对抗知识焦虑,从看懂这条开始
App 下载
AI不再“死记硬背”:强化学习如何教会3D模型思考?
虚拟角色建模|物理真实性|几何约束|3D生成模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载虚拟角色建模|物理真实性|几何约束|3D生成模型|多模态视觉|人工智能
想象一位游戏设计师,他不仅需要构思一个角色的炫酷外观,更要确保其骨骼结构合理,能在虚拟世界中稳定站立与奔跑。现在,想象一个AI,它可以根据“骑士”的指令生成一张华丽的2D图像,但当被要求生成一个3D骑士模型时,却可能交出一个盔甲悬浮、四肢错位的“艺术品”。这正是当前3D生成AI面临的核心困境:它擅长“绘画”,却不擅长“建造”。
长期以来,3D生成模型如同一个记忆力超群但缺乏逻辑的学生,能复现训练数据中的样式,却无法真正理解三维世界的内在规则——几何约束、物理真实性和功能可供性。模型在生成过程的后半段,常常会“忘记”前半段设定的几何框架,导致结构崩塌。如何让AI从一个被动的“像素画家”进化为一个主动的“数字工匠”,学会像人类一样思考和规划复杂的3D结构?这不仅是技术瓶颈,更是通往“世界模型”和具身智能的关键一步。
近日,一场学术界的“思维风暴”为这个问题带来了突破性的答案。一项由西北工业大学、北京大学、香港中文大学、上海人工智能实验室及香港科技大学的顶尖学者合作的研究,系统性地揭示了**强化学习(Reinforcement Learning, RL)**如何为3D生成模型注入“思考”的能力。他们的研究成果《我们准备好在文本到3D生成中使用RL了吗?一次渐进式探索》不仅回答了这个问题,更提供了一套完整的方法论。
研究团队的核心结论是:通过精心设计的强化学习范式,可以显著增强3D模型在生成过程中的逐步推理能力,使其不再仅仅是“调优美学”,而是在空间几何、物理可行性等维度上表现出深刻的理解力。这标志着3D生成技术的一次范式转移,AI正从“死记硬背”走向“理解创造”。
要让AI学会思考,首先要定义什么是“好”的思考。研究团队将这一复杂问题拆解为三个层次,层层递进,最终构建出一个能引导模型进行结构化思考的强大框架。
1. 奖励设计:为AI建立一个多维度的“价值观”
如果奖励仅仅是“看起来像”,那么AI永远学不会建造。团队设计了一套复杂的奖励系统,如同为AI聘请了一组来自不同领域的专家评审:
这个多维度、多层次的奖励系统,确保了AI在学习过程中,既追求美观,也尊重物理和几何规律。
2. 算法选择:从“期末考试”到“随堂测验”
传统的生成模型往往在生成结束后才获得一个总分,这就像只参加期末考试,过程中犯了错也无从知晓。而3D生成是一个序列决策过程,每一步都至关重要。
团队发现,相比于对整个3D模型进行一次性评价,在每个“token”(构成3D模型的基本单元)层面进行奖励和策略优化,效果要好得多。这种“token级”的强化学习,如同给AI配备了一位随时指导的贴身教练,在每一个微小的决策点上进行引导,确保它不会在早期就偏离正确的“建造蓝图”。
3. 层次化范式Hi-GRPO:让AI像雕塑家一样思考
这是本次研究最核心的创新。团队观察到,人类创造3D物体时,天然遵循着“从粗到细”(coarse-to-fine)的流程:先搭建整体的几何骨架,再雕琢局部的纹理细节。他们将这一人类智慧融入AI的训练范式,提出了层次化强化学习框架Hi-GRPO。
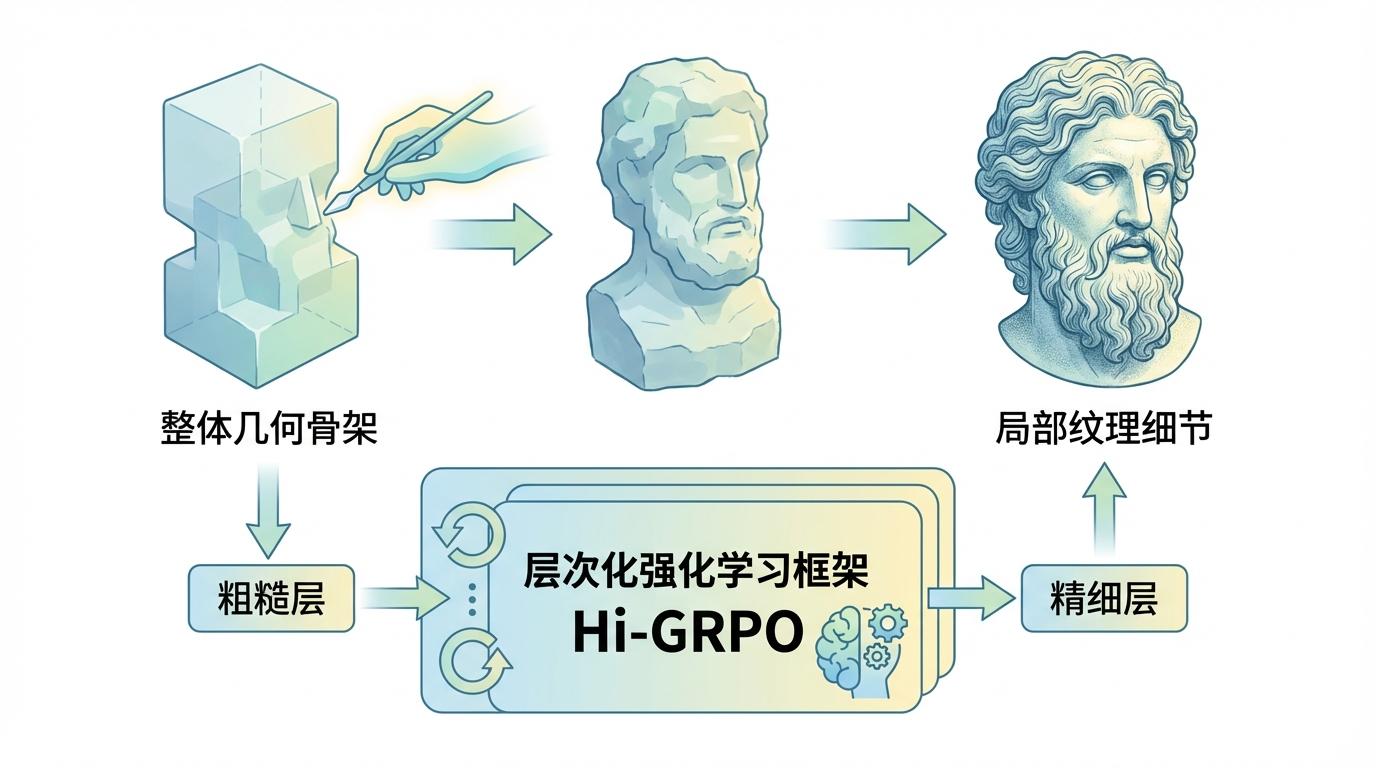
最精妙的设计在于,第二步(细节)的得分会反向传播,影响第一步(骨架)的奖励。这意味着,如果一个几何骨架虽然本身结构合理,但不利于后续添加精美纹理,它也会得到低分。这迫使AI在搭建骨架的初始阶段就必须进行“深思熟虑”,预判后续步骤的可能性,从而真正实现了“规划”与“思考”。
为了证明强化学习带来的不是虚假的性能提升,而是一种真实的“推理能力”飞跃,团队构建了首个专注于3D推理能力的基准测试MME-3DR。它不像传统基准那样充满常见物体,而是包含了大量“刁钻”的测试用例,涵盖五大类别:复杂的空间几何、机械功能性、有机生物形态、长尾稀有概念和抽象风格化形态。

在这个堪称“炼狱级”的考场上,经过Hi-GRPO训练的模型AR3D-R1表现惊人。在MME-3DR上的得分从19.8分跃升至28.5分,提升幅度高达44%。这雄辩地证明,强化学习激发的不仅仅是模型的模仿能力,更是其底层的、可泛化的三维空间推理能力。
这项研究的意义远不止于生成更逼真的3D模型。它为我们揭示了一条通往更高级别人工智能的可能路径。
对科学界而言,它证明了通过对齐人类的创造流程(如“先几何、后纹理”),并施加结构化的奖励,可以引导AI模型涌现出类似“思维链”的推理能力。这是对当前大模型“黑箱”内部机制的一次深刻洞察,为构建更可解释、更可控的AI提供了宝贵经验。
对现实世界而言,一个能“思考”3D世界的AI,将彻底改变众多行业。在工业设计领域,AI可以根据功能需求直接生成物理上稳定、结构上合理的零件;在游戏和影视行业,它可以快速生成海量高质量、风格化的3D资产;在机器人和自动驾驶领域,这种对三维空间的深刻理解是实现真正“具身智能”的前提。
尽管取得了重大突破,但研究团队也清醒地指出了当前模型的局限性。对于极其复杂的几何结构、闻所未闻的长尾概念,以及强风格化的艺术要求,模型依然会“逻辑崩坏”。此外,高质量奖励信号的获取成本和巨大的算力需求,仍然是阻碍技术大规模应用的主要障碍。
未来的方向是明确的:开发出能直接理解3D数据(如点云或网格)的“3D原生”奖励模型,让AI自动学习何时从几何构建切换到纹理细化,甚至将物理仿真引擎直接嵌入训练循环,让AI在虚拟世界中进行“实验”,从而内化物理规律。
最终,这场关于3D生成的探索,本质上是在回答一个更宏大的问题:我们如何让诞生于数字世界的AI,真正理解我们所处的物理现实?通过强化学习,我们正教会AI不再满足于描摹世界的表象,而是开始理解其背后的结构、逻辑与法则。这不仅是技术的飞跃,更是我们与未来智能体协作方式的一次深刻预演。