对抗知识焦虑,从看懂这条开始
App 下载
AI演员批量上岗,表演正在失去肉身
短剧行业|表情动作数据|数字替身|AI虚拟演员|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载短剧行业|表情动作数据|数字替身|AI虚拟演员|AIGC|人工智能
2026年春,某视频平台的AI艺人库计划把“演员一年接4部戏”推上热搜——不是靠分身术,是让AI复刻演员的脸、表情和动作,替他们“跑场”。当网友喊着“疯了”的时候,短剧行业里的AI虚拟演员已经悄悄演了小半年。有人把自己的演技、经历全喂给AI,造出一个永远不会累的“数字替身”;资本在喊着效率翻倍,观众却在问:那些靠肉身熬出来的哭戏、摔戏、把自己逼到失常的《黑天鹅》,以后还能看到吗?
你可以把AI演员的生成逻辑理解成“高级模仿秀”:先把演员的表情、动作、声音拆解成几百万个数据点,再用算法把这些数据重新排列组合,生成新的表演片段——就像把一本小说拆成单字,再用单字拼出另一篇故事。
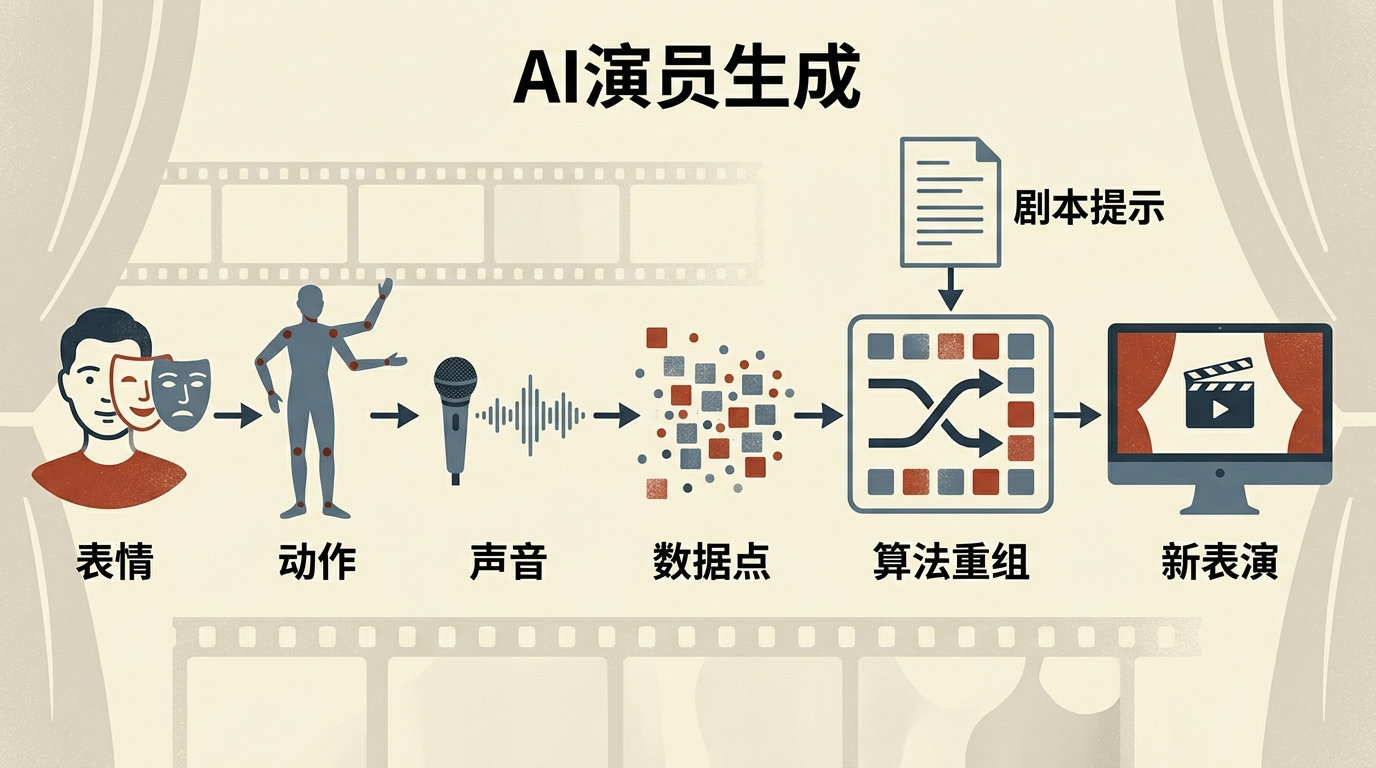
但真实的机制比这更精确。AI靠的是生成式模型,它会先“学习”几十万小时的人类表演数据,记住“悲伤时嘴角下拉的角度”“愤怒时眉毛抬起的高度”,再根据剧本提示,把这些数据拼接成连贯的表演。 现在的AI已经能精准复制基础情绪:悲伤、愤怒、快乐这些“大表情”的识别率能到90%以上。但它搞不定那些藏在细节里的复杂情绪——比如《黑天鹅》里娜塔莉·波特曼那种“恐惧里带着贪婪,脆弱里藏着疯狂”的眼神,那种靠几个月节食、练舞熬出来的“肉身质感”,是AI学不会的。这不是技术问题,是数据里根本没有这些“非标准化”的情绪。
AI演员只是文化算法化的一个切口。现在的短剧行业,从写剧本、分镜头到后期剪辑,AI已经能包办一半流程:输入“甜宠+霸总”,它能在10分钟里生成3版剧本;给一段素材,它能自动剪出符合节奏的片段。 平台喜欢这套逻辑——算法能精准算出“哪类剧情点击率最高”“哪个演员的脸最吸粉”,然后照着数据生产内容。就像工厂流水线,把“爆款元素”拆成零件,再组装成新的“爆款”。 但这也带来了两个看不见的代价:一是内容越来越像“预制菜”,所有甜宠剧都是“霸总爱上灰姑娘”,所有悬疑剧都是“反转再反转”,没有了创作者的个人表达;二是文化的“公共性”在消失——算法只给你推你喜欢的内容,你再也不会像以前那样,和朋友争论同一部剧的好坏,因为你们看的根本不是同一批内容。
面对AI的冲击,演员真正的护城河不是脸,是“隐性知识”——那些无法用数据量化的、靠肉身经验积累出来的能力。 比如老戏骨说的“台上一分钟,台下十年功”,不是说练了多少动作,是练出了“对舞台的感知”:知道怎么用眼神和观众互动,怎么用停顿控制节奏,怎么在忘词的时候即兴圆场。这些知识藏在肌肉记忆里,藏在现场的氛围里,AI学不会,因为它没有肉身,也没有“现场感”。

现在已经有演员开始反过来用AI:用AI生成不同版本的表演片段,自己再从中挑选最有“人味”的部分;或者用AI分析观众的反馈,调整自己的表演细节。他们不再和AI比“谁演得像”,而是把AI当成工具,守住“用肉身传递情感”的核心。
当AI能批量生产演员的时候,我们才突然发现:我们爱的从来不是“完美的表演”,是表演里的“人味”——是演员哭到颤抖的肩膀,是台词里不小心破音的哽咽,是那些不完美却真实的瞬间。 肉身不会被数据取代,情感也不会被算法复刻。有温度的表演,永远需要有温度的肉身。 未来的舞台上,AI会是配角,而那些带着汗水、泪水和体温的表演,才是文化最珍贵的底色。