
19 小时前
19 小时前
闭上眼睛,想象你站在一间有100个物体的房间里:先左转90度看见花瓶,再右转180度看见书架,最后再左转90度——你会立刻反应过来,自己转回了最初的方向,面前该是一开始的桌子。这是人类不用思考就能完成的空间推理,但当北京理工大学的研究者把同样的问题抛给当前最先进的大语言模型和视觉语言模型时,结果却让人意外:这些动辄千亿参数的AI,最好的成绩也只能达到86%的准确率,远低于人类的100%。为什么AI连这种‘小儿科’的空间任务都搞不定?答案藏在模型的‘黑箱’里。
你可以把层间探测理解为给AI的神经网络做‘逐层CT扫描’——研究者在模型的每一层后面接上一个简单的分类器,专门检测这一层是否编码了关键信息:比如‘当前是左转还是右转’‘转了多少度’‘现在面朝哪个绝对方向’。
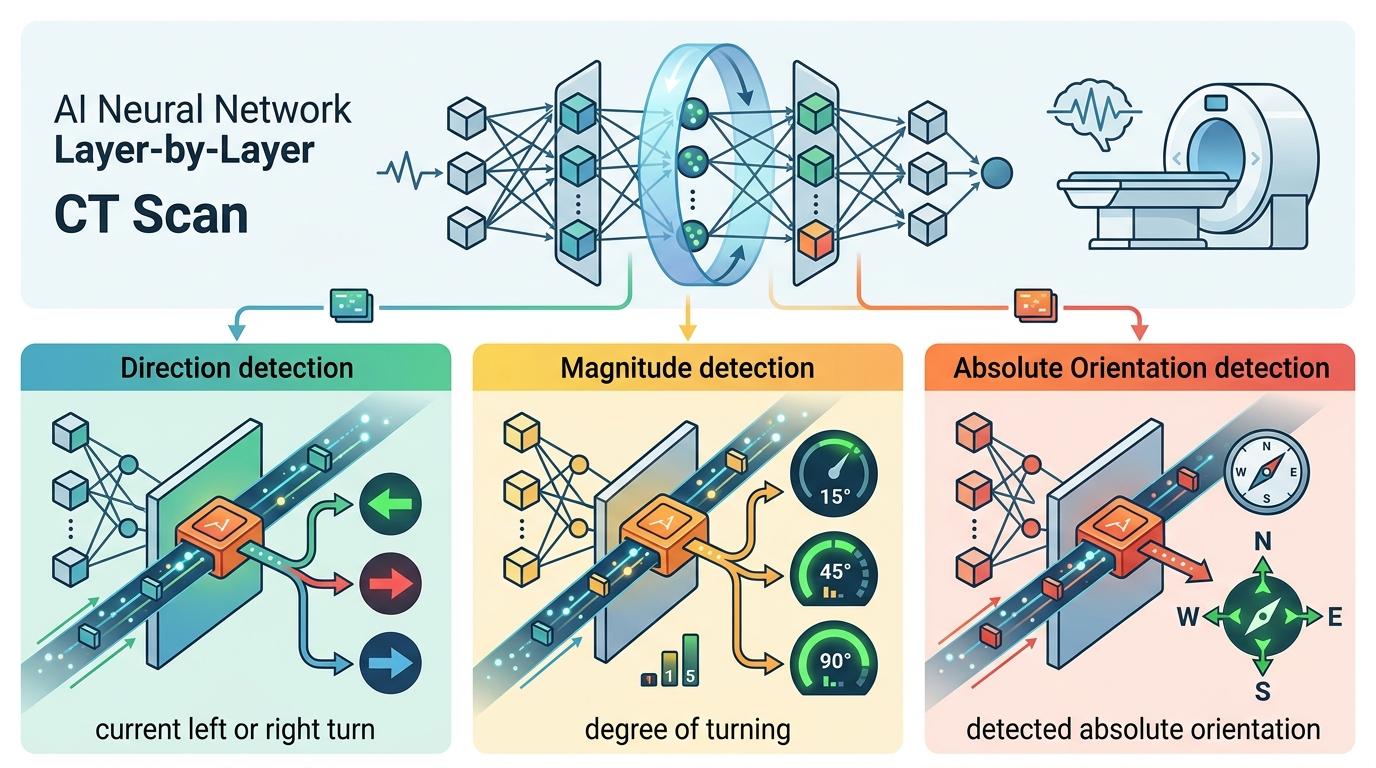
结果很有意思:模型几乎能完美记住‘左转90度’这种明确指令,准确率超过99%;但它辛辛苦苦计算出来的‘当前面朝哪个方向’的信息,在模型的中低层还能被检测到,到了深层网络却突然模糊甚至丢失了。 这就像一个学生在草稿纸上算出了正确的中间步骤,却在誊写最终答案时把关键数字给忘了。更关键的是,研究者发现,模型的浅中层负责‘计算方位’,而深层的少数注意力头才是真正负责‘决策答案’的核心——这意味着,AI的‘感知’和‘决策’环节,出现了脱节。
为了精准定位到底是哪些注意力头在起作用,研究者用上了路径修补技术——这是一种因果干预的方法,简单说就是给模型制造‘平行世界’:准备两份只有最后一步旋转方向不同的题目,然后把模型处理其中一份时某个注意力头的激活值,替换成处理另一份时的激活值,看最终答案会不会跟着改变。 如果替换某个头后,答案发生了剧烈变化,就说明这个头是决定输出的‘关键先生’。对Qwen2.5-VL-7B的896个注意力头逐一测试后,结果令人震惊:真正影响空间推理输出的头不到10%,而且几乎全部集中在深层网络。
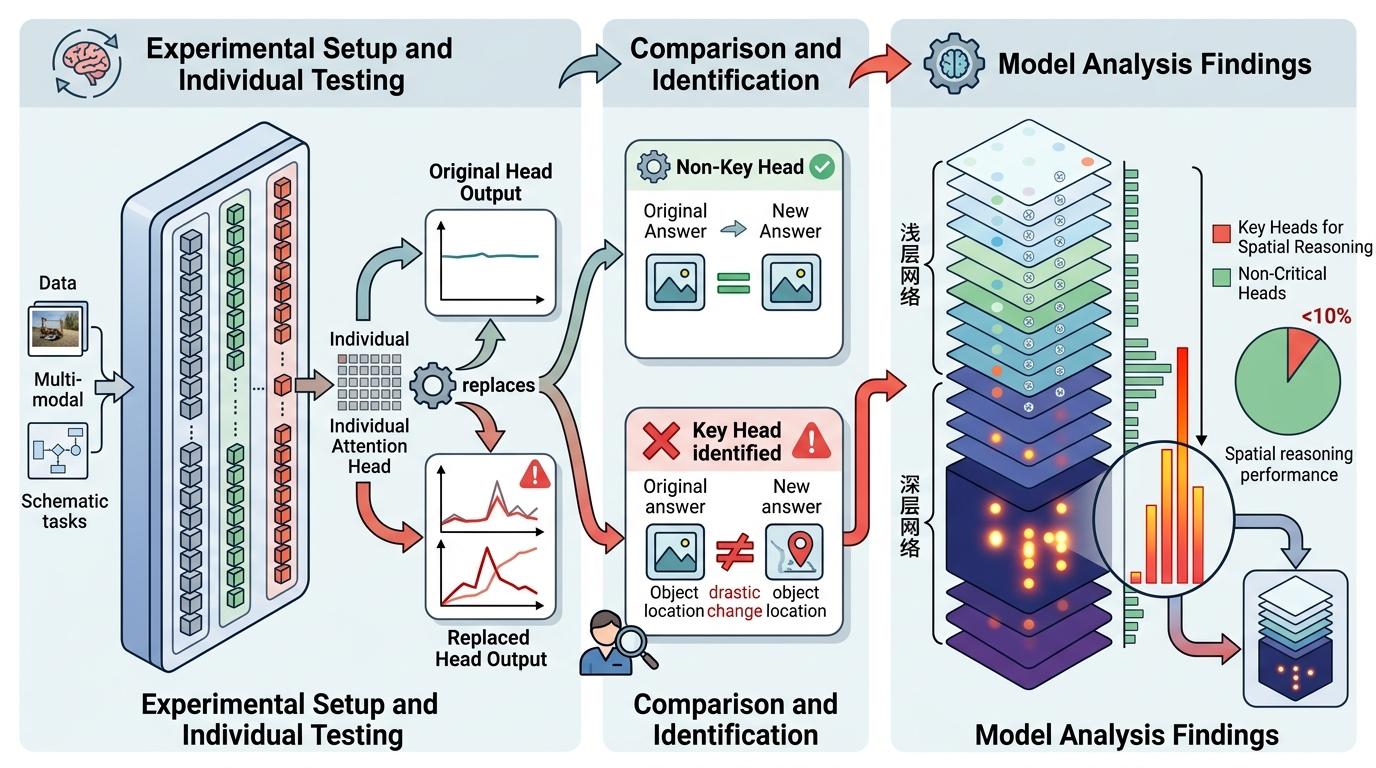
更有意思的是,这些关键头还分了工:有的负责把所有可能的答案都列出来,有的负责根据方位信息选对答案,还有的专门关注‘不确定’的语义——这是模型在安全对齐训练中学会的‘谨慎本能’,有时会干扰最终输出,导致答非所问。
既然找到了病灶,治疗方案就清晰了:不用让整个模型重新训练,只需要给那些关键注意力头单独‘开小灶’——这就是选择性微调。 传统的全参数微调不仅要花费数倍的GPU时间,还容易让模型‘捡了芝麻丢了西瓜’:学会了空间推理,却忘了之前的通用知识。而选择性微调只更新关键头的参数,其他部分全部冻结。 实验结果显示,这种方法让Qwen2.5-VL-7B在空间推理任务上的准确率从48.7%提升到了80.1%,GPU时间只需要全微调的一半,而且模型的通用能力不仅没下降,还略有提升。更意外的是,只用纯文本数据做的选择性微调,居然还能提升模型在视觉空间任务上的表现——这印证了认知心理学的双重编码理论:语言和视觉的空间能力是可以相互强化的。 当然,这种方法也有局限:目前的提升只在规整的虚拟房间任务中有效,面对真实世界里更复杂的动态空间场景,AI的泛化能力还需要验证。
当我们惊叹AI能写诗、能编程时,它却在人类最基础的空间认知能力上栽了跟头。这背后的启示,远不止‘AI还不够聪明’这么简单:我们总习惯用参数规模和通用能力来衡量AI的水平,却常常忽略了那些人类与生俱来的‘底层能力’,才是智能最核心的基石。 更值得深思的是,这次研究的价值,不在于让AI多答对了几道空间题,而在于它提供了一种全新的思路:与其盲目堆参数、喂数据,不如先给AI做一次‘体检’,找到它真正的短板再精准发力。 看见AI的‘盲区’,比让它学会新技能更重要。
点击充电,成为大圆镜下一个视频选题!