对抗知识焦虑,从看懂这条开始
App 下载
从谷歌到字节,吴永辉的多模态AI破局之路
跨模态感知|AI生成视频|字节跳动Seedance 2.0|吴永辉|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载跨模态感知|AI生成视频|字节跳动Seedance 2.0|吴永辉|多模态视觉|人工智能
2026年2月,一段AI生成的1分钟视频在科技圈炸开:镜头从雨天的小巷缓缓推进,咖啡馆里的女孩抬头时,窗外的闪电恰好照亮她眼底的情绪,背景的爵士乐和雨声同步起落,甚至能听到咖啡杯轻磕碟子的脆响。这不是专业团队的影视创作,是字节跳动Seedance 2.0的测试输出。而背后操盘的,是那个在谷歌深耕17年、把多模态AI从实验室推到产业前沿的吴永辉。为什么这个低调的华人科学家,能在加入字节一年就拿出让全球同行侧目的成果?这要从AI跨越「单模态孤岛」的关键一步说起。
你可以把单模态AI想象成只会一种语言的翻译——只会看文字的看不懂图片,只会听声音的理解不了视频。而多模态AI,是能同时听懂语言、看懂画面、识别声音的「全才翻译」,它能把不同类型的信息拧成一股,还原出更接近人类感知的完整世界。
吴永辉在谷歌参与Gemini研发时,就盯着这个核心问题:怎么让不同模态的信息真正「对话」,而不是简单拼接?Seedance 2.0给出的答案是双分支扩散Transformer架构——视觉和音频像两条并行的流水线,各自处理画面帧和声波信号,再通过「注意力桥」实时交换信息:当画面里出现玻璃破碎,音频分支会自动匹配对应材质的混响效果;当镜头拉远,背景音的音量会同步降低。
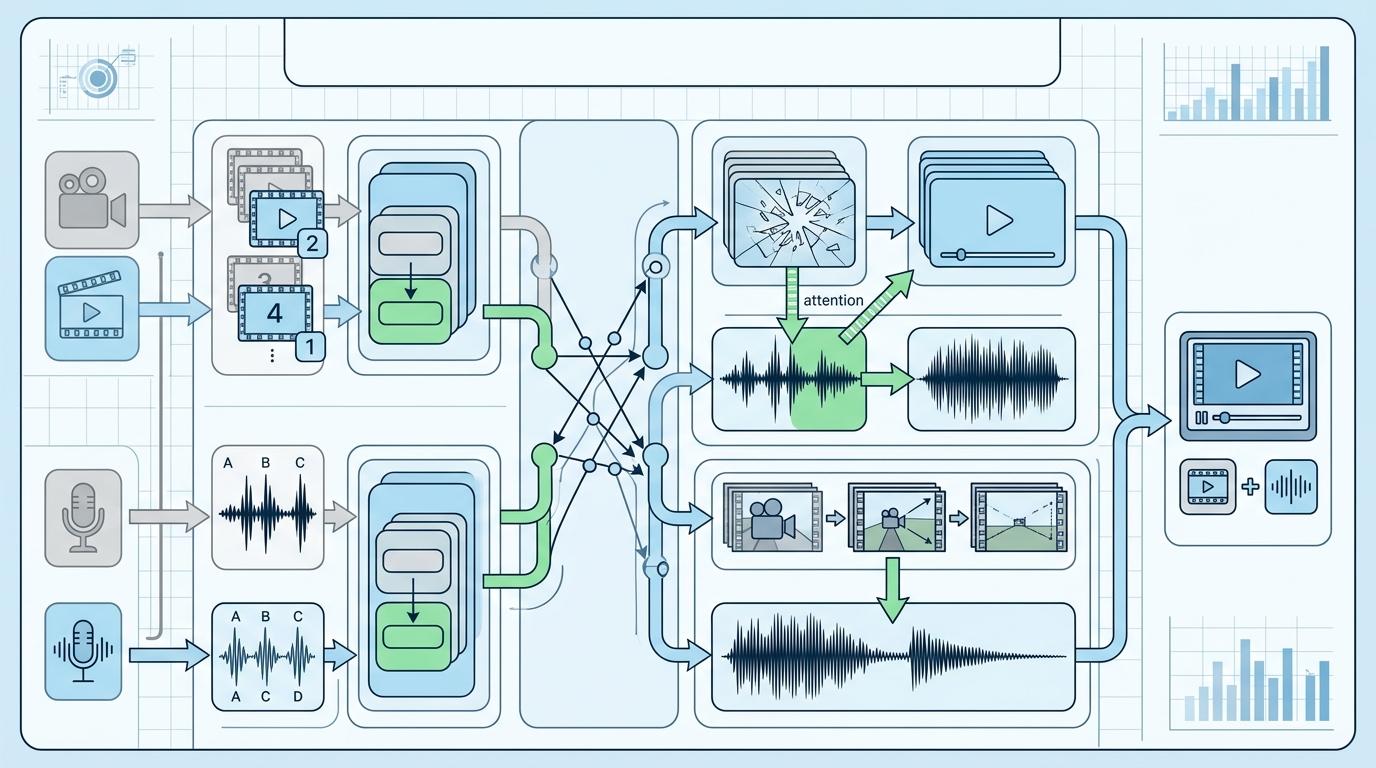
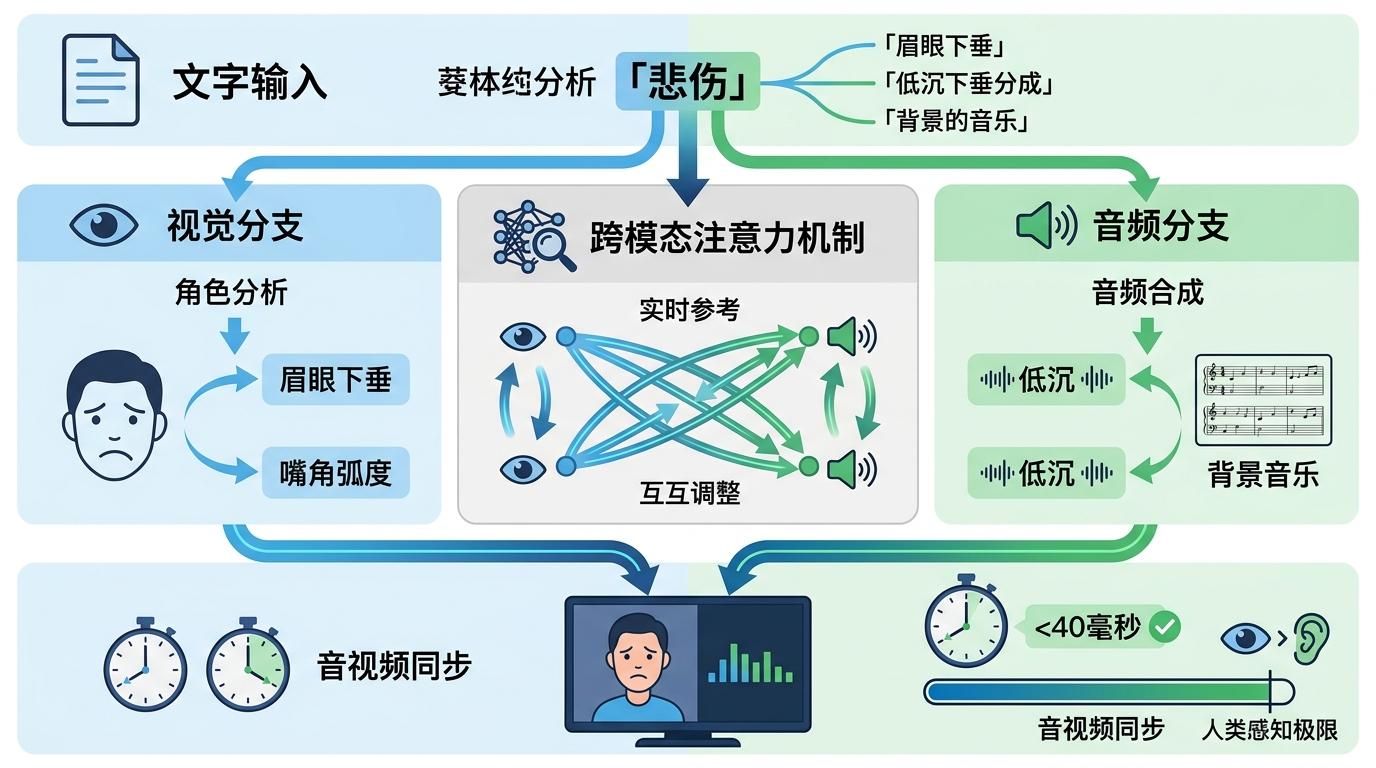
但真实的机制比这更精确。这套系统的核心是跨模态注意力机制:文本描述里的「悲伤」,会引导视觉分支重点捕捉人物的眉眼下垂、嘴角弧度,同时让音频分支生成低沉的背景音乐。每一个模态的输出,都在实时参考其他模态的信号,最终实现误差低于40毫秒的音视频同步——这个精度,已经接近人类肉眼的感知极限。
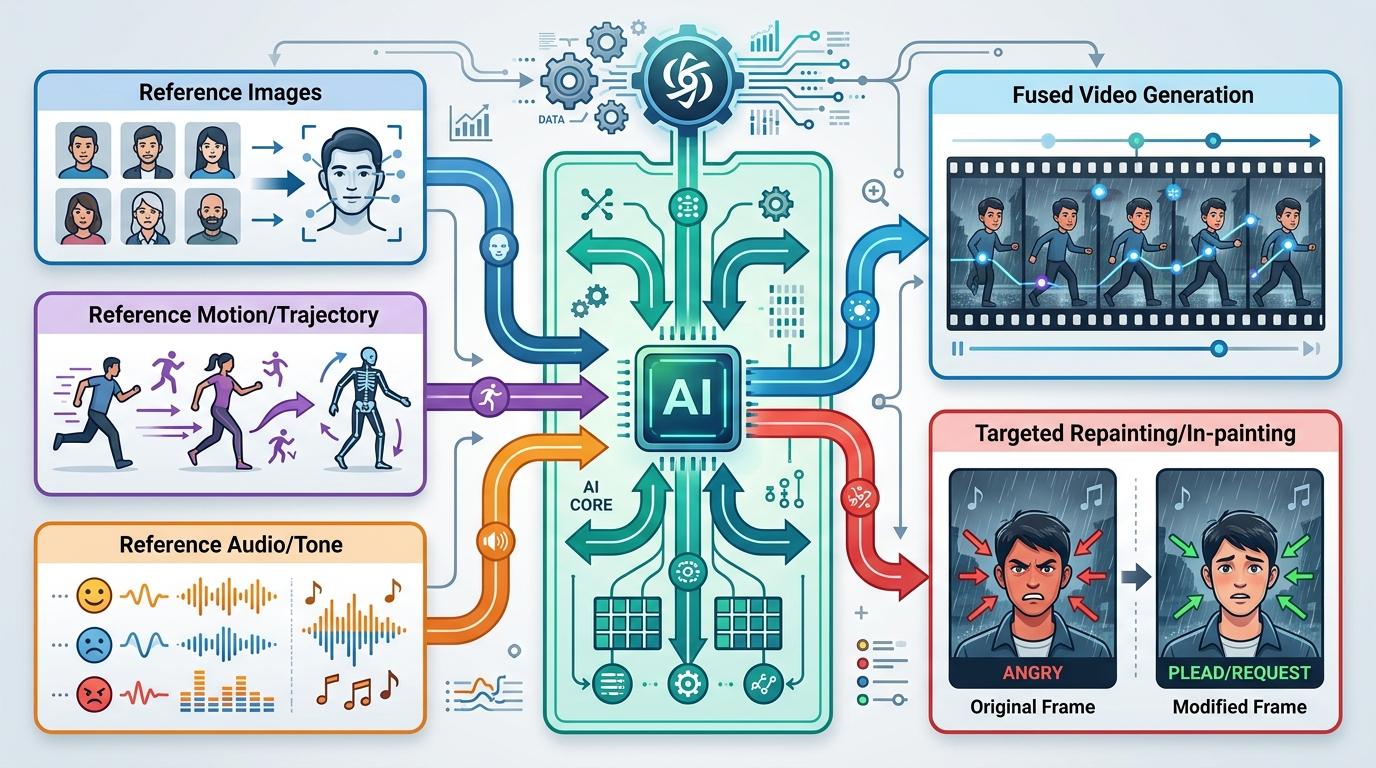
吴永辉团队的厉害之处,不止是突破技术瓶颈,更是把复杂的AI能力,变成了普通人能上手的工具。Seedance 2.0的「@引用」系统,就像给AI安了个精准导航——你可以指定某张图片的人物脸型,某段视频的动作轨迹,某段音频的情绪基调,AI会把这些元素无缝融合成新的视频,甚至支持局部重绘:把人物的愤怒表情改成恳求,同时保留背景的雨声和音乐不变。
这背后是字节跳动的产业逻辑:AI不能只停留在实验室的跑分榜单上,要能解决真实场景的问题。Seedance 2.0的生成成本只有0.5美元/次,是OpenAI同类产品的一半,生成可用率却高达90%——行业平均水平还不到20%。这种效率的提升,靠的不是堆算力,而是吴永辉带来的「工程化思维」:用混合训练策略先让不同模态对齐,再通过指令微调适配具体场景,同时用MoE架构把算力用在刀刃上,避免不必要的资源浪费。
当然,光环背后也有隐忧。Seedance 2.0刚上线就因版权问题被好莱坞多家公司起诉,字节不得不紧急限制真人肖像生成功能。这也暴露了多模态AI的共性难题:训练数据的版权边界、生成内容的伦理风险,这些都不是技术能单独解决的问题。
现在的多模态AI,还像个记性不好的聪明人——能处理短片段的信息,却没法记住几小时前的对话,更没法完成需要多步推理的复杂任务。吴永辉团队的下一个目标,就是解决长推理和长文本处理的问题。
你可以把这个过程想象成让AI写一篇长篇小说:不仅要记住开头的人物设定,还要让中间的情节连贯,结尾的逻辑自洽。目前他们的思路是扩展模型的上下文窗口,同时引入「世界模型先验」——让AI先学习真实世界的物理规律和常识,比如「苹果掉下来会落地」「人不能凭空消失」,再用链式思维把复杂任务拆解成一步步的小问题。
已经有了初步成果:Seed2.0能处理小时级别的长视频,快速提取关键信息,甚至能根据视频内容生成完整的解说文案。但要让AI真正拥有「长期记忆」,还要解决算力成本和模型效率的矛盾——毕竟,记住越多信息,需要的计算资源就越多,这又是一场技术和成本的博弈。
当我们惊叹于AI生成的逼真视频时,其实是在见证一个时代的转折:AI正在从「感知世界」走向「理解世界」。吴永辉从谷歌到字节的选择,本质上是站在技术和产业的交叉口,把实验室里的突破,变成了能改变普通人生活的工具。
技术的终极意义,是服务人的需求。 未来的AI不会是冰冷的机器,而是能听懂情绪、看懂场景、记住偏好的「伙伴」。而像吴永辉这样的科学家,就是连接技术理想和现实需求的桥梁——他们让我们相信,AI的下一站,不仅是更强大的能力,更是更懂人的温度。