对抗知识焦虑,从看懂这条开始
App 下载
给医疗AI洗个物理澡,跨院诊断准确率飙升20%
跨院影像标准化|光学原理|PhyCV算法|病理切片|乳腺癌诊断AI|临床诊疗技术|AI产业应用|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载跨院影像标准化|光学原理|PhyCV算法|病理切片|乳腺癌诊断AI|临床诊疗技术|AI产业应用|医学健康|人工智能
你可能没听过这样的怪事:一款在A医院准确率95%的乳腺癌诊断AI,换到B医院直接跌到70%。不是AI变笨了,是两家医院的病理切片——有的染得深褐,有的偏浅粉,有的亮得晃眼,有的暗得发灰——在AI眼里根本不像同一种东西。这种「水土不服」,是医疗AI从实验室走进临床的最大拦路虎。直到加州大学洛杉矶分校的团队拿出了PhyCV:一个不用训练、只靠物理原理的算法,给杂乱的医疗影像「洗了个澡」,就让跨院诊断准确率直接跳到了90.9%。
你可以把医院里的原始影像看成刚开采的原油:富含有用信息,但混着各种杂质——不同设备的噪声、不同技师的染色习惯、不同扫描参数的明暗差。以前大家的思路是让AI自己在油里挑有用的,要么给AI灌几万张模拟杂质的图片练「抗干扰」,要么让AI同时学识别和「去杂质」,结果是AI越来越复杂,计算成本高得离谱,还容易学歪。
PhyCV反其道而行之:直接用物理原理当「炼油厂」,在数据进AI前就把杂质滤干净。它的核心是两步——虚拟衍射+相干检测:先把数字图像当成一束光,让它穿过一个虚拟的特殊介质,不同精细程度的图像信息(比如细胞边缘和背景色块)会在介质里走不同的「路」;最后不看光的明暗强弱,只看光的「相位」——这个物理量对细胞边缘、纹理这些诊断关键特征极度敏感,却对染色深浅、整体明暗这些「杂质」几乎没反应。
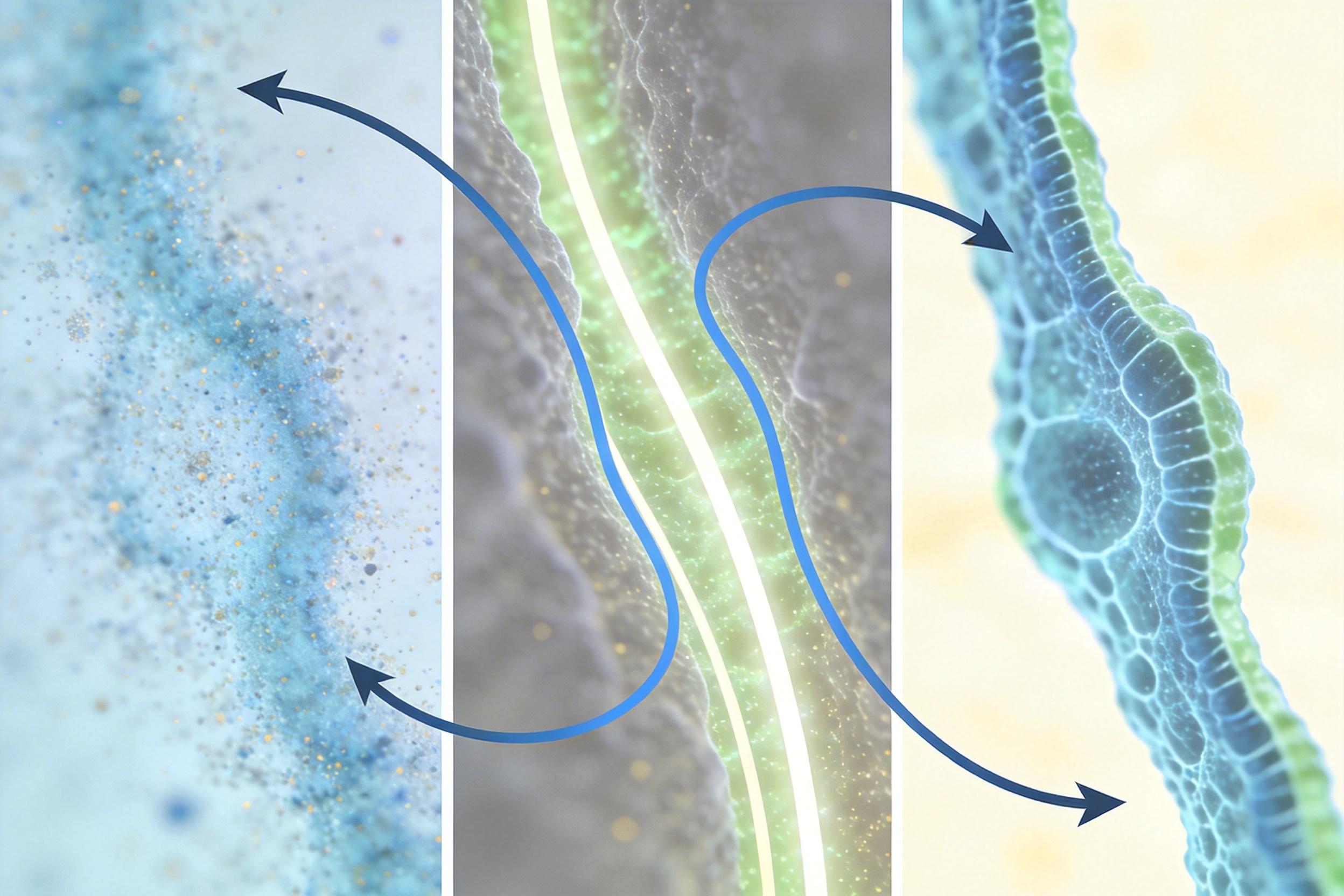
说穿了,就是把五颜六色的病理片,统一转成了只突出细胞结构的「线稿图」。不管你是深褐还是浅粉,在PhyCV眼里,只有细胞核的轮廓、细胞膜的纹理才是要紧的。
为了测试这个「炼油厂」的真本事,团队找来了专门用来刁难AI的Camelyon17-WILDS数据集——5家不同荷兰医院的乳腺癌切片,风格差异大到像5种不同的画。实验设计得特别公平:所有AI都用同一种DenseNet-121模型,只比预处理步骤。
结果让人大吃一惊:没做任何处理的AI准确率只有70.8%;那些靠复杂算法学「抗干扰」的AI,最多摸到74%;而加了PhyCV预处理的AI,直接冲到了90.9%——逼近了需要大量计算生成模拟样本的顶尖方法,计算成本却几乎可以忽略不计。
更妙的是它的「自我纠错」能力:团队故意给图像加了严重的光照干扰,原始图像的信息熵(衡量信息含量的指标)直接暴跌,而PhyCV处理后的图像熵几乎没动;直到图像差到完全没法看,PhyCV的输出才跟着变差——相当于自带了一个「质量检测器」,能告诉医生:这张图可能没法用。
最关键的是,这一切不需要训练,不需要标注数据,就是几次傅里叶变换和简单的相位计算——普通的临床工作站都能实时跑起来。
PhyCV的成功,其实戳破了一个行业误区:我们总觉得AI要越复杂越好,要靠海量数据喂出智能,却忘了物理规律本身就是最强大的「先验知识」。
以前我们给AI看病理片,就像让一个从没见过真猫的人,通过看不同角度、不同光线、不同毛色的猫照片学认猫——学得慢还容易错;而PhyCV相当于直接告诉AI:猫的本质是有尖耳朵、长尾巴、四条腿的动物,不管它是黑猫白猫。
当然它也不是完美的:目前的参数还靠人工调,遇到极端奇怪的「杂质」可能还没那么灵光;而且它只负责「炼油」,真正的诊断还是要靠AI。但它给了我们一个全新的思路:与其让AI在数据的泥沼里摸爬滚打,不如先给它铺一条干净的路。
当我们在为AI的「智商」突破欢呼时,PhyCV提醒了我们:有时候最聪明的解法,不是让AI变得更像人,而是利用自然本身的规律。
未来的医院影像科里,可能不会有那么多复杂的AI模型,却会有一个默默工作的「物理炼油厂」——把来自不同设备、不同医院的杂乱影像,变成统一标准的「诊断素材」。AI不用再学「抗干扰」,只需要专心看病。
用物理规律给AI铺路,比让AI自己开路更高效。