对抗知识焦虑,从看懂这条开始
App 下载
仿真里走得溜的机器人,到现实就垮台
虚拟仿真训练|强化学习PPO|双足机器人|TRON 1|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载虚拟仿真训练|强化学习PPO|双足机器人|TRON 1|AI智能体|人工智能
2026年春,一台只有两条腿的机器人TRON 1被搬进了办公室。它每条腿3个关节、6个电机,是构型最精简的双足机器人——专门用来研究一个最基础的问题:两条腿怎么在真实世界站稳走稳。
操作它的工程师先在虚拟环境里给它做训练:用强化学习PPO算法,设置18个奖惩规则,3个给奖励(站稳、按方向移动),15个负责惩罚(脚不着地、走太慢、方向错了都要罚)。只用两三个小时,虚拟机器人就走得稳稳当当。可当把这套完美的程序传到真实机器人身上时,它突然像个刚学步的孩子:脚抬不起来,腿迈不开,时不时原地抽搐,甚至把办公室的金毛都吓哭了。这到底是为什么?
你可以把强化学习PPO算法理解成“胡萝卜加大棒”:机器人做对动作就给奖励,做错就给惩罚,通过成千上万次试错找到最优路径。而虚拟仿真环境,就是给它提供了一个绝对安全的训练场——这里没有地面摩擦力的细微变化,没有传感器延迟,没有电机响应的微小误差,甚至可以同时让成千上万个机器人一起训练,效率是真实世界的几十倍。
工程师给TRON 1设置的奖惩机制,更是把“钻空子”的可能堵死:要是只给“不摔倒就奖励”,机器人可能会直接原地罚站;要是奖励太宽松,它又会学出些奇奇怪怪的动作。18条规则像个紧箍咒,逼着它只能老老实实练走路。两三个小时后,虚拟机器人的步态已经丝滑得像个正常人,甚至能完成边跳边走的复杂动作。
但真实世界从来不是完美的。
当虚拟模型传到真实机器人身上,那些在仿真里被忽略的“小事”,突然变成了致命的问题:地面瓷砖的摩擦系数比仿真设定高0.1,机器人的脚就会打滑;传感器延迟了10毫秒,它的重心调整就慢了一拍;电机的实际扭矩比仿真值低5%,它的腿就抬不到预定高度。这些在数字世界里可以忽略的误差,在几十斤重的铁疙瘩身上被无限放大,直接导致步态崩溃。
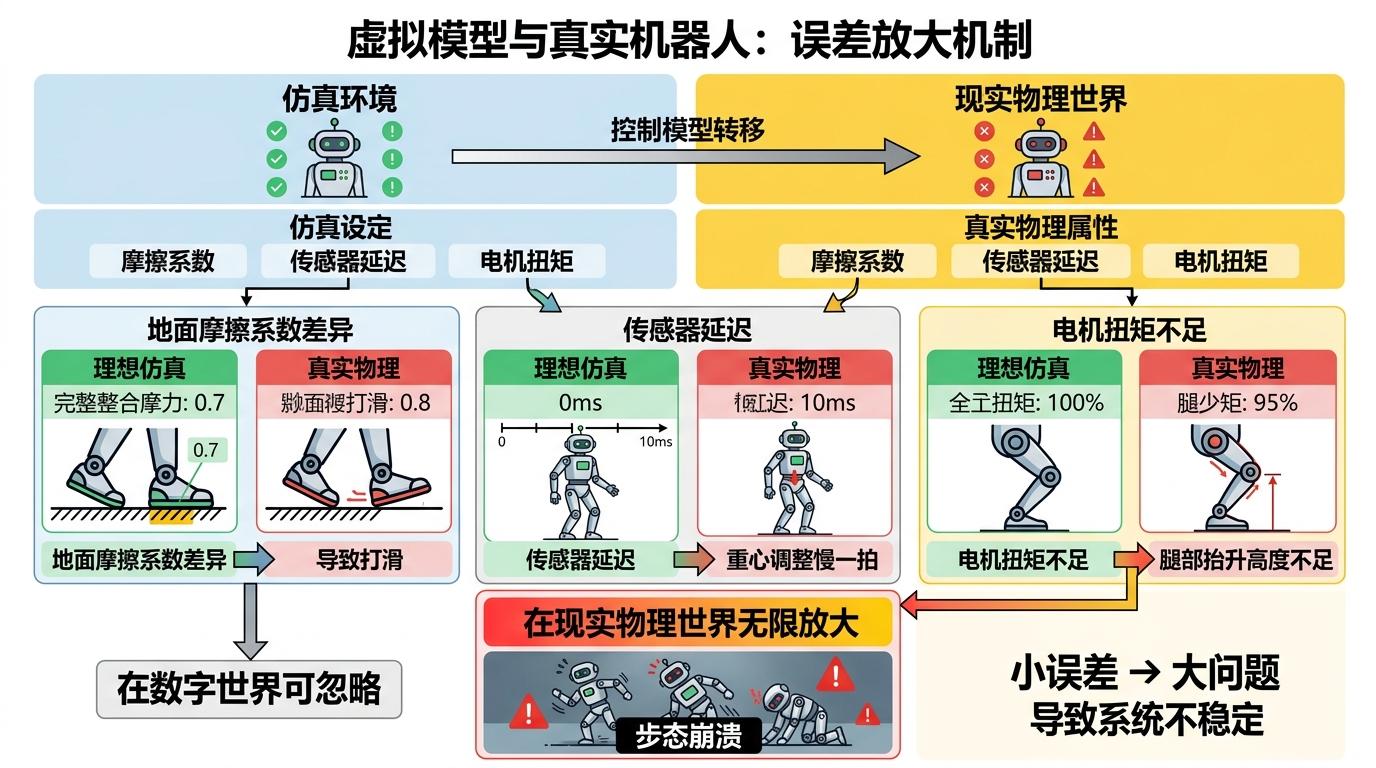
这就是具身智能最核心的“迁移难题”——机器人的智能不是存在于代码里,而是存在于身体和环境的交互中。仿真环境可以模拟物理规律,却永远无法复刻真实世界的所有变量:你没法预知地面上的一颗小石子,没法模拟电机温度升高后的扭矩变化,更没法还原真实环境里所有不可控的扰动。
工程师反复调整奖励函数,回炉重造模型,甚至尝试了上百次实验,偶尔才能让机器人踉踉跄跄走两步。更无奈的是,有时候你修复了一个bug,反而会引入更多bug——比如为了让它抬更高的腿,结果导致重心直接失衡。
很多人觉得,这种只能走两步的双足机器人没什么用,不如那些能跳舞、能搬运的人形机器人酷炫。但研发团队说,TRON 1的价值,恰恰在于它的“精简”——用最少的关节,去探索双足行走最底层的规律。
人类进化出直立行走用了几百万年,早稻田大学造出第一个会走路的机器人WABOT,花了整整10年。而现在,一个非专业工程师用不到一天就能让TRON 1在仿真里走起来,这已经是巨大的进步。更重要的是,在TRON 1身上试错的成本极低:它的结构简单,损坏了容易修,实验迭代速度快。等把双足行走的底层规律摸透了,再把这些经验迁移到更复杂的人形机器人身上,就能少走很多弯路。
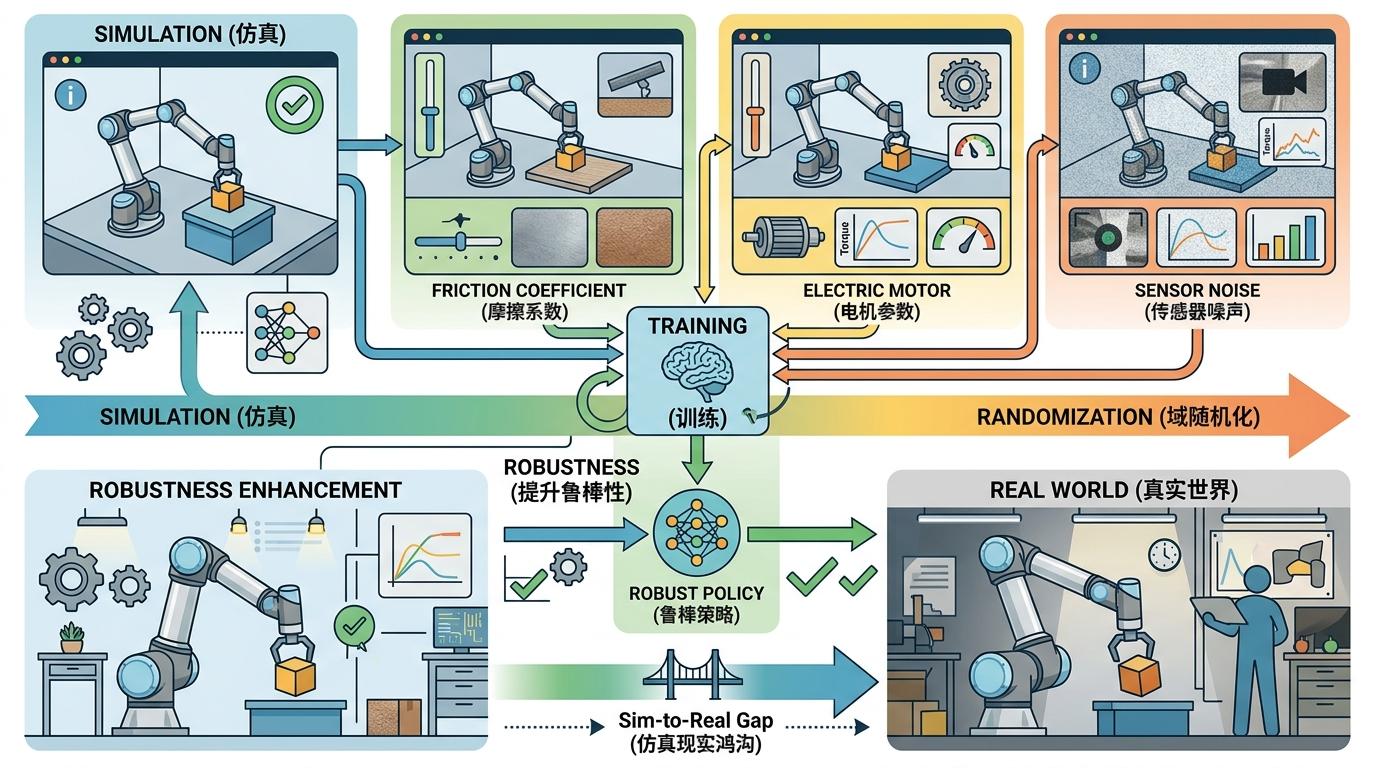
当然,这并不意味着迁移难题能轻易解决。目前最有效的方法,是在仿真里加入“域随机化”——随机改变摩擦系数、电机参数、传感器噪声,让机器人在训练时就适应各种“不完美”,以此提升它在真实世界的鲁棒性。但即便如此,仿真和现实的鸿沟依然存在。
当我们在视频里看到机器人跳舞、跑步时,很容易觉得“这玩意儿没技术含量”,但只有亲手试过才会明白:让一个铁疙瘩像人一样在真实世界里站稳走稳,是一件多么难的事。
机器人学的进步,从来不是靠一个“革命性”的突破,而是靠无数次试错、无数次调整、无数次从摔倒中爬起来。仿真里的完美,永远替代不了现实里的试错。从TRON 1到更复杂的人形机器人,每一个微小的进步,都是在为未来的机器人铺路——终有一天,它们能真正像人一样,自由地行走在这个充满不确定性的世界里。