对抗知识焦虑,从看懂这条开始
App 下载
RNA修饰算法大比武:86款工具谁在裸泳?
化学标记|算法工具评测|表观转录组学|RNA修饰|分子细胞生物学|生命科学
对抗知识焦虑,从看懂这条开始
App 下载化学标记|算法工具评测|表观转录组学|RNA修饰|分子细胞生物学|生命科学
如果说DNA是生命存储信息的蓝图,那么RNA就是执行具体任务的便签。它们从DNA蓝图中被复写出来,在细胞这座繁忙的工厂里传递指令。但这些便签并非简单复刻,上面还布满了各种化学“注解”——超过170种被称为RNA修饰的标记。这些标记如同便签上的高亮、下划线和批注,精妙地调控着指令的执行时间、地点和强度,构成了生命的“第二套语言体系”,即“表观转录组学”。
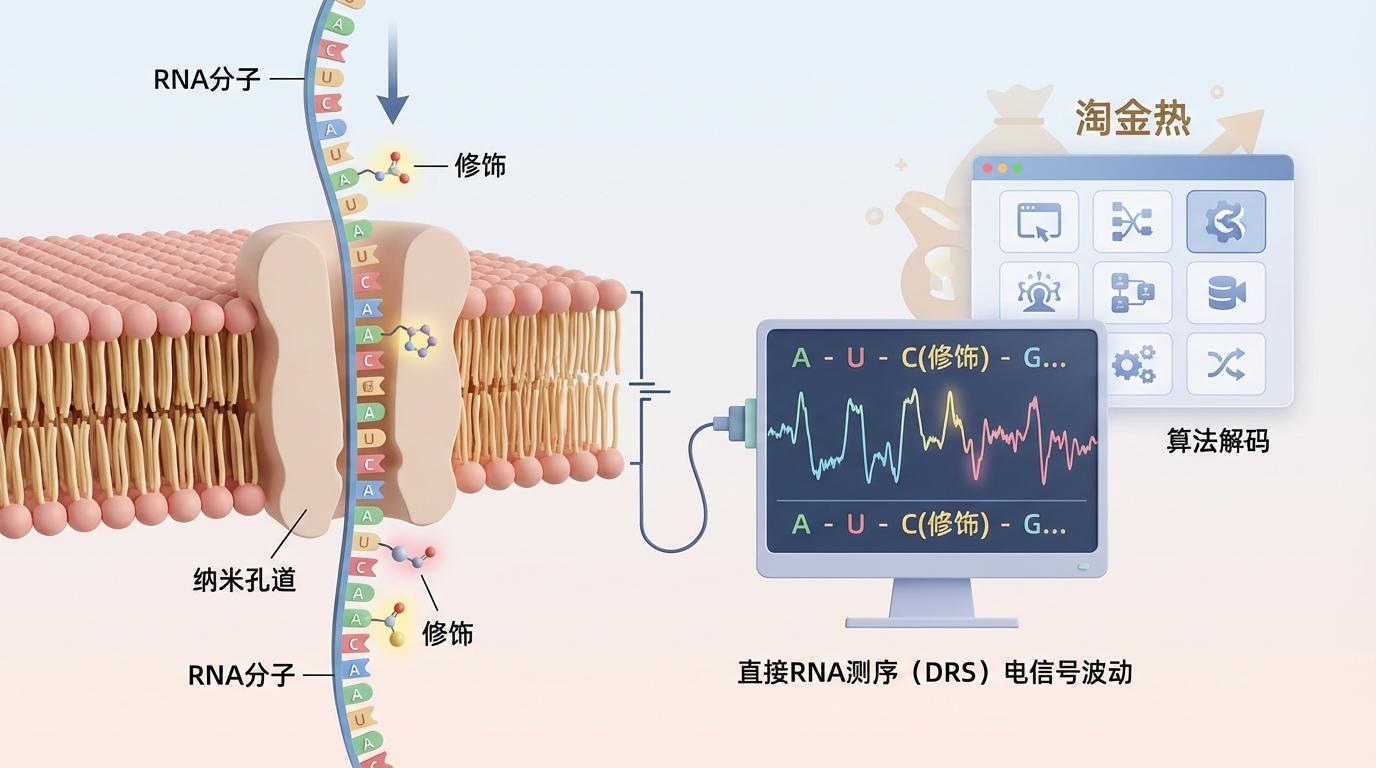
如何精准读取这些稍纵即逝的“注解”?牛津纳米孔技术公司(ONT)的直接RNA测序(DRS)技术带来了一场革命。它就像一台超高精度的扫描仪,能逐一读取RNA分子,通过其穿过微小孔道时产生的独特电信号波动,来识别碱基序列及其上的修饰。这场技术革命催生了软件开发的“淘金热”,大量算法如雨后春笋般涌现,都声称能破译这些电信号密码。
然而,一片繁荣之下,混乱与质疑也随之而来。这些算法工具的性能究竟如何?它们给出的结果是真实信号还是计算噪音?面对日新月异的测序技术硬件迭代,这些软件能否跟上步伐?整个领域仿佛一片喧嚣的西部旷野,充满了机遇,也遍布陷阱。科学家们迫切需要一张权威的地图和一把可靠的标尺。
就在近日,这场旷日持久的争论迎来了一个决定性的时刻。2025年12月10日,同济大学生命科学与技术学院的史偈君教授团队在国际顶尖期刊《自然·方法》(Nature Methods)上发表了一项里程碑式的研究。他们发起并主持了一场针对RNA修饰检测算法的、迄今为止最系统全面的“大比武”。
这项研究堪称领域内的“终极裁判”。史偈君团队首先构建了一个高质量、单碱基分辨率的基准数据集作为无可争议的“金标准”。随后,他们邀请了市面上主流的86种算法工具进入“赛场”,从准确性、生物学合理性、跨样本泛化能力和计算效率四大维度,设置了十余项严苛的评估指标,对它们进行了一次彻底的性能摸底。这场比武涵盖了m6A、假尿嘧啶(Ψ)、m5C等六种至关重要的RNA修饰类型,旨在拨开迷雾,为整个领域树立一个清晰的基准。
这场前所未有的大比武,揭示了当前RNA修饰检测领域的真实图景,既有惊喜,也暴露了深刻的挑战。
1. “温室花朵”不敌“沙场老兵”
比赛发现,许多算法工具如同在“温室”中培育的花朵,它们仅使用在实验室完美条件下合成的体外转录(IVT)RNA进行训练,一旦面对真实生物样本中复杂多变的“战场环境”,其性能便会大打折扣。而史偈君团队的策略证明,只有将纯净的IVT数据与真实的生物数据相结合进行“重训练”,才能培育出真正的“沙场老兵”。经过重训练的模型,其预测准确性和跨数据集的泛化能力得到巨大提升,尤其对于m5C和Ψ等非m6A修饰,效果尤为显著。
2. 优等生与“偏科生”并存
在所有修饰类型中,研究最广泛的m6A修饰检测工具整体表现优异,堪称“优等生”。其中,Dorado和SingleMod等模型在定性和定量分析上都展现了卓越的性能。然而,赛场上的“偏科”现象也十分严重。绝大多数用于检测其他非m6A修饰的工具,在定量准确性和跨样本泛化能力上表现出明显短板,这表明该领域的发展仍不均衡。
3. “生物学合理性”成为重要试金石
一个好的算法不仅要算得准,更要算得“合理”。研究发现,部分工具虽然在某些指标上得分不低,但其预测出的修饰位点分布却与已知的生物学规律相悖。这就像一个学生虽然答对了题,解题思路却是错的。相比之下,m6Anet模型凭借其巧妙的多示例学习(MIL)模块设计,在区分野生型与关键酶敲除的样本上表现出色,这凸显了算法设计必须与生物学知识深度融合,才能真正提升结果的解释力。
4. 算法普遍患上“脸盲症”
此次大比武首次系统性地揭示了一个普遍存在的“盲点”:当前几乎所有工具都难以在单碱基分辨率下,可靠地区分发生在同一个碱基上的不同种类的修饰。例如,同样是腺苷(A),它可以被修饰成m6A、m1A或发生A-to-I编辑。目前的算法就像患上了“脸盲症”,它们能识别出这个碱基“化了妆”,却分不清它化的究竟是哪种妆容,从而导致“模糊预测”。这为未来算法的优化指明了最迫切的方向。
更重要的是,史偈君团队的工作并未止步于评测。他们不仅诊断了问题,还给出了解决方案。
首先,研究证明了“重训练”策略是帮助算法适应技术迭代的有效途径。随着纳米孔测序技术从RNA002升级到RNA004,测序通量和电信号特征都发生了变化,导致旧算法直接失灵。而该研究提出的重训练模型,能有效适配新的RNA004数据,解决了新版本数据分析工具短缺的燃眉之急,为算法的“进化”提供了可行路径。
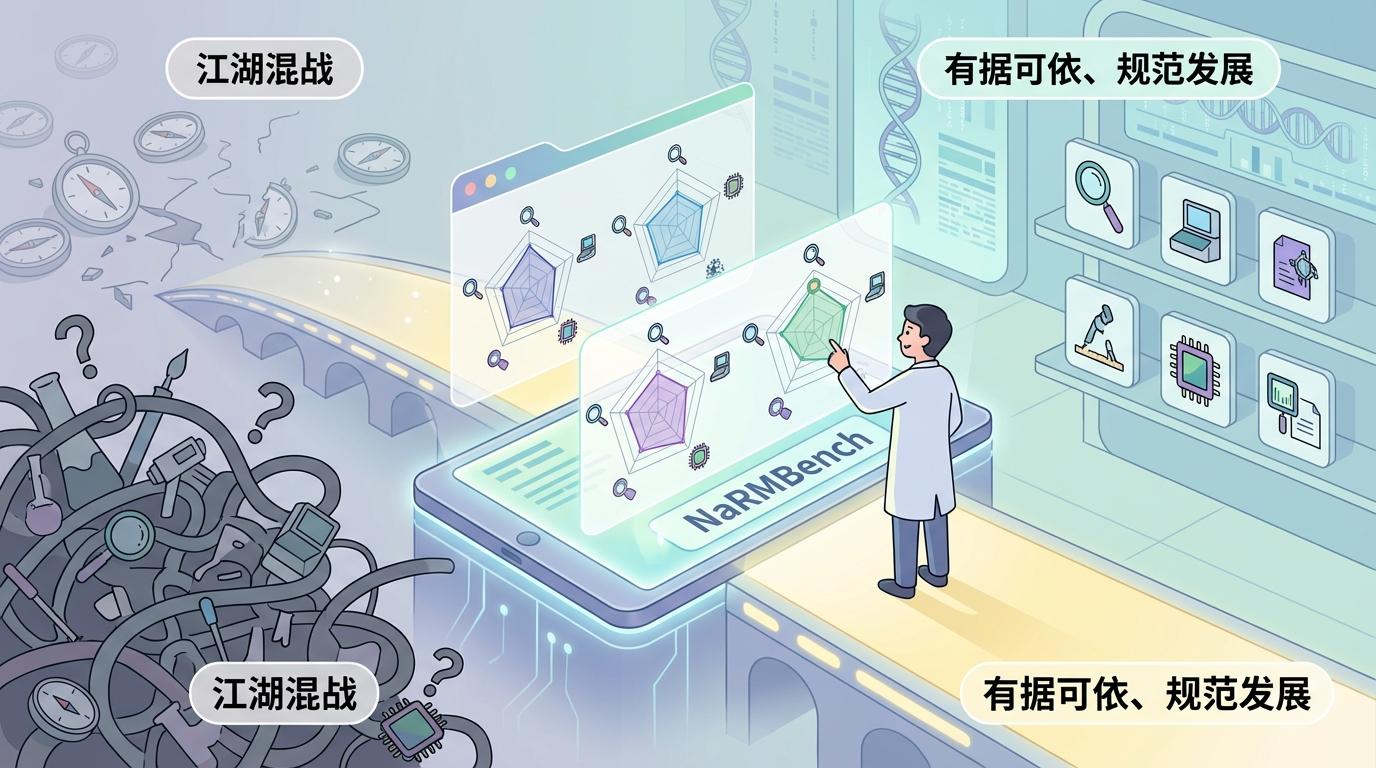
其次,为了将此次大比武的成果转化为领域内人人可用的公共资源,团队发布了一个名为NaRMBench的在线资源平台。这个平台如同一本详尽的“工具选购指南”,将86个工具的12项关键性能指标整合为交互式的雷达图。科研人员可以根据自己的实验需求,直观地比较不同工具的优劣,轻松“按图索骥”,选择最适合自己的分析利器。这标志着RNA修饰检测领域正从一个标准缺失、各自为战的“江湖混战”时代,迈向一个有据可依、规范发展的全新阶段。
史偈君团队的这项工作,如同一座灯塔,为在数据洪流中探索的表观转录组学研究者们照亮了前路。它不仅为实验科学家提供了选择工具的实用指南,也为算法开发者指明了亟待攻克的瓶颈。
未来,解码“生命第二语言”的征程依然漫长。解决算法的“脸盲症”、提升对低丰度修饰的检测灵敏度、构建能同时解析多种修饰协同作用的统一模型,将是科学家们面临的核心挑战。而这场由中国科学家主导的系统性“大比武”,正是为迎接这些挑战所铺下的最坚实的第一块基石。它通过建立标准、厘清现状,加速了整个领域从混沌走向清晰的过程,让我们离真正读懂RNA“注解”背后的生命奥秘,又近了一大步。