人管4个区域还是2个区域,都能稳定完成任务。
更值得关注的是,这项研究解决了「离线学习」的核心痛点:不用在现实中试错,就能学会协作。IHIQL的训练时间只有模仿学习方法的5%,却能达到更高的成功率——这意味着企业不用花大价钱让机器人在仓库里反复试错,用已有的运营数据就能训练出靠谱的协作策略。 但它也有局限:在超大规模的任务里,比如上百台机器人同时工作,IHIQL的成功率会降到50%左右,虽然比传统方法好,但离完美还有距离。另外,它在异步协作任务里的表现不如同步任务,说明面对需要精准时序配合的场景,还有优化空间。 不过,MangoBench基准的意义更长远——它第一次给离线多智能体协作提供了统一的测试标准,就像高考题一样,让不同的算法能在同一个赛道上公平竞争。这会倒逼更多研究者解决实际问题,而不是只在实验室里做漂亮的论文。
当我们谈论AI的未来时,往往关注单个智能体有多聪明,却忽略了「一群AI怎么一起干活」——这才是真正能改变世界的技术。仓库机器人的默契协作、自动驾驶车队的有序通行、医疗机器人的配合手术……这些场景的实现,都依赖离线多智能体强化学习的突破。 「把复杂任务拆成小目标,让协作有迹可循」,这不仅是技术思路,也是人类解决复杂问题的底层逻辑。未来的智能社会,不会是单个超级AI的独角戏,而是无数个普通智能体的协作舞台。而郭裕兰团队的研究,就是这个舞台的第一块基石。