对抗知识焦虑,从看懂这条开始
App 下载
AI大模型的算力底座,不是超级计算机而是它
数据中心|GPU集群|千亿参数大模型|国产厂商|分布式AI云基础设施|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据中心|GPU集群|千亿参数大模型|国产厂商|分布式AI云基础设施|AI算力|人工智能
当你对着智能客服说出复杂诉求,当工厂里的机械臂精准预判故障,当医生通过AI影像快速定位病灶——你以为这些是某台超级计算机在后台发力?其实支撑这些场景的,是一套分散在全球节点的分布式AI云基础设施。一家国产厂商即将在年中推出新一代这类基础设施,它能让AI的算力像水电一样随用随取,而不是被锁在某个昂贵的机房里。为什么分布式架构,反而成了AI规模化落地的核心?
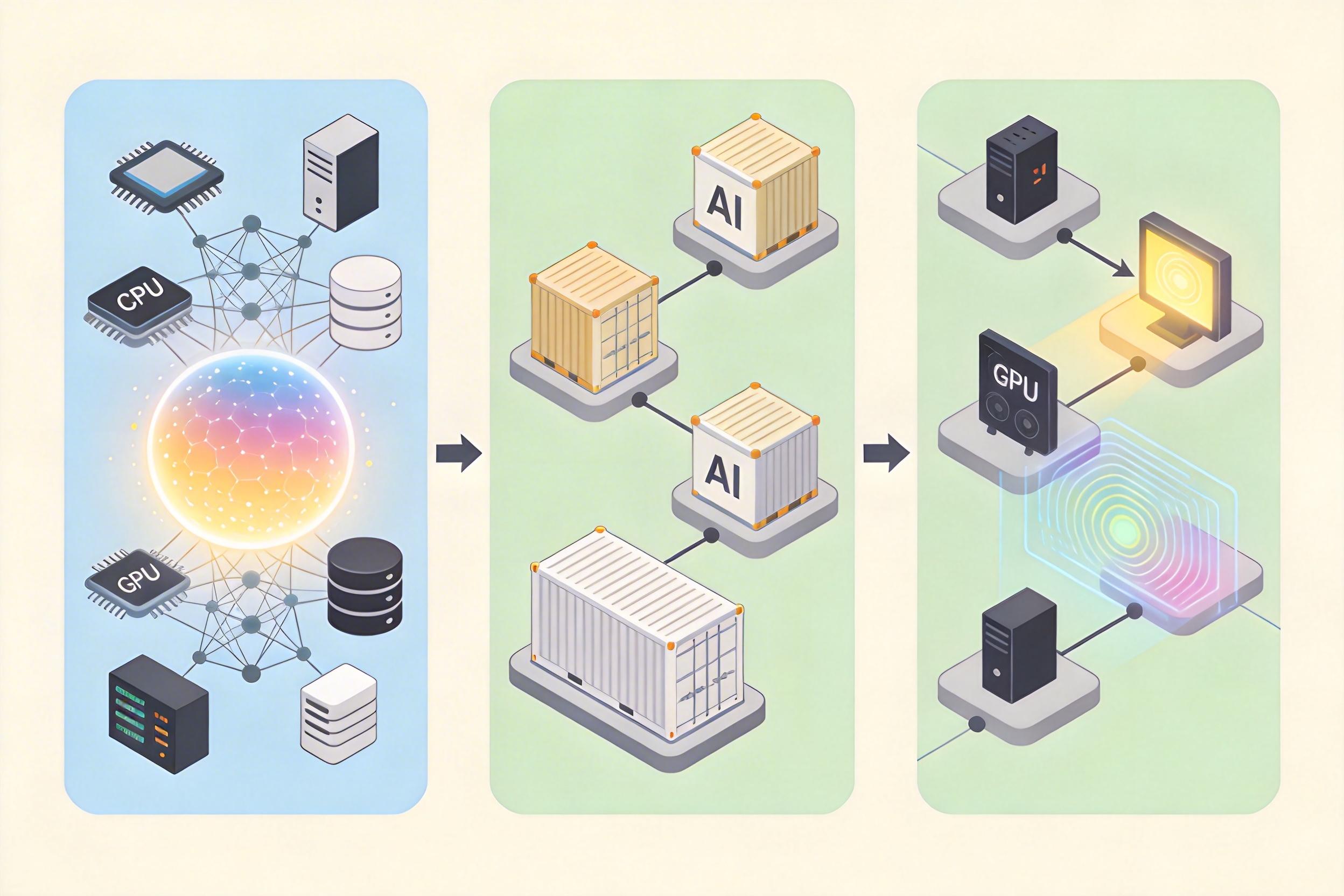
答案藏在AI的“成长焦虑”里。如今训练一个千亿参数的大模型,需要的算力相当于把上万个GPU同时开动数月——如果把这些算力集中在一个数据中心,不仅要解决电力、散热的物理极限,还要面对单点故障带来的全盘风险。分布式架构的本质,是把庞大的计算任务拆解成无数小块,分散到不同地域的服务器节点上并行处理,就像把一场万人宴会拆成百个社区家宴,既能灵活扩容,也不会因为一桌的问题搞砸整场。
这种拆解的背后,是一套精密的协同机制。首先是资源池化——把CPU、GPU、存储、网络等硬件资源像水一样汇进一个大池子,AI任务需要多少就抽多少,不用再为单个项目单独采购设备。其次是容器化编排,用标准化的“容器”打包AI模型和运行环境,让它能在任何节点上顺畅运行,就像无论什么品牌的快递盒,都能通过物流网络送到目的地。最后是自动化运维,AI系统会实时监控每个节点的状态,一旦某个GPU宕机,立刻把任务转移到空闲节点,甚至能预判故障提前调度,比人工运维快上百倍。
但分布式架构并非完美无缺。数据在不同节点间传输时,延迟和安全始终是两道坎——金融交易的实时反欺诈要求数据在毫秒内完成计算,医疗影像的隐私性又不允许原始数据跨地域流动。为此,联邦学习、隐私计算等技术开始嵌入基础设施,让AI模型可以在数据所在地完成训练,只共享模型参数而不触碰原始数据;边缘计算则把部分算力下沉到离用户最近的节点,比如工厂车间、医院诊室,进一步缩短响应时间。
这些技术的迭代,正在让AI从实验室里的“奢侈品”变成各行各业的“必需品”。未来你可能不会再听到“某公司拥有多少GPU”,而是“某行业的AI算力利用率提升了多少”。毕竟,支撑AI的从来不是单点的极致算力,而是让算力像空气一样无处不在的分布式网络——这才是智能时代真正的基础设施。