对抗知识焦虑,从看懂这条开始
App 下载
中科院团队补上氢态方程的百年断层
巨行星磁场|氢态方程|深度学习方法|温稠密氢|中科院物理所|分子细胞生物学|AI产业应用|生命科学|人工智能
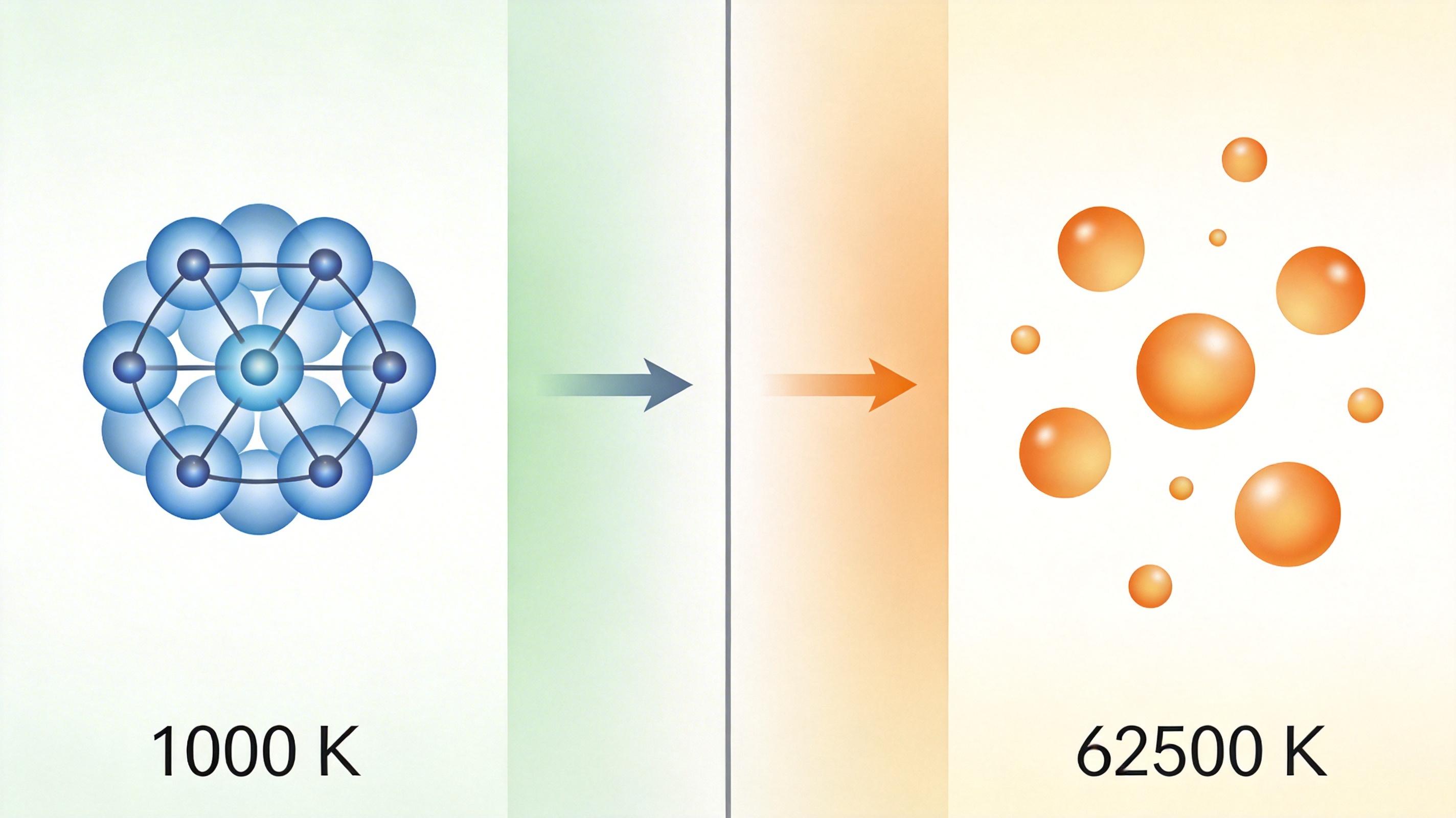
木星核心的压力是地球大气压的3000万倍,温度高达2万摄氏度——这里的氢既不是我们熟悉的气体,也不是等离子体,而是一种叫“温稠密氢”的奇异状态。它是巨行星磁场的源头,也是可控核聚变的关键燃料,但人类对它的认知,却卡在了1万到6.25万开尔文的温度区间:低温方法在高温下失效,高温方法在低温里“卡壳”,不同理论算出的结果差出一个量级。就像有人画了半幅地图,另一半却永远拼不上。直到中科院物理所的团队,用一套结合深度学习的新方法,把这断裂的地图连了起来。
被“符号诅咒”和“热失效”困住的氢
要理解这个断层,得先搞懂科学家们之前为什么束手无策。我们平时说的氢,是由两个氢原子组成的分子,但在高温高压下,分子会解离成单个原子,电子也会从基态跳到激发态——这就是温稠密氢的世界。
之前的计算方法分成了两派:一派是“低温派”,比如密度泛函理论,擅长算电子老老实实待在基态的情况,但温度一高,电子开始“乱跑”,这套方法就像用静态地图导航车流,完全不准;另一派是“高温派”,比如路径积分蒙特卡罗,能处理热激发的电子,但碰到低温高密度的情况,就会遭遇“费米子符号问题”——简单说就是计算时会出现大量正负抵消的项,计算量随温度降低呈指数爆炸,就像你数钱时,每数一张就有一张凭空消失,永远算不清总数。

这就导致了一个尴尬的局面:在1万到6.25万开尔文的区间,两派方法都不管用,不同理论算出的氘的Hugoniot曲线(描述冲击压缩下物质状态的“标准路线图”)能差出10%以上。
三套神经网络拼出完整的氢
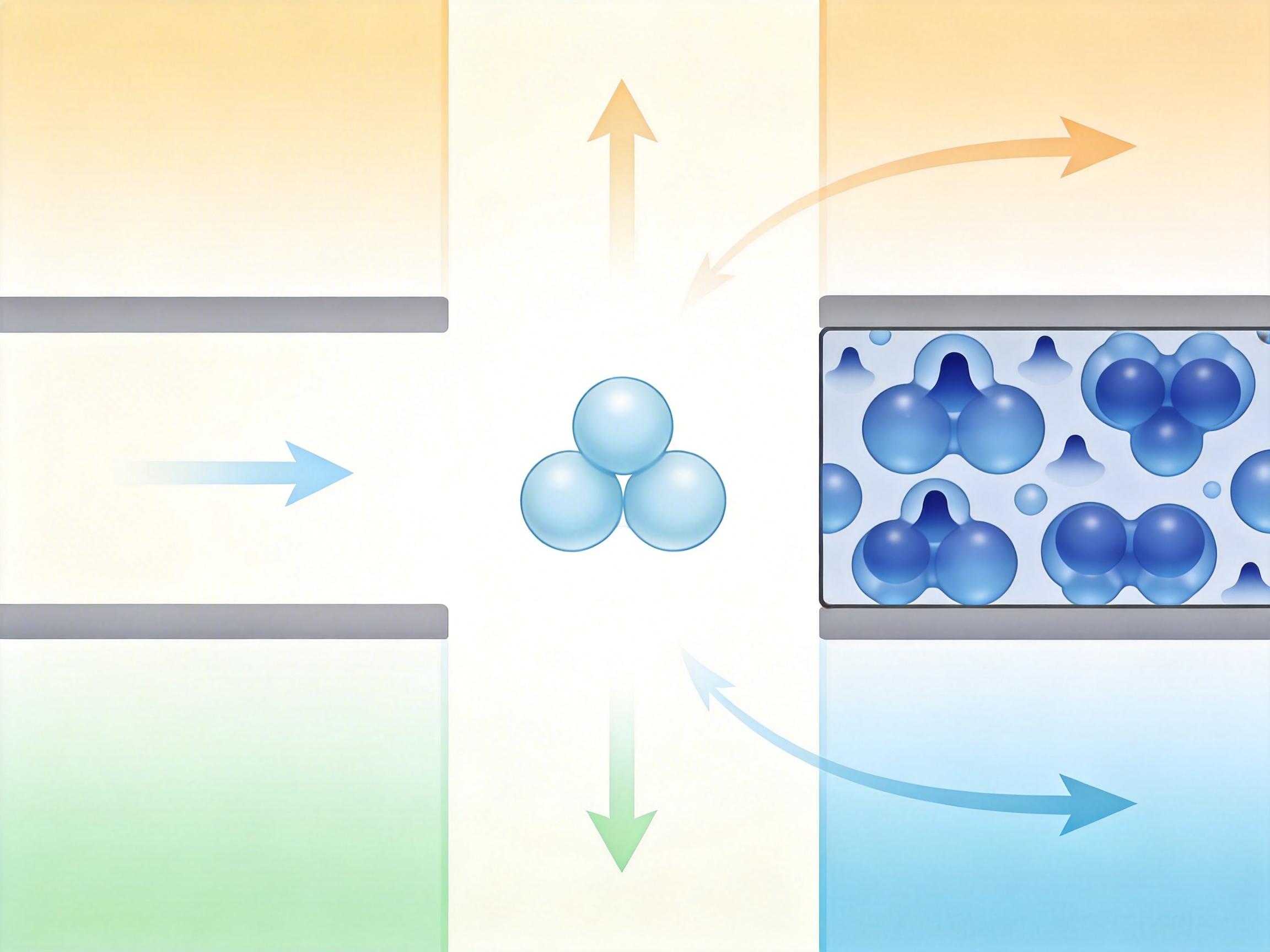
中科院物理所的团队用的“深度变分自由能方法”,相当于给这两派方法搭了一座桥。他们没有像传统方法那样,要么只算低温要么只算高温,而是用三套神经网络,同时给原子核和电子的“状态”建模。
你可以把这套方法想象成同时指挥三个团队:第一个团队用“归一化流”模型,专门模拟氢原子核的热运动,就像记录一群高速运动的小球的轨迹;第二个团队用“自回归变换器”,追踪电子在不同能级的分布,哪怕电子跳到激发态也能精准捕捉;第三个团队用“置换等变流”,处理电子之间的量子关联,保证计算符合量子力学的规则。
这三个团队不是各自为战,而是一起朝着“最小化变分自由能”的目标优化——自由能是描述系统稳定状态的关键物理量,就像找一个山谷的最低点,找到它,就找到了氢在这个温度密度下的真实状态。更重要的是,这套方法完全避开了“费米子符号问题”,还能直接算出熵和自由能这些之前只能间接估算的量。
他们的计算结果在低温端和“低温派”的结果完美衔接,在高温端又和“高温派”的结果平滑对接——相当于让之前各说各话的两派方法,第一次在氢的Hugoniot曲线上“握了手”。
从原子到分子的“隐形转变”
这套方法不仅补上了理论断层,还让科学家第一次看清了温稠密氢的微观变化。比如在1万开尔文时,电子几乎都待在基态,电子熵接近零,就像教室里的学生都乖乖坐着;温度升到6.25万开尔文时,氢分子完全解离成原子,就像下课铃一响,学生全散了架。
更有意思的是,他们通过原子核的径向分布函数,看到了氢从原子相到分子相的转变过程:当温度降低时,原本均匀分布的原子,会慢慢聚集出对应氢分子的峰——就像散落的小球,开始两两抱团。这些微观细节,之前的方法要么看不到,要么算不准。
我认为最值得关注的,不是这个结果本身,而是它的思路:之前科学家们总在想“怎么改进现有方法”,而这个团队直接用深度学习的思路,重新定义了“怎么描述量子多体系统”。这不是对传统方法的修修补补,而是换了一套“操作系统”。
当我们谈论可控核聚变时,总在说“什么时候能点火”,但很少有人知道,我们连燃料在极端条件下的状态都没完全搞清楚;当我们观测木星磁场时,总在猜“它的发电机原理是什么”,但如果连核心的氢是什么状态都不确定,一切模型都是空中楼阁。
这个研究补上的不只是一段理论曲线,更是人类对极端条件下物质认知的空白。用AI拼量子世界的地图,这才是真正的跨界。
未来,这套方法还能推广到更复杂的物质,比如氦氢混合物,甚至是其他元素的温稠密状态。也许再过十年,当我们看木星的内部模型时,会想起今天这篇论文——它是第一块拼上的、准确的拼图。