对抗知识焦虑,从看懂这条开始
App 下载
百万字上下文落地,AI长记忆时代真的来了
低成本AI|注意力机制|长上下文能力|国产开源模型|百万字上下文|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载低成本AI|注意力机制|长上下文能力|国产开源模型|百万字上下文|大语言模型|人工智能
当你还在为AI读不完一份100页的合同而拆分文本时,有个模型已经能一次性吞下15本《哈利·波特》的内容——还能精准找出第7本第3章里的某个咒语细节。2026年4月,就在OpenAI发布GPT-5.5数小时后,一款国产开源模型带着百万字上下文能力登场,把AI的「记忆极限」直接拉到了新刻度。更让人意外的是,它的使用成本只有顶尖闭源模型的几十分之一。人们好奇的是:它到底靠什么突破了困住所有大模型的长上下文瓶颈?
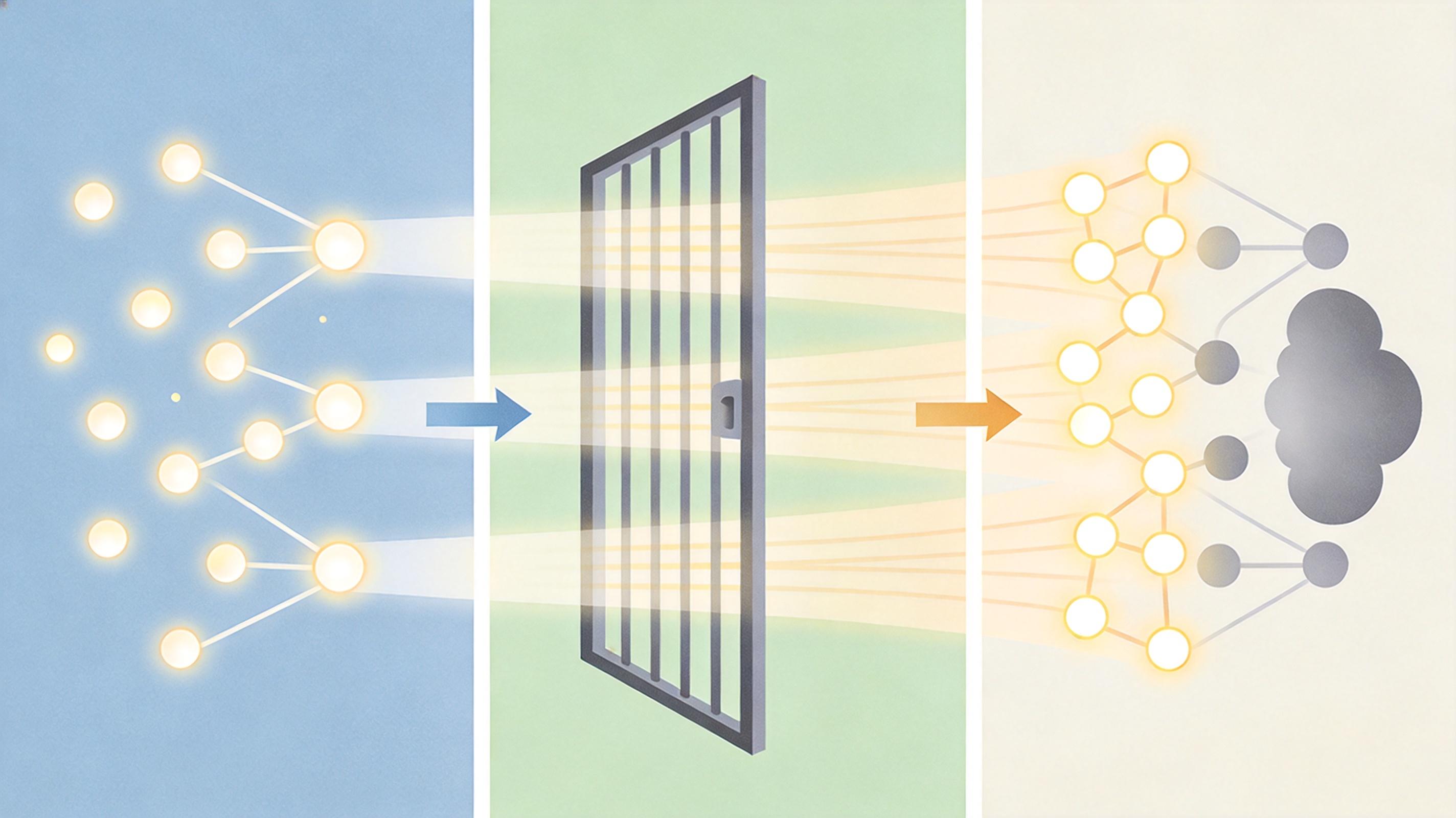
你可以把大模型的注意力机制想象成一群同时读书的学生:传统模型里每个学生都要把整本书逐字读一遍,书越长效率越低;而这次的新方法,是让专门的「记忆员」把书中反复出现的固定知识点——比如成语、公式、代码语法——提前抄在小本子上,其他学生只需要专注理解前后逻辑。
这个叫Engram的「记忆员」模块,用哈希表把静态知识做成了可快速检索的「记忆库」,实现了O(1)的常数级查找速度。打个比方,以前AI要回忆「水的沸点是100℃」,得从头在神经网络里「重新推导」一遍;现在直接从记忆库调取,就像查字典一样快。
但真实的机制比这更精确:它会先通过多头哈希给每个知识点做「专属标签」,再用上下文感知门控判断当前场景需要哪条记忆——比如提到「水在高原的沸点」,就不会调出标准大气压下的数值。在长文本检索测试中,这个模块把AI的信息定位准确率从84.2%拉到了97%,同时还释放了20%-25%的计算资源,让AI能把精力放在更复杂的推理上。
解决了记忆问题,还要解决大模型的「高血压」——当模型参数涨到万亿级别,传统的残差连接就像没有稳压的电线,信号在传递中要么被放大到爆炸,要么衰减到消失,导致训练时经常「死机」。
这次的解决方案是给信号通路加了个「流形约束」:把连接矩阵限制在双随机矩阵的数学流形里,就像给水管装了恒压阀,保证每段通路的信号强度始终稳定。研究团队用Sinkhorn-Knopp算法反复校准矩阵,让每行每列的数值和都等于1,既保留了多路径传输的灵活性,又避免了信号失控。
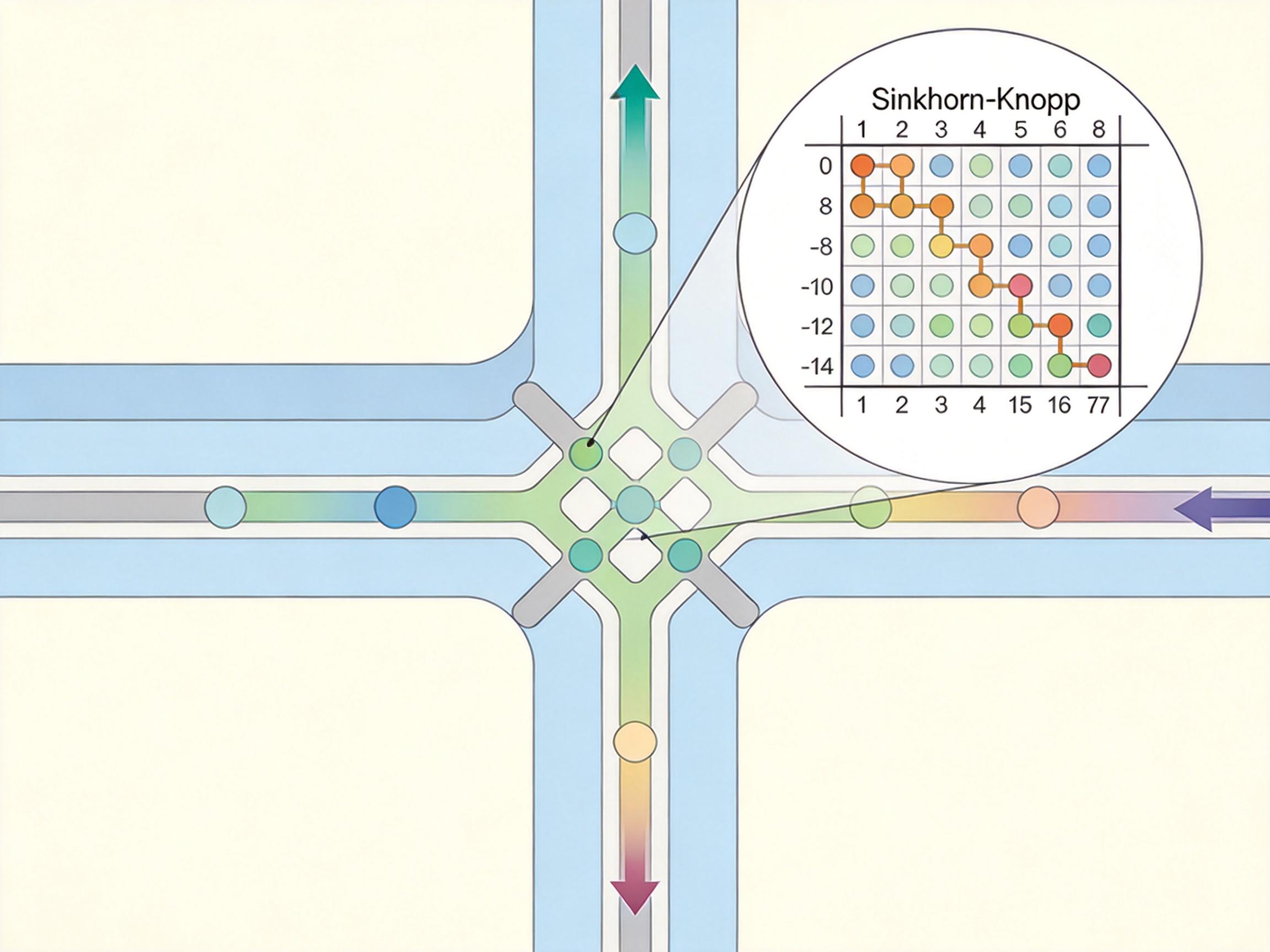
这个叫mHC的设计,仅用6.7%的额外训练开销,就把模型的训练稳定性提升了一个量级。在27B参数的模型测试中,它彻底避免了传统超连接导致的梯度爆炸,让模型能安全地扩展到更宽更深的结构。
而针对长上下文的计算瓶颈,团队还设计了DSA稀疏注意力:用一个轻量的「闪电索引器」给每个词快速打分,只选择最相关的Top-K个词计算注意力,把原本O(n²)的计算复杂度降到了O(nk)。在百万字上下文场景下,这个设计让推理速度提升了2倍,显存占用直接砍到原来的10%。
当大家都在比拼参数规模时,这个团队走了另一条路:用「计算+记忆」的双稀疏策略,在不增加太多成本的前提下,把模型的有效能力拉到了新高度。
它的Pro版本总参数1.6万亿,但实际激活的只有490亿——就像一个有1000个科室的医院,每次只唤醒最相关的几个科室接诊。这种MoE架构让它能以接近370亿参数模型的成本,实现万亿级模型的性能。在代码修复测试中,它的准确率超过了80%,接近顶尖闭源模型的水平;在长文本检索任务中,它能在百万字的内容里精准定位到像「针藏在草堆里」一样的细节。
当然它也有局限:为了追求长上下文效率,架构设计得相对复杂,在极端摘要和复杂指令遵循上还有提升空间;而且目前Pro版本的服务吞吐还受限于国产算力的供应,要等到下半年新芯片批量上市才能大规模普及。但不可否认的是,它用实际表现证明:AI的下一个突破点,不一定是更大的参数,而是更巧的结构。
当我们还在讨论AI能不能通过律师资格考试时,这个模型已经能一次性处理整份几十万字的法律合同;当我们还在为AI写代码时要拆分文件而头疼,它已经能直接读懂整个大型代码库。
这不是一次简单的版本更新,而是给AI装上了「长效记忆」——从此它不再是只能处理片段信息的「速读选手」,而是能深度理解完整复杂系统的「专家」。计算为骨,记忆为魂,AI终于能真正「读万卷书」了。
未来的AI或许会像人类一样,既有瞬间处理信息的算力,也有存储和调用知识的记忆。而这次突破,就是通往那个方向的一块铺路石。