对抗知识焦虑,从看懂这条开始
App 下载
插32帧也不卡,视频超分的效率革命来了
视频插帧|GS-STVSR模型|2D高斯泼溅|华为诺亚实验室|中科大|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视频插帧|GS-STVSR模型|2D高斯泼溅|华为诺亚实验室|中科大|多模态视觉|人工智能
你有没有过这种经历:想把一段模糊卡顿的老视频转成4K流畅版,AI工具说“没问题”,但渲染1秒的视频要等上好几秒——插的帧越多,等得越久。这不是你的设备不够强,而是传统视频超分技术的天生缺陷:每生成一个像素,都要让神经网络跑一次计算,插帧数量和分辨率直接决定了计算量的爆炸式增长。
但现在,中科大与华为诺亚实验室的研究者,用一种叫“2D高斯泼溅”的技术,把这个死结给解开了。他们的GS-STVSR模型,推理速度几乎不随插帧数量增加而变慢,在极端插32帧的情况下,比之前最好的方法还快3倍以上。这不是小修小补的优化,而是一次范式级的效率突破。
传统的连续时空视频超分(C-STVSR)方法,依赖的是隐式神经表示(INR):把视频看作一个连续的信号场,用神经网络学习从坐标(x,y,t)到像素颜色的映射。这就像用最细的针尖,一个点一个点地戳出一幅巨幅油画——每一个像素、每一个时刻都要单独“查询”神经网络,插帧越多、分辨率越高,工作量就呈线性甚至平方级增长。
而2D高斯泼溅技术,相当于把针尖换成了智能喷枪。它不用一个个画像素,而是用一堆“高斯小团子”来表示图像:每个团子有自己的位置、颜色、大小和方向(由协方差矩阵描述)。渲染时,只要把这些团子按规则“泼”到画布上,相互重叠融合,就能形成最终的图像。更关键的是,这个渲染过程是GPU高度优化的光栅化操作,一旦团子的参数确定,渲染几乎是瞬间完成的。
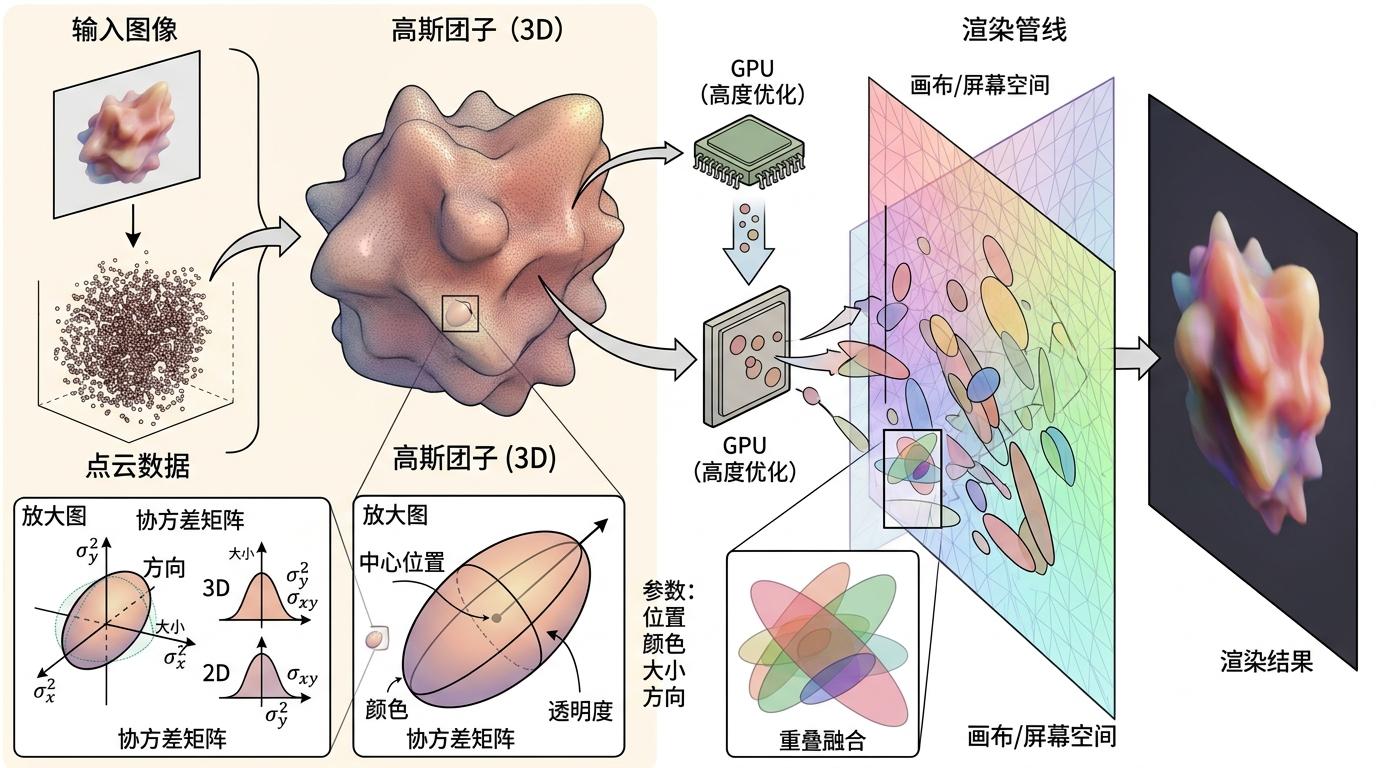
GS-STVSR的核心思路,就是把这种“泼墨”逻辑引入视频超分:不再查询每个时空坐标的像素,而是建模这些高斯小团子如何随着时间连续运动、变色和变形。只要掌握了团子在任意时刻的状态,就能用“光速”渲染出对应的高清帧。
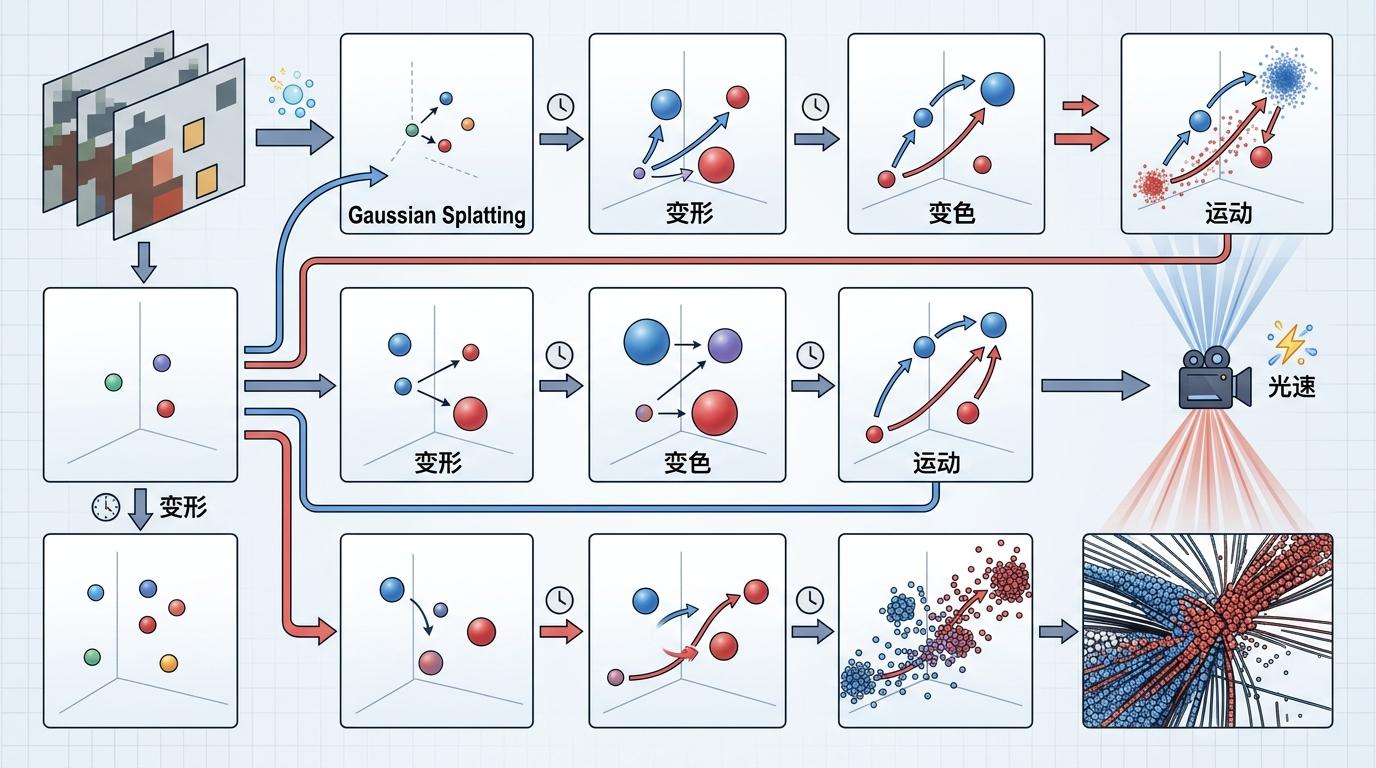
研究者们发现了一个反直觉的现象:高斯小团子的“形状”(由协方差矩阵描述)在时间上异常稳定——相邻帧之间,团子的大小、拉伸和旋转的相关性接近0.99,远高于像素颜色的变化幅度。这意味着,视频里的物体纹理、边缘等结构信息,其实比颜色变化平缓得多。
基于这个洞察,他们设计了一个极其轻量的协方差重采样对齐模块:不用复杂模型预测协方差的变化,而是先从预定义的“形状模板库”(协方差先验库)里,取出起始帧和结束帧的团子形状,再用一个单层卷积生成融合权重,对模板库的基础形状进行加权组合,就能得到中间时刻的团子形状。这个“偷懒”的设计,既保证了形状的自然平滑,又把计算量降到了最低。
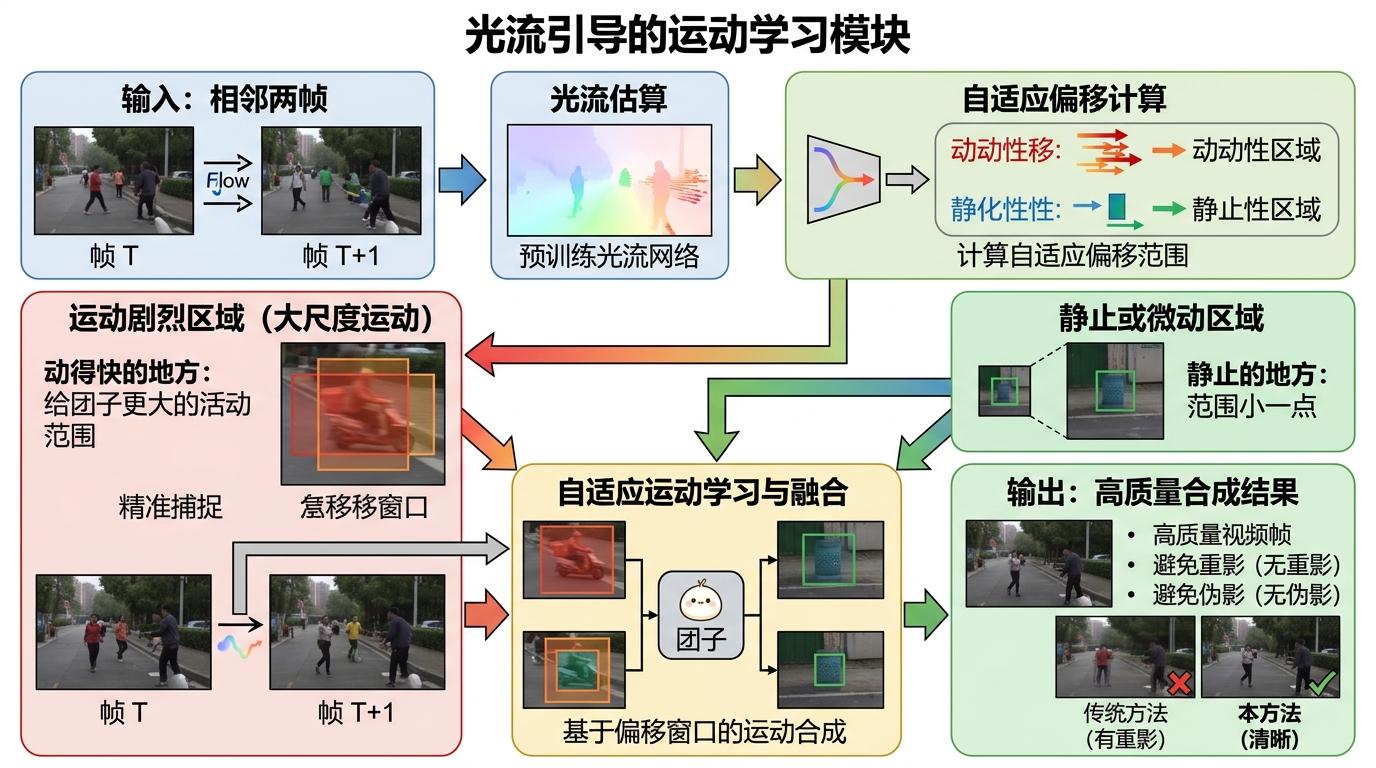
而对于变化剧烈的位置和颜色,研究者们则用了光流引导的运动学习模块:先通过预训练的光流网络估算两帧间的运动,再用自适应偏移窗口——动得快的地方给团子更大的活动范围,静止的地方范围就小一点——精准捕捉大尺度运动,避免了传统方法中常见的重影和伪影。
理论设计的优势,最终要靠数据说话。在Vid4、GoPro和Adobe240等标准数据集上,GS-STVSR实现了画质和效率的双重领先:
在画质上,它的PSNR和SSIM指标全面超越之前的SOTA方法BF-STVSR,而且参数量更少(12.67M vs 13.47M);在泛化能力上,即便是训练时没见过的时空缩放组合(比如×16时间/×4空间),它依然能保持最佳性能;而最核心的效率优势,体现在推理时间上——常规插2到8帧时,耗时几乎恒定;极端插32帧时,速度比BF-STVSR快3倍以上。
当然,它也有局限:目前主要针对两帧输入进行插值,对于更长的视频序列,还需要滑动窗口等策略;性能也部分依赖预训练光流网络的准确性。但这些都不影响它的里程碑意义:它证明了,从“密集查询”到“显式基元演化”的范式转变,能同时带来画质和效率的提升。
当我们还在为“用更多算力换更好画质”的逻辑习以为常时,GS-STVSR给了我们一个新的思路:有时候,换一种“看世界”的方式,比堆算力更有效。它没有在传统的像素查询赛道上继续内卷,而是用高斯小团子的演化,绕开了效率瓶颈的死胡同。
换一种表示,就换了一种可能。 这个道理,不仅适用于视频超分,也适用于所有被效率瓶颈困住的技术领域。未来,当我们在直播、云游戏、AR/VR里享受流畅的高清视频时,或许就能想起今天这场“用喷枪代替针尖”的效率革命。