
24 天前
24 天前
开车时前方突然修路,你不用摸手机、不用移开视线,只需要对着空气说一句“告诉朋友我要迟到”,眼镜捕捉到你的路况,AI自动编辑消息发送;盯着货架上的饮料说“加购物车”,它能立刻识别品牌型号,帮你完成下单——这不是科幻电影的场景,而是现在就能实现的日常。当AI不再困在手机屏幕里,而是附着在眼镜上“看你所看、听你所听”,我们和机器的关系,正在发生根本性的改变。
过去的AI,更像一个会聊天的搜索引擎:你问它“这瓶饮料是什么”,它能回答,但没法帮你把饮料放进购物车;你让它“翻译路牌”,它能输出文字,但没法直接帮你导航过去。这种“只说不做”的局限,直到自动化执行框架和多模态感知结合才被打破。
你可以把这套系统想象成一个完整的“机器人管家”:智能眼镜是它的眼睛和耳朵,实时捕捉你眼前的画面、耳边的声音,甚至感知你所处的环境——比如你正在开车、你盯着的是货架上的哪款商品;多模态AI是它的大脑,把视觉、听觉信息翻译成能理解的语义,判断你的真实需求;而自动化执行框架就是它的手和脚,能调用手机发消息、操控浏览器下单、控制智能家居设备。
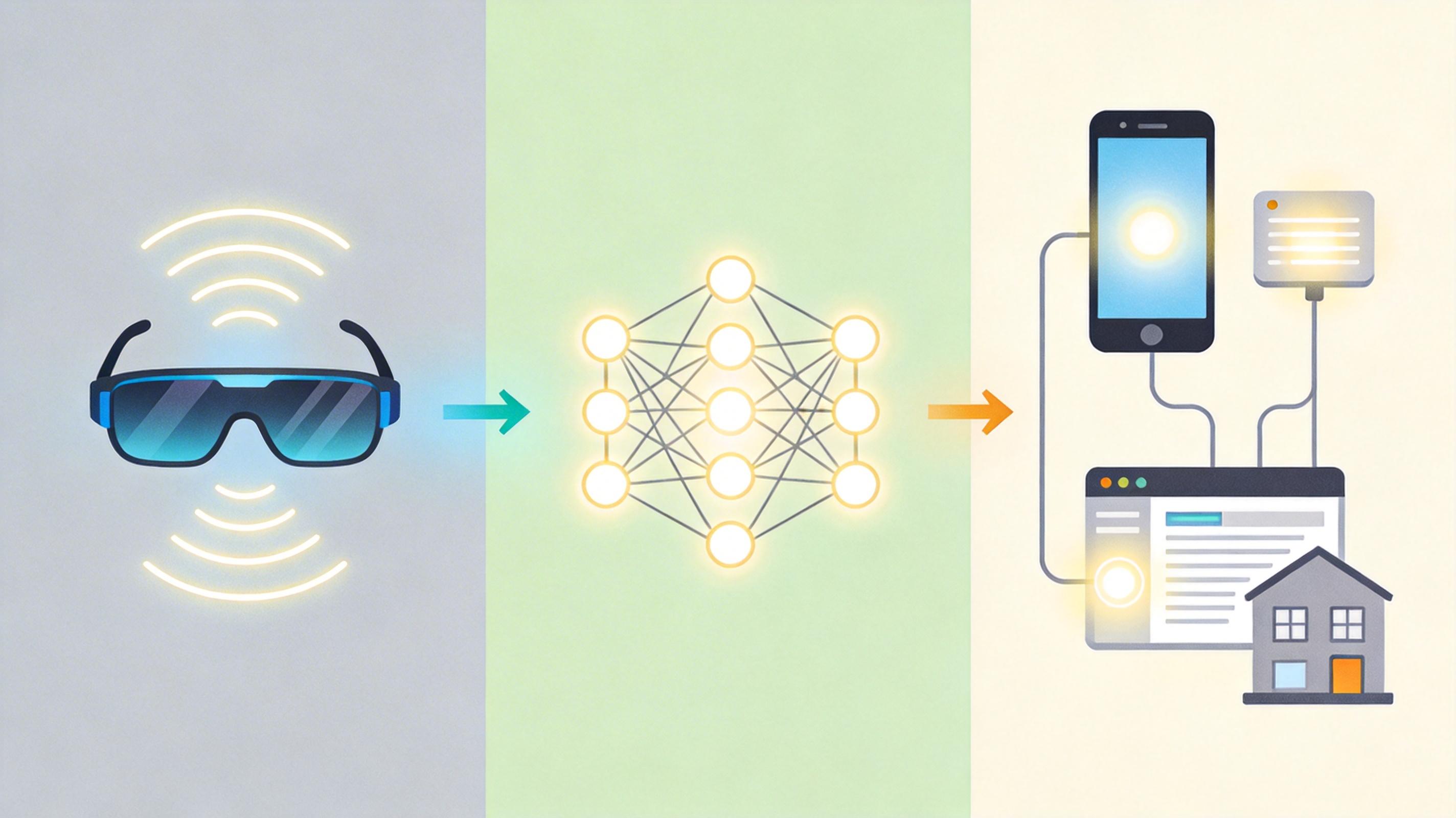
这个“感知-决策-行动”的闭环,让AI从“信息提供者”变成了“任务执行者”。比如开源项目VisionClaw,就是把智能眼镜的实时画面、Gemini的多模态理解能力,和OpenClaw的自动化工具结合,实现了“所见即所做”:你看什么、说什么,它就能帮你完成对应的操作。
既然这套系统能在手机上实现,为什么智能眼镜成了最受关注的形态?答案藏在“持续在场”这四个字里。
手机的交互逻辑是“唤醒-操作-关闭”:你需要主动拿起它、解锁屏幕,才能让AI获取信息。但智能眼镜是“时刻在线”的——它能全天佩戴,持续捕捉你的视线焦点、所处环境、甚至你的动作姿态,这些上下文信息,恰恰是AI做出精准决策的关键。比如你盯着台灯说“调暗”,手机需要你先告诉它是哪盏灯,而眼镜能直接通过你的视线锁定目标,无需额外说明。

当然,现在的智能眼镜还有不少局限:续航只有3-4小时,摄像头帧率限制在1帧/秒,动态场景下识别精度会下降,长时间佩戴的舒适性和公众接受度也有待提升。但这些技术瓶颈正在被快速突破:2025年全球智能眼镜出货量同比增长322%,Meta、Rokid等厂商在轻量化、低功耗芯片上持续投入,而开源生态的繁荣,让更多开发者参与到功能扩展中——比如接入医疗数据监测、工业场景的远程协作。
当AI时刻“看你所看、听你所听”,隐私和安全的问题也随之而来。2026年出现的“ClawJacked”漏洞,能让攻击者通过恶意链接窃取用户数据,实现远程代码执行;而AI的自主执行能力,也可能因为指令理解偏差,做出不符合用户预期的操作——比如误删邮件、错误下单。
为了应对这些风险,行业正在探索“全生命周期安全架构”:从数据采集时的输入净化,到决策时的语义一致性检查,再到执行时的沙箱隔离,甚至建立“人类在环”机制——关键操作必须经过人工确认才能执行。同时,本地优先的架构设计也在普及:AI的推理和数据处理尽量在本地设备完成,减少云端传输带来的隐私泄露风险。
更重要的是,我们需要重新定义人机协作的边界:AI是助手,不是替代者。它可以帮你完成重复繁琐的操作,但涉及个人隐私、重大决策的环节,最终的控制权仍在人类手中。
我们习惯了十年里用手机屏幕连接世界,现在AI开始跳出这个四方框,寻找更自然的存在形态。智能眼镜不是手机的替代品,更像是AI伸向现实世界的触角——它让交互从“人适应机器”,转向“机器适应人”。
未来的AI,会藏在眼镜里、手表里、耳机里,成为我们身边“看不见的伙伴”:它会在你开车时帮你处理消息,在你购物时帮你下单,在你看体检报告时提醒你注意健康风险。而我们要做的,是在享受便利的同时,守住隐私的底线,明确人机协作的边界。
人机共生的本质,是让AI成为人类能力的延伸。
点击充电,成为大圆镜下一个视频选题!