对抗知识焦虑,从看懂这条开始
App 下载
30亿参数模型,干翻GPT-4.1的秘密
深度研究任务|离线合成数据|滑铁卢大学|德州农工大学|OpenResearcher流水线|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载深度研究任务|离线合成数据|滑铁卢大学|德州农工大学|OpenResearcher流水线|大语言模型|人工智能
你敢信?一个只有30亿参数的开源AI模型,居然在深度研究任务上把GPT-4.1甩在了身后——前者准确率54.8%,后者只有36.4%。更离谱的是,这个模型从未碰过真实的在线搜索数据,所有训练都靠一套离线合成的研究轨迹。这不是某家科技巨头的黑科技,而是德州农工大学、滑铁卢大学等学术团队搞出的OpenResearcher流水线。它到底是怎么用低成本的离线数据,练出干翻闭源大模型的能力?
要训练能像人类一样做深度研究的AI,最大的难题从来不是模型本身,而是缺数据——那种能完整记录「搜索→浏览→推理」全流程的长轨迹数据。之前的方案要么靠在线API搜,不仅贵得要死,一条失败路径就烧掉几十美元,还因为网页内容天天变,数据根本没法复现;要么只能生成2到5步的浅层轨迹,连真实研究的门槛都碰不到。
OpenResearcher的思路直接换了赛道:先花一次钱,把1500万篇文档和1万篇确保包含答案的「黄金文档」打包,建一个本地搜索引擎。然后让大模型当「教师」,在完全离线的环境里,反复调用三种模拟人类研究的工具:
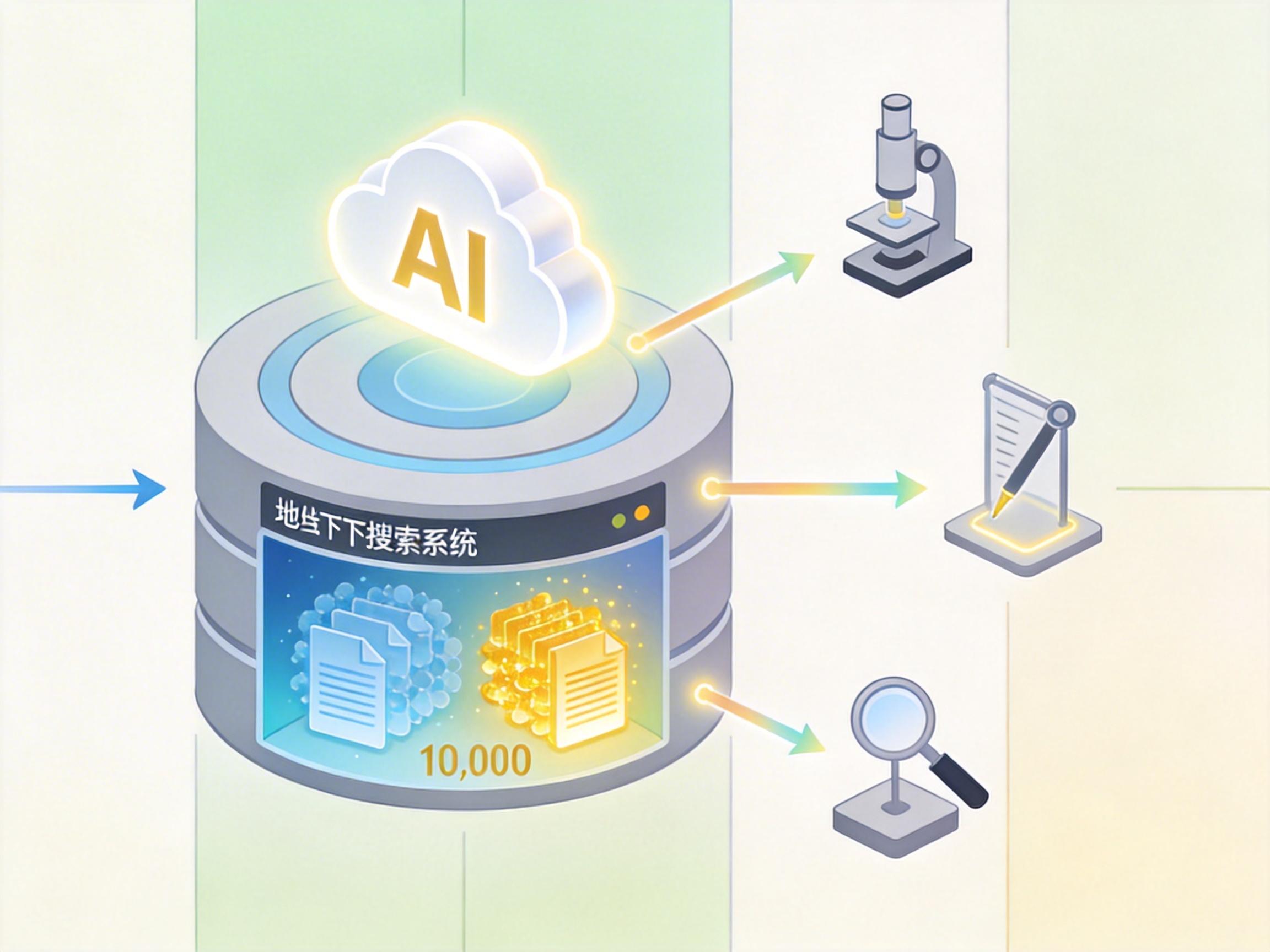
就靠这套组合拳,「教师」模型一口气生成了9.7万条长轨迹,其中不少轨迹的工具调用次数超过100次——完全模拟了人类啃复杂问题时,反复搜资料、翻文档、找证据的过程。最关键的是,这些数据零边际成本,想生成多少就生成多少,还100%可复现。
用这些轨迹训练30亿参数的模型时,研究者发现了一个反常识的结论:只给正确轨迹,模型准确率54.81%;只给错误轨迹,居然能到55.06%——两者差距不到0.6个百分点。
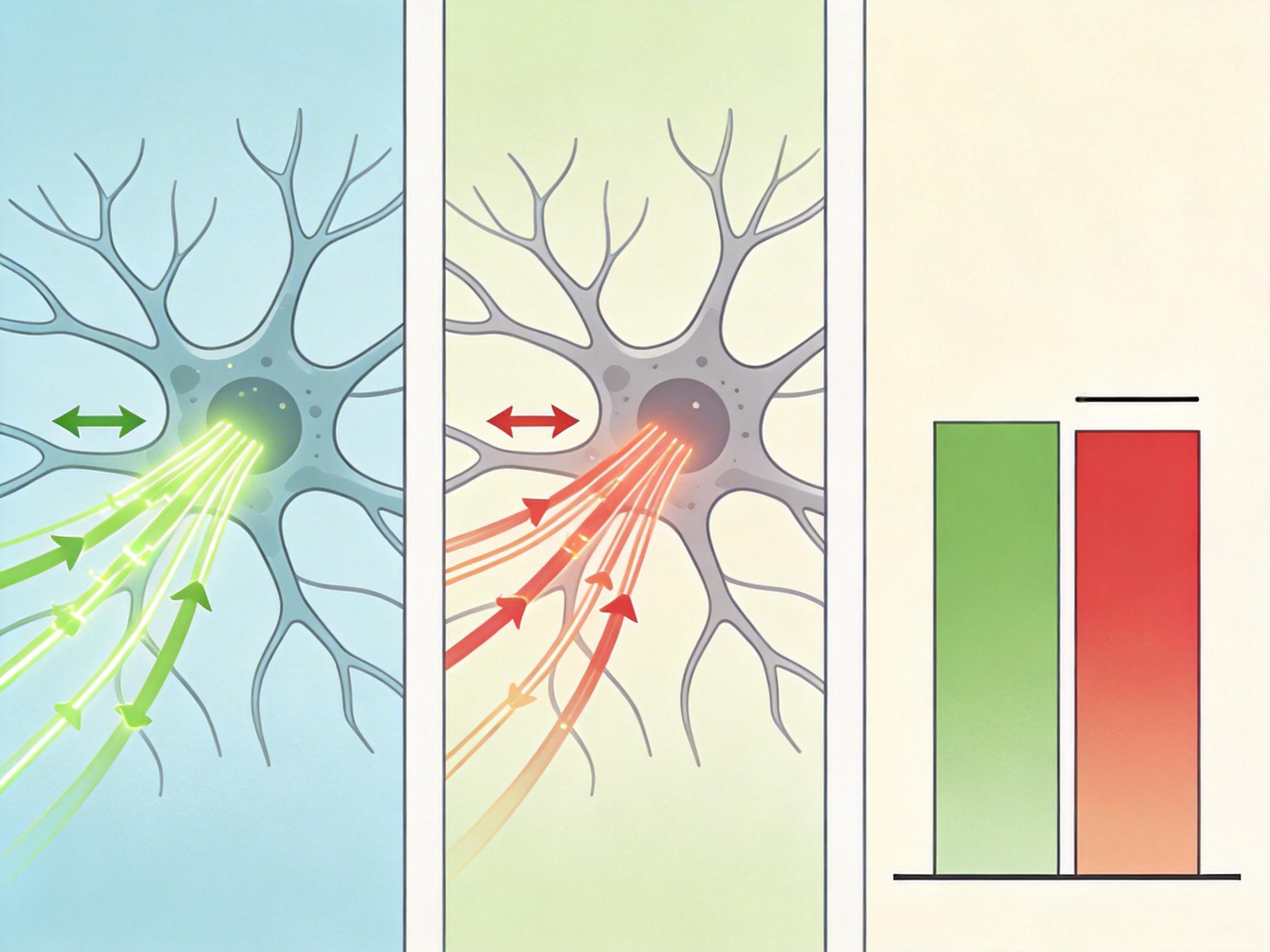
这意味着,轨迹里藏的「过程性信号」,比如怎么构造搜索词、什么时候该换方向、怎么在文档里找证据,比最终的「正确答案」更重要。失败轨迹里那些反复无效的搜索,反而能让模型学会「别踩坑」:比如失败轨迹平均调用71.7次工具,其中48.7次都是无效搜索;而成功轨迹平均只用38.4次,其中22.1次搜索就精准定位了方向。
研究者还发现,当模型打开过至少一篇「黄金文档」,不管是第几步找到的,最终准确率都能稳定在85%以上;但如果没找到黄金文档,准确率直接跌到7.9%。这也解释了为什么离线方案能成——先确保答案一定在本地语料库,再让模型练「找答案的过程」,而不是碰运气瞎搜。
过去,只有谷歌、OpenAI这种能砸钱买API、租算力的巨头,才能玩得起深度研究AI。现在OpenResearcher把这条路径彻底开源了:8张H100 GPU,8小时就能完成训练,成本直接从数万美元降到了中小团队也能负担的水平。
更重要的是,离线环境的可控性,终于让研究者能搞清楚「AI到底是怎么思考的」。之前在线搜索像个黑盒,模型搜不到答案,你根本不知道是它策略错了,还是网页上根本没答案。现在本地语料库完全可控,每一步搜索、每一次点击都能追踪,终于能系统地优化AI的研究策略——比如发现100次工具调用后,模型的准确率就到了瓶颈,再延长步数也没用。
当然,这套方案也有局限:离线语料库没法实时更新,要是研究的是刚出的新课题,黄金文档可能还没被收录;而且目前只覆盖了文本,多模态的研究轨迹还没涉及。但它已经撕开了一道口子:原来AI研究的门槛,从来不是谁的模型更大、谁的钱更多,而是谁能找到更高效的「教AI学习」的方法。
当我们还在争论「闭源模型和开源模型谁更强」时,OpenResearcher已经证明:真正的突破,往往不是在模型参数上堆数字,而是在「怎么喂数据」上换思路。
它就像给中小科研团队递了一把钥匙——不用再仰仗巨头的API,不用再为数据成本发愁,只要有好的想法,就能训练出能和闭源大模型掰手腕的研究型AI。数据不是奢侈品,是可以被高效合成的生产资料。未来的AI研究,或许会从「拼算力」的军备竞赛,转向「拼教学方法」的创新赛场。