对抗知识焦虑,从看懂这条开始
App 下载
单图生成可漫游3D世界,AI解决两大顽疾
深度估算|虚拟空间生成|单图3D重建|英伟达团队|Lyra 2.0|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载深度估算|虚拟空间生成|单图3D重建|英伟达团队|Lyra 2.0|多模态视觉|人工智能
想象一下:你拍了一张客厅的照片,上传后就能在虚拟空间里绕到沙发背后,推开阳台门,甚至走进隔壁从未在照片里出现过的卧室——整个过程画面连贯,沙发的花纹、书架的位置从不会突然变样。这不是科幻电影的特效,是英伟达团队最新的Lyra 2.0实现的功能。此前AI生成3D场景时,要么走几步就“失忆”,要么画面慢慢“跑偏”,而Lyra 2.0用两个巧妙设计,把这些顽疾解决了。
你可以把AI生成3D场景的过程,想象成一个人在陌生城市里走路:如果只凭记忆里的零星画面,很容易迷路或记错路牌。Lyra 2.0给AI配了个“3D地图向导”——它会给每生成的一帧画面估算深度,转化成稀疏的3D点云存在“缓存”里,而且每帧的点云独立存储,避免早期误差污染全局。
当AI要生成新视角画面时,这个“向导”会计算:从当前位置看,缓存里哪些历史帧的场景和现在重叠最多?比如你现在站在客厅门口,它会找出之前在餐厅、走廊生成的画面。更聪明的是,它不直接把历史画面扭曲变形给AI当参考——那样会把拉伸、空洞的瑕疵也带进去——而是传递一张“坐标对应图”,告诉AI:“你要画的这个像素,对应历史帧里的那个位置”。
AI则像个经验丰富的画师,拿着“向导”给的坐标线索和历史画面参考,自己画出既符合空间逻辑、又细节逼真的新视角。这就把“找路”和“画画”的职责彻底分开,解决了AI“走几步就忘事”的空间遗忘问题。
解决了“失忆”,还要对付“跑偏”——AI逐帧生成时,每一步的微小误差会像传话游戏一样,越传越歪,最后画面颜色、形状全变样,这就是时间漂移。
Lyra 2.0的办法是“提前模拟出错”:训练时,它会故意给AI喂一些带噪声的“瑕疵历史帧”,比如把之前生成的画面加一点模糊或颜色偏差,让AI在“不完美的基础”上继续生成。就像让厨师用有点糊的食材练习做菜,练得多了,就算真遇到不完美的原料,也能做出合格的菜。
具体来说,训练时会有30%的概率,给历史帧的潜在表示加噪声,再让AI把这个“污染版”去噪,得到模拟的瑕疵历史,然后基于这个瑕疵历史生成干净的新帧。这样训练出的AI,在实际生成时遇到误差累积,就能自动纠正,而不是让偏差越来越大。实验数据显示,这种方法让Lyra 2.0在生成800帧以上的长视频时,画面依然保持稳定,对比其他方法的模糊、变形,优势明显。
解决了两大顽疾,Lyra 2.0还打通了从视频到可使用3D资产的最后一步。它用3D高斯泼溅技术,把生成的视频转换成高质量的3D模型——这种技术用无数个可调整的3D高斯点来表示场景,渲染速度快、细节丰富。
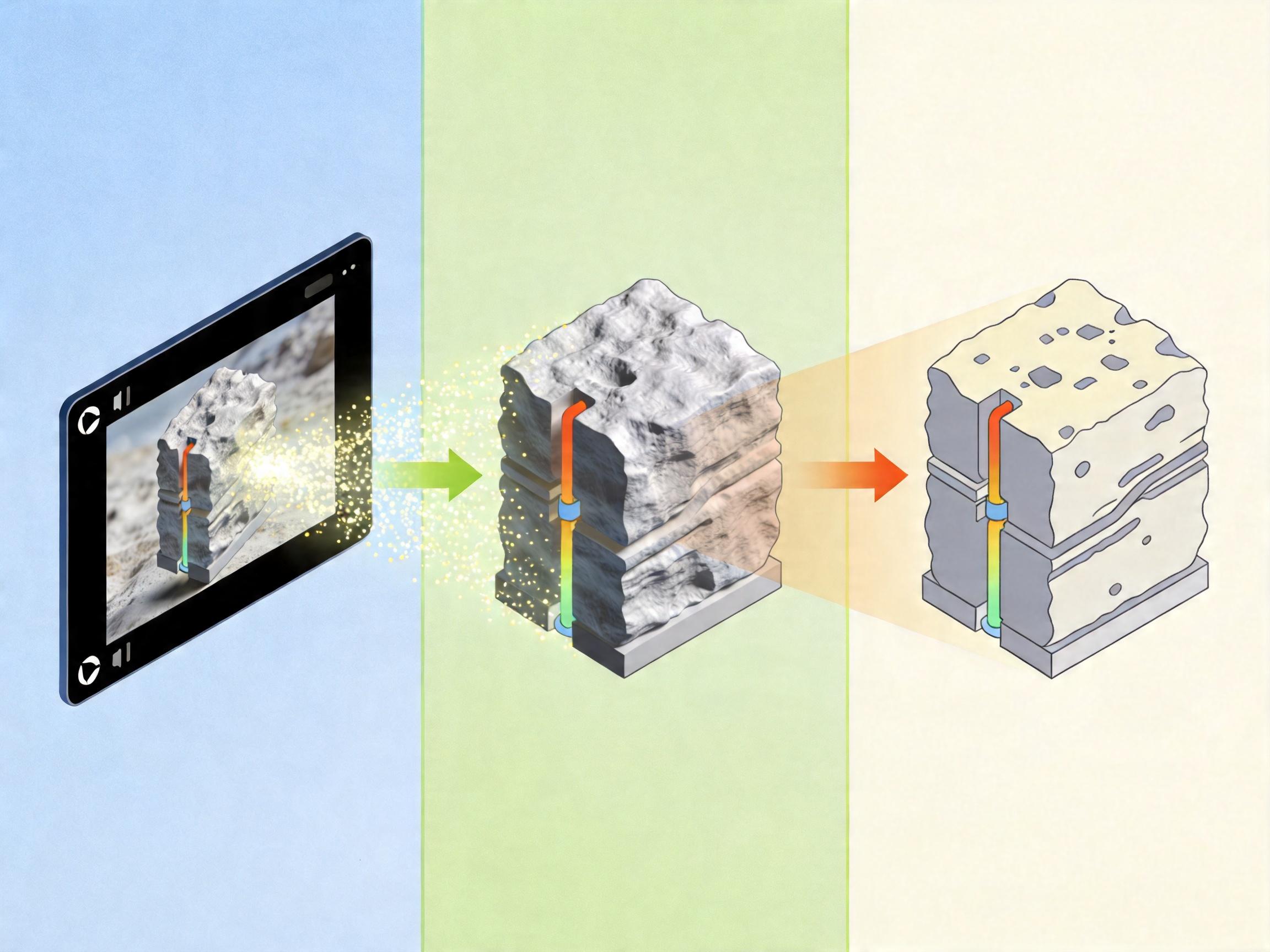
为了应对生成视频里的微小不一致,团队还微调了Depth Anything v3深度估计模型,让它更适应AI生成的内容,重建出的3D场景几乎没有漂浮物和空洞。对比其他方法生成的破碎3D模型,Lyra 2.0的成果可以直接导入游戏引擎或机器人仿真平台,比如英伟达的Isaac Sim,用来训练机器人导航。

当然,它也有局限:如果输入照片里有透明物体或均匀纹理的区域,深度估计会出错,进而影响整个生成过程;而且它对GPU算力要求极高,普通消费级设备还跑不起来。但不可否认,它已经把“单图生成可探索3D世界”从概念推到了实用的边缘。
从只能生成几秒的短视频,到能支撑自由探索的3D世界,Lyra 2.0的突破,本质上是让AI学会了“用空间逻辑思考”,而不是只凭像素记忆画画。它没有追求更复杂的模型,而是通过职责分离和自增强训练,把现有技术的潜力发挥到了极致。
未来,或许我们拍一张街景,就能生成整个可漫游的虚拟街区;设计师画一张草图,就能直接得到可交互的3D游戏场景。AI造世界,从“画像素”到“懂空间”。 这不仅是技术的进步,更是虚拟内容创作门槛的一次大跨越——毕竟,让想象力落地的成本越低,我们能抵达的虚拟世界就越广阔。