对抗知识焦虑,从看懂这条开始
App 下载
订个披萨也分贵贱?AI计费藏着语言经济学
全国科学技术名词审定委员会|语言经济学|AI计费规则|词元|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载全国科学技术名词审定委员会|语言经济学|AI计费规则|词元|大语言模型|人工智能
想象你对着AI助手说“帮我订个披萨”,后台悄悄记了几个细碎的计数单位。等你改口说“帮我预订一份意大利薄底萨拉斯米肠披萨”,同样的需求,账单已经悄悄涨了。这不是商家的文字游戏,是AI时代的真实计费规则——2026年3月,全国科学技术名词审定委员会把这个计数单位正式定名为“词元”,它是AI处理信息的最小单元,也是你为AI服务付费的核心依据。为什么说清楚需求反而要花更多钱?这得从AI读懂语言的底层逻辑说起。
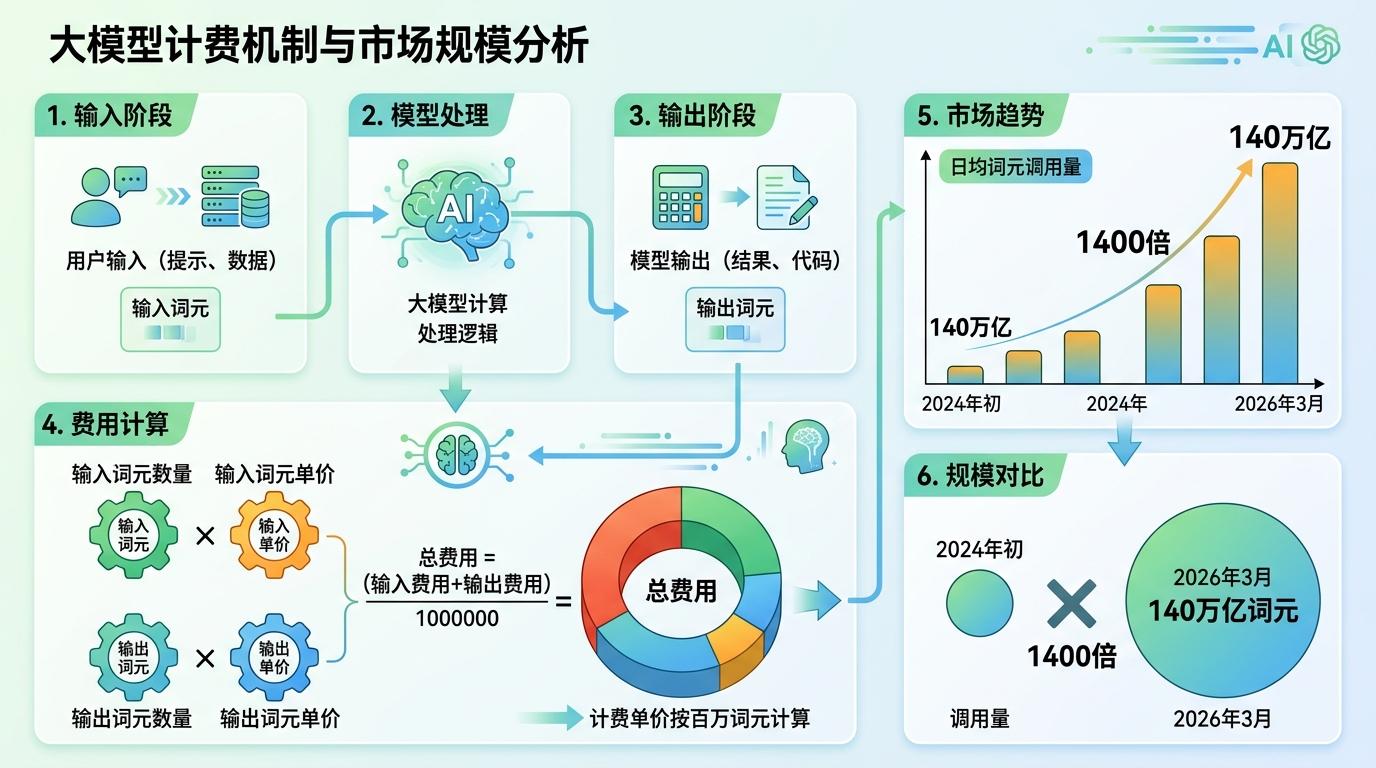
你可能习惯了按字数算钱,但AI的世界里,这个规则彻底失效了。大模型的计费公式直白得像超市收银:费用=(输入词元数×输入单价+输出词元数×输出单价)/1000000。截至2026年3月,我国日均词元调用量已经突破140万亿,是2024年初的1400倍——这些看不见的细碎单位,正在撑起一个庞大的AI经济。
要理解词元的计费逻辑,得先搞懂AI怎么“读”语言。以主流的BPE算法为例,它像个精明的打包工:先把所有文字拆成单个字符,然后反复统计合并语料里出现频率最高的字符对。“的”“中国”这种高频组合会被打包成一个词元,而“萨拉斯米肠”这种生僻长词,只能被拆成一串零散的小单元。
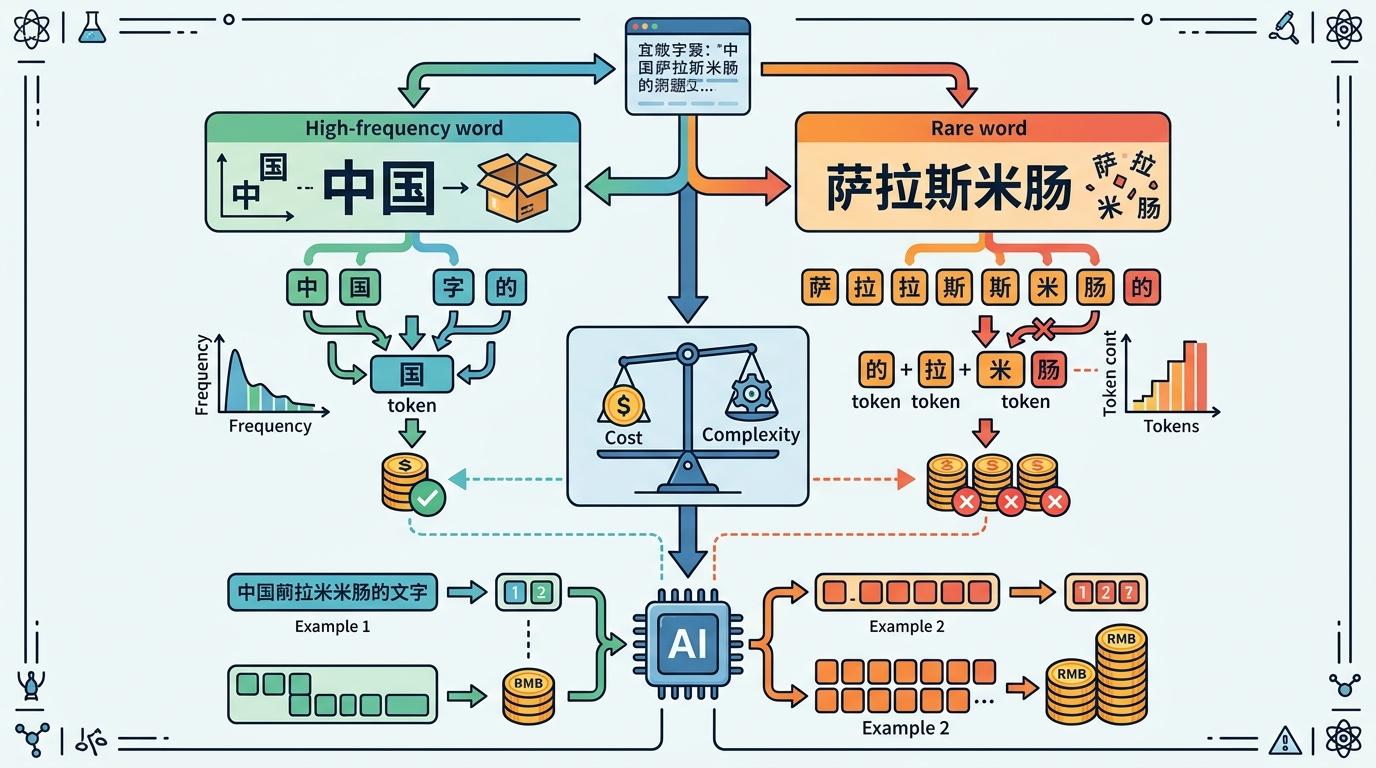
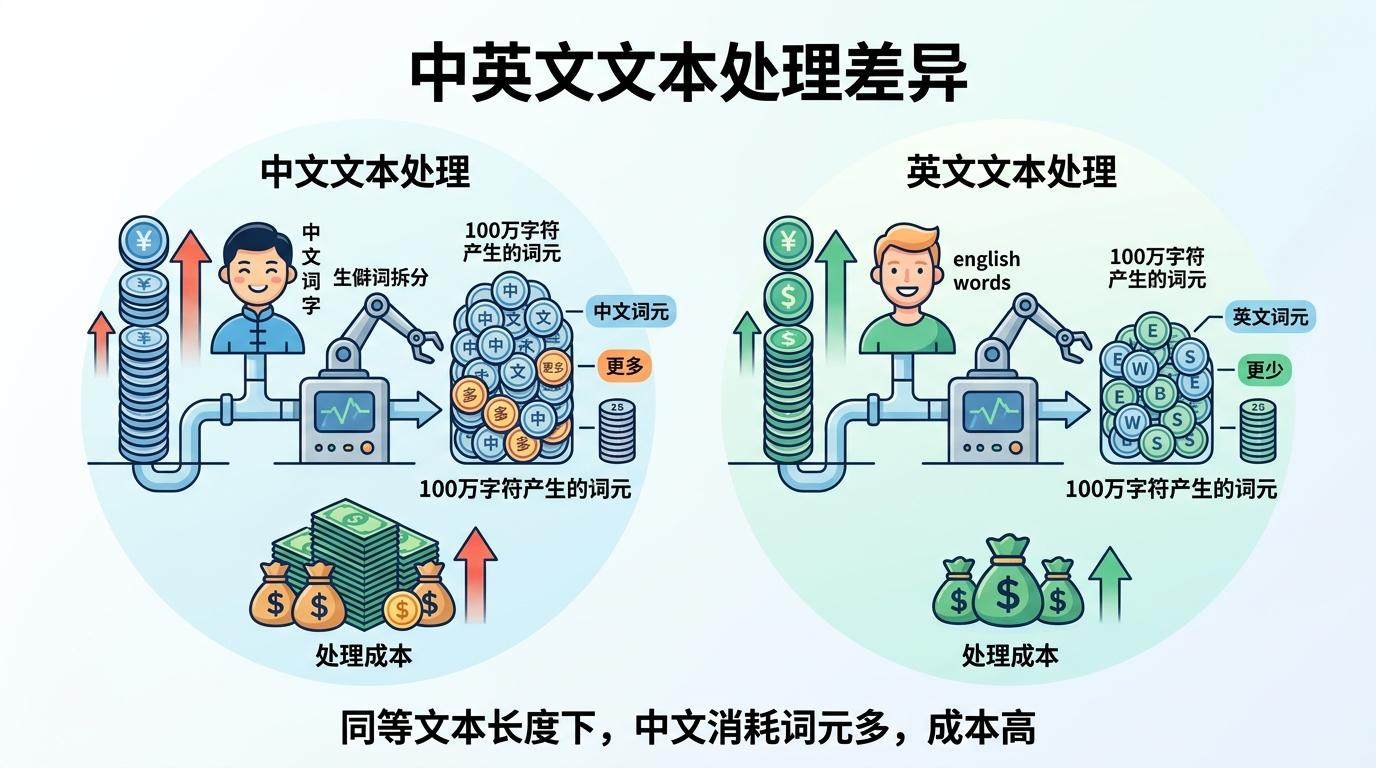
这就解释了开头的披萨悖论:越具体的描述,越容易触发生僻词拆分,产生的词元数就越多,账单自然水涨船高。实测数据显示,同样长度的中文文本,消耗的词元数是英文的2-2.7倍,用GPT-4o处理100万字符的中文,要比英文多花约50%的钱。
这种“高频词便宜,生僻词贵”的计费机制,本质是AI世界的“语言经济学”——你为表达的精准度付费。对AI来说,处理生僻词需要调动更多算力去拆解和理解,成本自然更高;而高频词是它烂熟于心的“常用零件”,处理起来既快又省。
但从用户角度看,这意味着一场表达习惯的革命。以前我们总说“把话说清楚”,现在对着AI,你得学会“把话说得划算”:用“电脑”代替“电子计算机”,用“订披萨”代替一长串口味描述,能直接砍掉大半词元消耗。阿里云的上下文缓存功能更狠,命中缓存的词元价格只有普通输入的1/10,重复查询时保持上下文连贯,能省下不少钱。
当然,这种机制也不是没争议。有开发者吐槽,专业领域的术语几乎全是“高价词元”,写一份技术文档的成本,比写普通散文高好几倍。而中文用户的“额外成本”也一直被诟病:因为没有空格分隔词边界,AI需要做更多拆分工作,导致同样的内容,中文用户要比英文用户多付近一倍的钱。
2026年3月“词元”的官方定名,不只是一个术语的统一,更是AI产业精细化的标志。这个看不见的小单元,已经成了连接技术、成本和商业的枢纽:它是AI处理信息的最小单位,是算力消耗的计量标尺,也是用户付费的核心依据。
中国AI产业正在靠这个小单位弯道超车。OpenRouter平台数据显示,2026年3月全球前十的AI模型中,中国模型占了61%的调用量,价格却只有美国主流模型的1/10到1/20。低廉的词元成本,让AI代理、长文本处理这类高消耗应用得以快速普及——毕竟,当处理100万词元只需要几块钱时,企业愿意大胆尝试更多AI场景。
但繁荣背后也有隐忧。目前词元计费的隐性成本依然模糊:日志记录、重复上下文传递、检索过多文档,都可能让词元消耗悄悄翻倍。有调研显示,62%的企业无法准确预测每月的AI支出,部分项目的预算超支甚至达到500%以上。AI FinOps(AI财务运营)正在成为企业的必修课,实时监控词元消耗、设置使用配额、优化模型路由,成了控制成本的关键。
当你下次对着AI说“帮我订个披萨”时,不妨想想后台那些正在被计数的词元。它们不再只是技术处理的细碎单位,而是重新定义语言价值的经济符号——在AI时代,每一个精准的词汇,都标着价格。
词元的出现,其实是技术对语言的一次反向塑造:我们开始习惯用“成本最优”的方式表达,而AI也在通过计费机制,悄悄筛选着它“喜欢”的语言。这种技术与语言的双向博弈,最终会催生一套全新的数字时代沟通规则。精准表达不再是免费的权利,而是需要计算成本的选择。