对抗知识焦虑,从看懂这条开始
App 下载
复旦新方法:AI不用重训也能精准屏蔽不良内容
内容安全|概念擦除|文生图模型|新加坡国立大学|复旦大学|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载内容安全|概念擦除|文生图模型|新加坡国立大学|复旦大学|大语言模型|人工智能
当你输入“一场激烈的街头冲突”,AI却生成了带血腥画面的暴力场景——这曾是文生图模型最棘手的安全漏洞。2025年的一项研究显示,主流开源模型生成有害内容的概率最高可达50.56%,即便输入正常提示,也有0.5%的概率“跑偏”。更麻烦的是,现有技术能轻松让AI忘记“皮卡丘”,却对“暴力”“色情”这类宽泛概念束手无策:要么擦除不彻底,要么连正常内容也一并毁掉。直到复旦与新加坡国立大学的团队拿出了新方案——不用修改模型参数,仅靠推理时的引导,就能让AI精准绕开所有不良内容的变体。
要理解这个问题,得先搞懂什么是**概念擦除**——简单说,就是让训练好的文生图模型,不再生成特定概念对应的图像。比如输入“皮卡丘”,模型只会生成普通黄色电老鼠,而非有版权的宝可梦形象。
现有技术处理“皮卡丘”这类窄概念时得心应手,因为它们在模型的“语义地图”(高维嵌入空间)里是一个明确的点,擦除只要“抹掉”这个点就行。但“暴力”不一样,它是一张由血腥、枪战、骚乱等无数子概念织成的网,每个子概念都是地图上独立的小簇。用单一方向去擦除,就像用一根筷子夹西瓜——只能碰掉一小块,剩下的依然完好。
更糟的是,粗暴擦除还会引发“过度清除”:为了屏蔽暴力,连“激烈对抗的体育比赛”也会被改成温吞的画面;为了删除色情,连正常的人体艺术也会被扭曲。用户要的是“安全”,不是“阉割”后的创作。
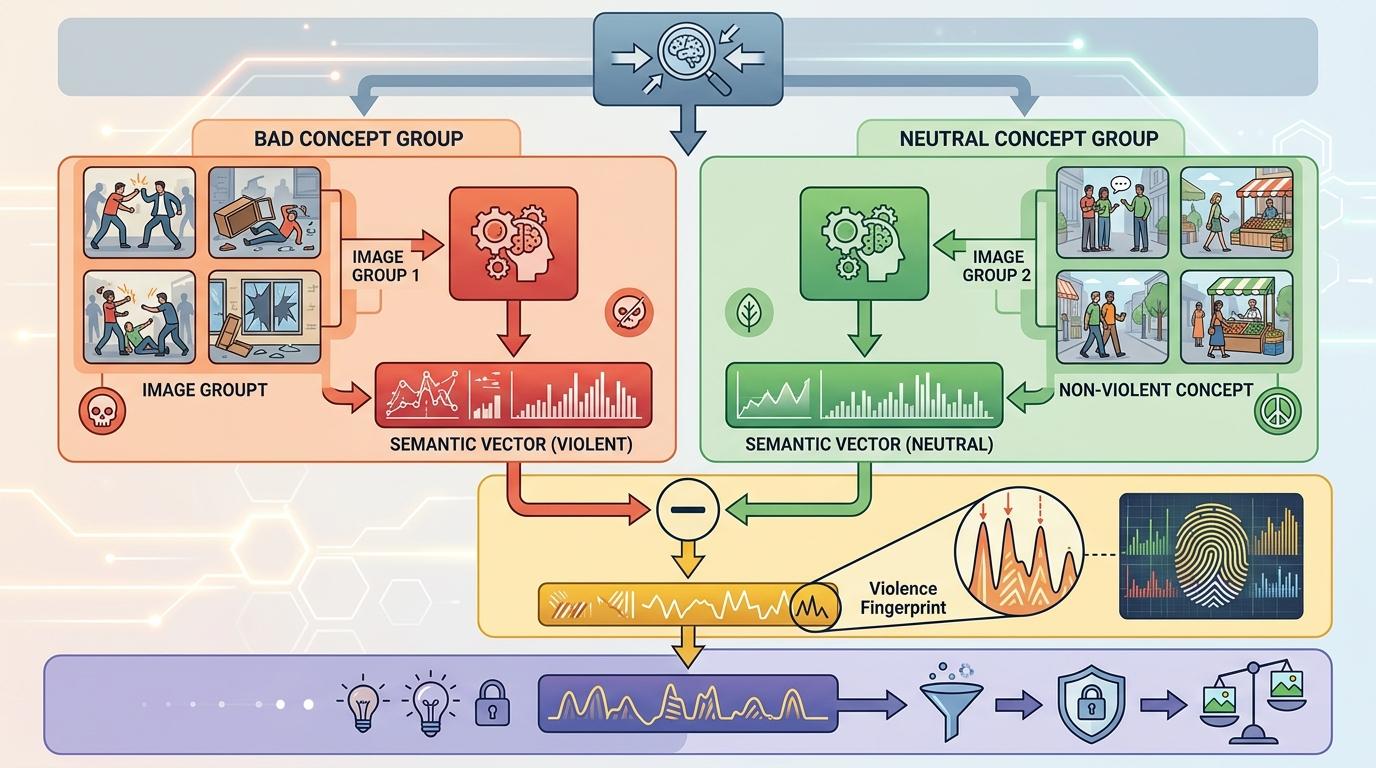
复旦团队的解法是分而治之:既然一个方向搞不定,就用多个“概念原型”把宽泛概念拆碎。
你可以把原型理解为概念的“典型样本”——“暴力”的原型包括血腥画面的向量、枪战场景的向量、街头骚乱的向量,每个原型都对应一种具体的不良模式。整个原型构建过程像在给AI做“心理画像”:
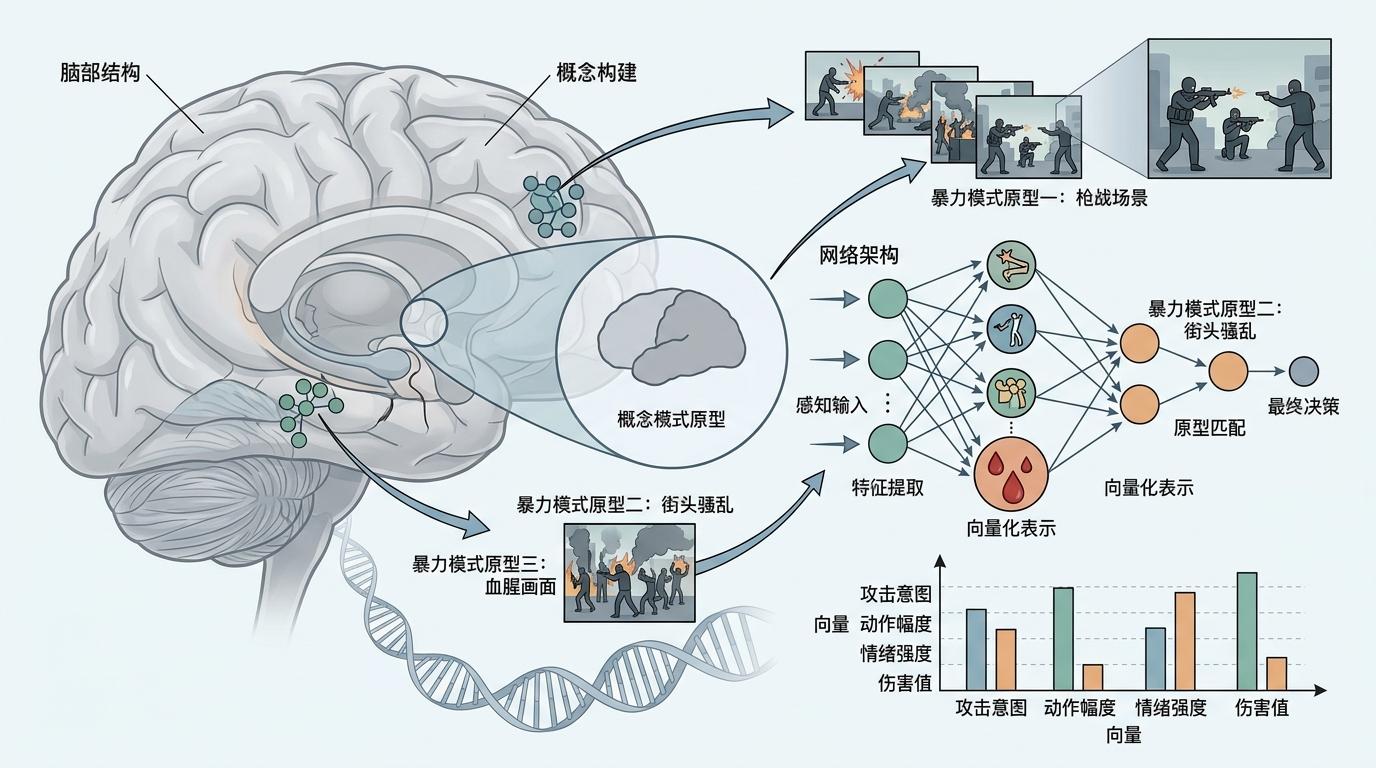
到了推理阶段,这套系统就成了AI的“安全导航”:用户输入提示后,系统先把提示和所有文本原型比对,找到最相似的那个,然后在扩散模型的去噪过程中,主动把生成轨迹推离这个原型的方向。它相当于在AI的生成指令里加了一句:“按这个要求画,但绝对不能碰这个区域”。
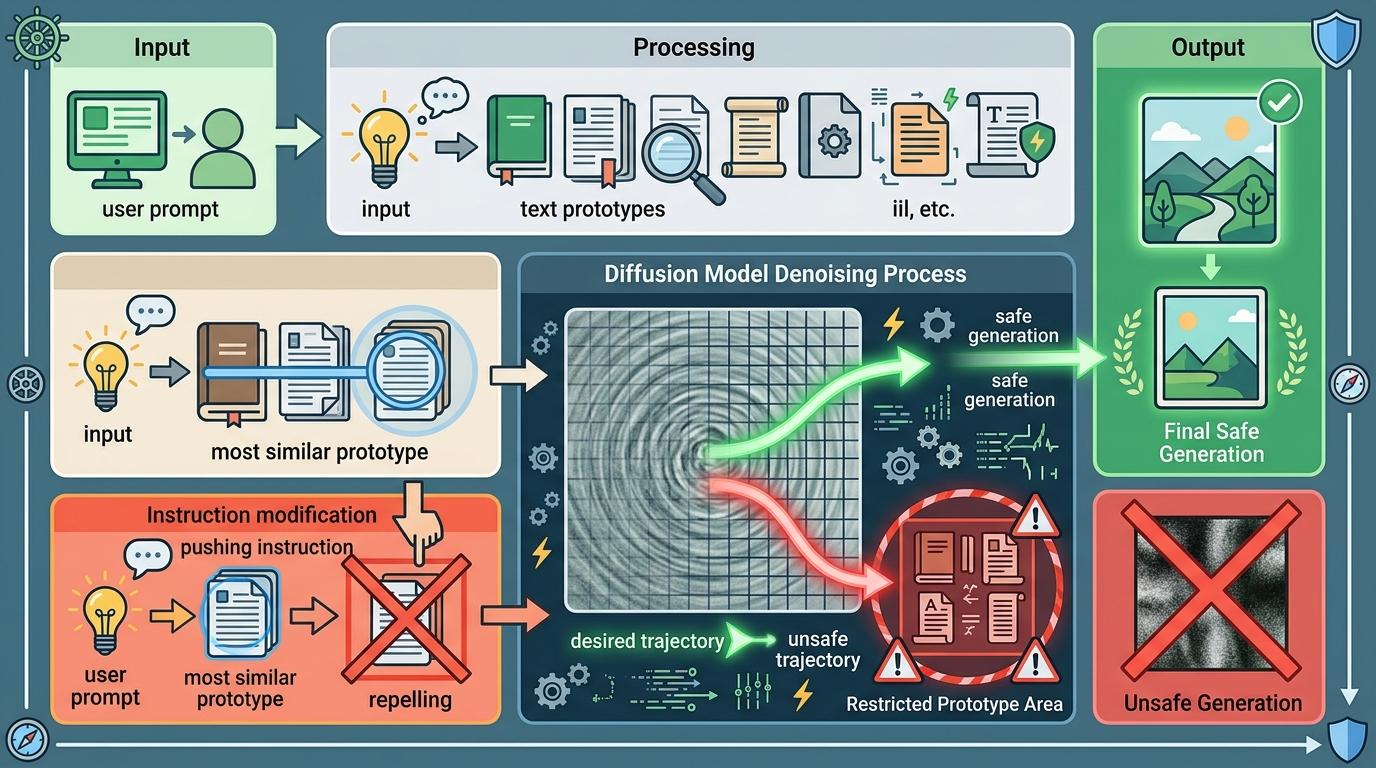
这套方法的妙处在于不用修改模型参数——所有干预都在推理时完成,就像给手机装了个过滤软件,不用换手机也能拦截垃圾信息。实验显示,它能把I2P数据集上的不良内容检测率从35.6%降到5.2%,同时生成图像的美学评分还能保持最优。
但这并非完美的解决方案。最明显的局限是对罕见模式的漏检:如果有人用一种从未出现在训练数据里的方式描述暴力,比如“红色液体溅在白色墙壁上的巷战”,系统可能因为找不到匹配的原型而失效。
另一个问题是原型的“保质期”:不良内容的表达一直在进化,今天的原型可能挡不住明天新出现的隐喻。比如AI学会用“破碎的玩偶”暗示暴力,旧的原型就无法识别这种新变体。
更值得关注的是,这套方法依然没解决“擦除与创作的平衡”难题。在测试中,当原型数量超过16时,虽然擦除更彻底,但生成图像会出现轻微的伪影和细节缺失;而如果原型数量太少,又会回到擦除不彻底的老问题。这本质上是所有内容安全技术的共同困境:安全的边界,就是创作自由的边界。
当我们在谈论AI内容安全时,其实是在谈论如何给创造力装一个“安全护栏”——它不能是一堵墙,挡住所有可能的风险,也挡住了所有意外的惊喜。复旦团队的原型引导方法,就是这样一根更灵活的护栏:它不用毁掉AI的创作能力,只是在它快要越界时轻轻拉一把。
更重要的是,它让我们看到了AI内容安全的新方向:与其事后删除不良内容,不如事前引导AI避开风险;与其暴力修改模型的“记忆”,不如给它装一套精准的“导航”。安全不是限制,而是让创作走得更远的底气。未来的AI内容治理,终究要在“防”和“放”之间找到最微妙的平衡——而这,才是真正的技术难点。