对抗知识焦虑,从看懂这条开始
App 下载
AI画图不再瞎忙活,复杂细节终于有算力了
生成精度提升|AI图像生成|细节算力分配|图像区域分配|慕尼黑大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载生成精度提升|AI图像生成|细节算力分配|图像区域分配|慕尼黑大学|多模态视觉|人工智能
你有没有过这种经历:让AI画一张带招牌的街景,天空和墙面糊得均匀又平滑,可招牌上的字却扭成了天书?或者生成一张人像,皮肤质感像磨皮过度,头发却炸成了模糊的毛球?这不是AI偷懒,是它一直在做一件蠢事——给天空和眼睛分配一模一样的算力。2026年4月,慕尼黑大学的团队捅破了这层窗户纸:他们让AI学会了“区别对待”图像区域,简单的地方快速带过,复杂的细节砸够算力,结果在同样的计算成本下,生成的图像细节精度直接上了一个台阶。
你可以把传统AI画图的过程想象成:老师给全班学生发了一模一样的100道题,学霸10分钟就写完了,学渣写到下课还在啃第一题。而慕尼黑团队的Patch Forcing技术,就是给AI装上了一个“智能班主任”—— 首先,它把图像切成一个个小方块(也就是论文里的Patch),然后给每个方块打分:天空、纯色背景是“学霸题”,只需要做10道;眼睛、文字、复杂纹理是“学渣题”,得做满100道。更聪明的是,它让“学霸方块”先写完作业,变成清晰的图像区域,再把这些清晰区域当“参考答案”,给还在做题的“学渣方块”当参考。
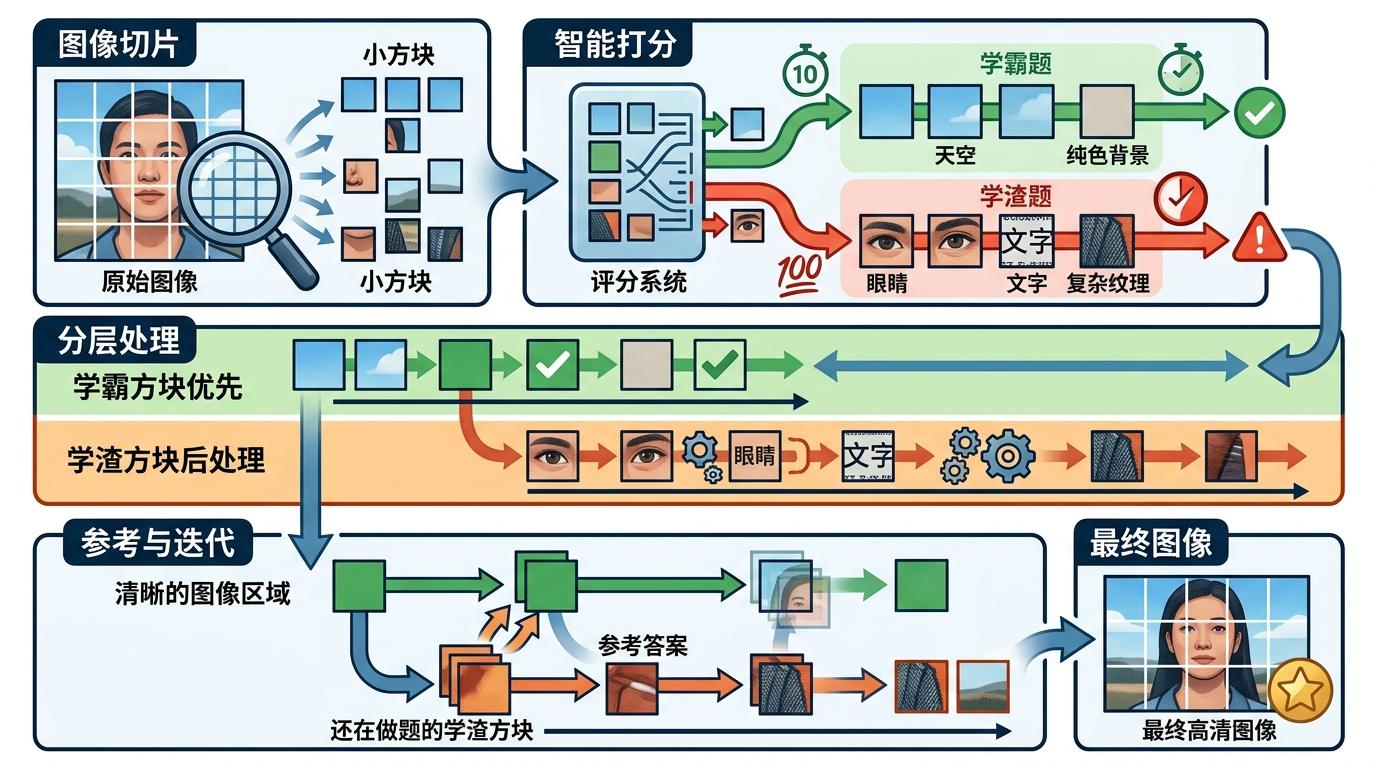
为了不让AI在训练时“作弊”——比如提前看到完整的参考答案,团队设计了一套叫LTG的采样规则:训练时严格控制所有方块的“最大模糊度”,确保没有一个方块能提前变成完全清晰的状态,让AI在和推理时一样的“全模糊起点”下学会判断难度。
说起来简单,实际效果才是硬通货。在图像生成界的经典擂台ImageNet 256×256测试中,同样的模型架构,同样的计算步数,用了Patch Forcing的模型直接把FID分数(衡量生成图像和真实图像差距的指标)从12.9降到了9.8——这意味着生成的图像和真实照片的相似度大幅提升。 在文生图测试里,它的优势更明显:之前AI生成的文字要么是乱码,要么像被水泡过,现在却能清晰还原招牌上的字母和标语。团队做了个对比:同样的提示词,传统模型生成的“咖啡馆招牌”是一团模糊的色块,用了Patch Forcing的模型却能写出清晰的“CAFE”字样。

当然,它也不是完美的。目前的难度判断还只停留在边缘、纹理这些低层视觉特征上,还看不懂“这张图里的人脸是关键,得重点画”这种语义信息;动态调度的超参数调起来也很麻烦,弄不好反而会拖慢推理速度。
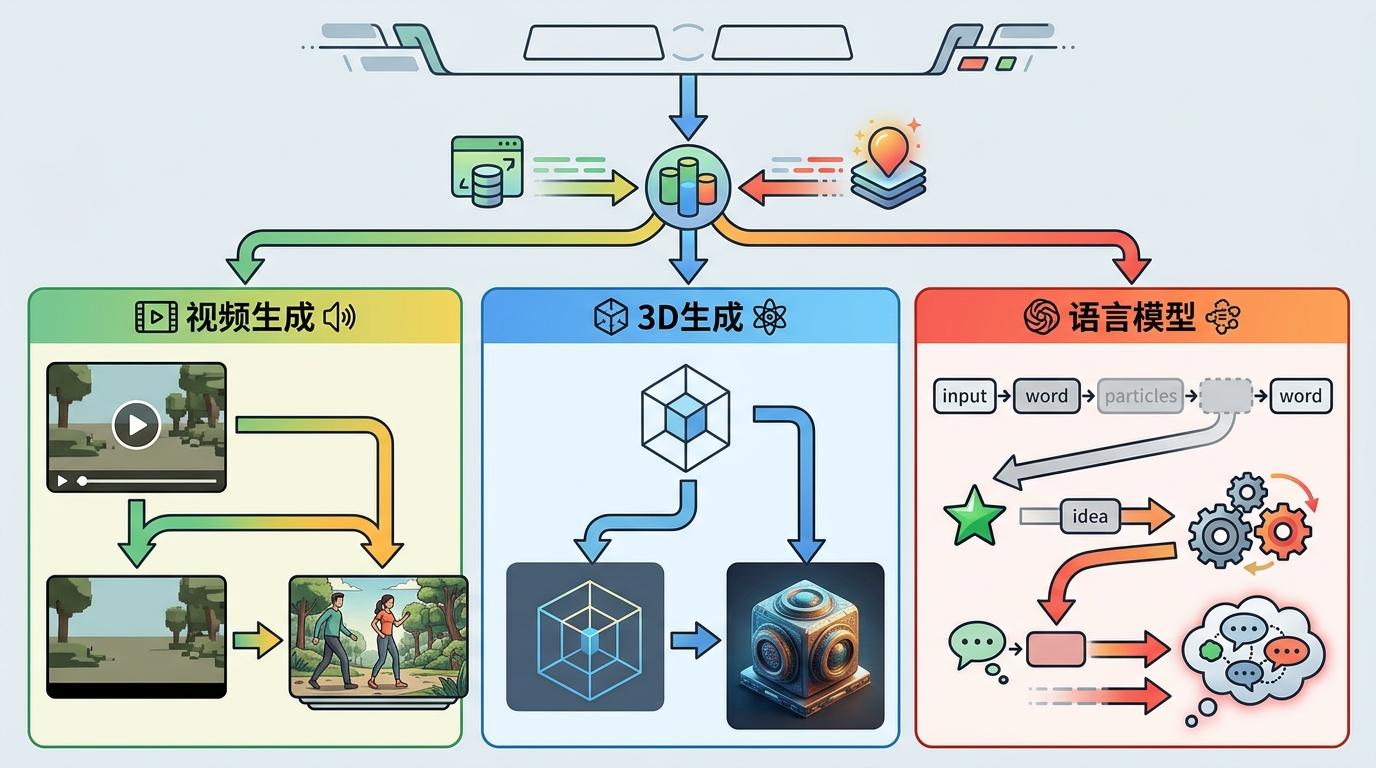
Patch Forcing的意义,远不止画好一张图那么简单。它打破了生成式AI“均匀计算”的默认规则,给整个领域指了一条新路子:AI的计算不应该是大锅饭,而应该像人类干活一样——先做简单的,再啃复杂的,还能互相帮忙。 现在已经有研究者在琢磨,把这个思路用到视频生成里:让静态的背景先渲染好,再慢慢细化动态的人物动作;或者用到3D生成里,先搭好简单的几何体框架,再给复杂的纹理和细节分配算力。甚至连语言模型都能借鉴:让AI跳过那些无关紧要的语气词,把算力用在关键的逻辑推理上。
不过,这条路也有挑战。动态计算分配和现在GPU的并行计算架构天生有点矛盾,怎么让AI在“区别对待”的同时,不浪费硬件的并行能力,还得研究者们再花点心思。
从AlphaGo学会“弃子”,到现在AI画图学会“区别对待”,我们一直在让AI变得更像人类——不是模仿人类的动作,而是学习人类的“偷懒智慧”:把有限的精力,用在最该用的地方。 Patch Forcing不是终点,它只是打开了一扇门:未来的AI,不会再做无意义的重复劳动,而是会像一个精明的工匠,把每一分算力都花在刀刃上。毕竟,聪明的努力,永远比盲目的勤奋更重要。