
19 小时前
19 小时前
你有没有过这种经历:深夜拍的照片糊得像蒙了层砂,用AI去噪后,脸是清楚了,可发丝的纹理、远处路牌的字还是一团模糊?过去我们总以为,要解决这种问题,得靠更复杂的模型、更多的参数——就像给电脑换个更高级的CPU。但合肥工业大学等团队在2026年NTIRE图像去噪挑战赛上的成果,彻底推翻了这个常识:他们没改动成熟Restormer模型的任何结构,只靠喂数据、调训练、改推理,就让去噪性能暴涨了3.366分贝。这相当于把一张模糊到只能看个轮廓的照片,修成了能数清睫毛的高清图。这到底是怎么做到的?
你可以把AI模型想象成一个学画画的学生:如果只让他临摹100张静物画,他画风景肯定不行;但要是给他看14万张从2K到8K的高清图,涵盖城市街景、山川湖海、微观纹理,他对光影和细节的理解会完全不一样。
这支团队就是这么干的。他们放弃了过去常用的三四套标准数据集,一口气整合了7大来源的图像:既有DIV2K、Flickr2K这类老牌高清图库,也有专门的户外场景集OST、8K分辨率的LIU4K-v2和NKUSR8K,甚至还有包含8.7万张图的大规模修复专用集LSDIR,总规模超过14.3万张。为了不让8K大图“噎着”模型,他们还聪明地把8K图裁剪成2K子图,既保留了发丝、毛孔这类精细纹理,又保证了训练的稳定性。
这不是简单的“堆数据”——他们还给数据做了“精细化筛选”:只留分辨率超过900×900的图,用算法评估图像清晰度,甚至用CLIP模型平衡语义多样性,确保模型学的不是重复的“模板”,而是真实世界的万千细节。
数据准备好了,怎么喂也是学问。直接把14万张图一股脑塞给模型,就像让小学生直接读大学教材,肯定消化不了。团队设计了一套“两阶段渐进式训练法”,像练级打怪一样稳扎稳打。

第一阶段:夯实基础。他们从官方预训练的Restormer模型出发,先用DIV2K、Flickr2K、OST和LSDIR这四套“基础教材”训练。训练时,图像块尺寸从256慢慢涨到768——就像先让学生画巴掌大的小画,再练全开的大画幅,让模型逐步学会捕捉更大范围的上下文信息。这一阶段的目标,是让模型建立起扎实的“图像修复直觉”,不会把人脸修成模糊的面团。
第二阶段:开拓视野。等模型在基础数据集上练稳了,再引入LIU4K-v2、NKUSR8K和DIV8K这三套“进阶教材”。这些超高清图里的纹理细节更丰富,比如树皮的裂纹、布料的编织纹路,能逼着模型跳出“舒适区”,学会处理更复杂的场景。为了不让模型卡在局部最优解里,他们还交替用L1、L2和小波变换损失函数训练,就像换不同的老师批改作业,让模型能从更多角度修正错误。
这套训练法的效果是显著的:在验证集上,仅数据扩充和两阶段训练带来的性能提升,就占到了总提升的99%以上。
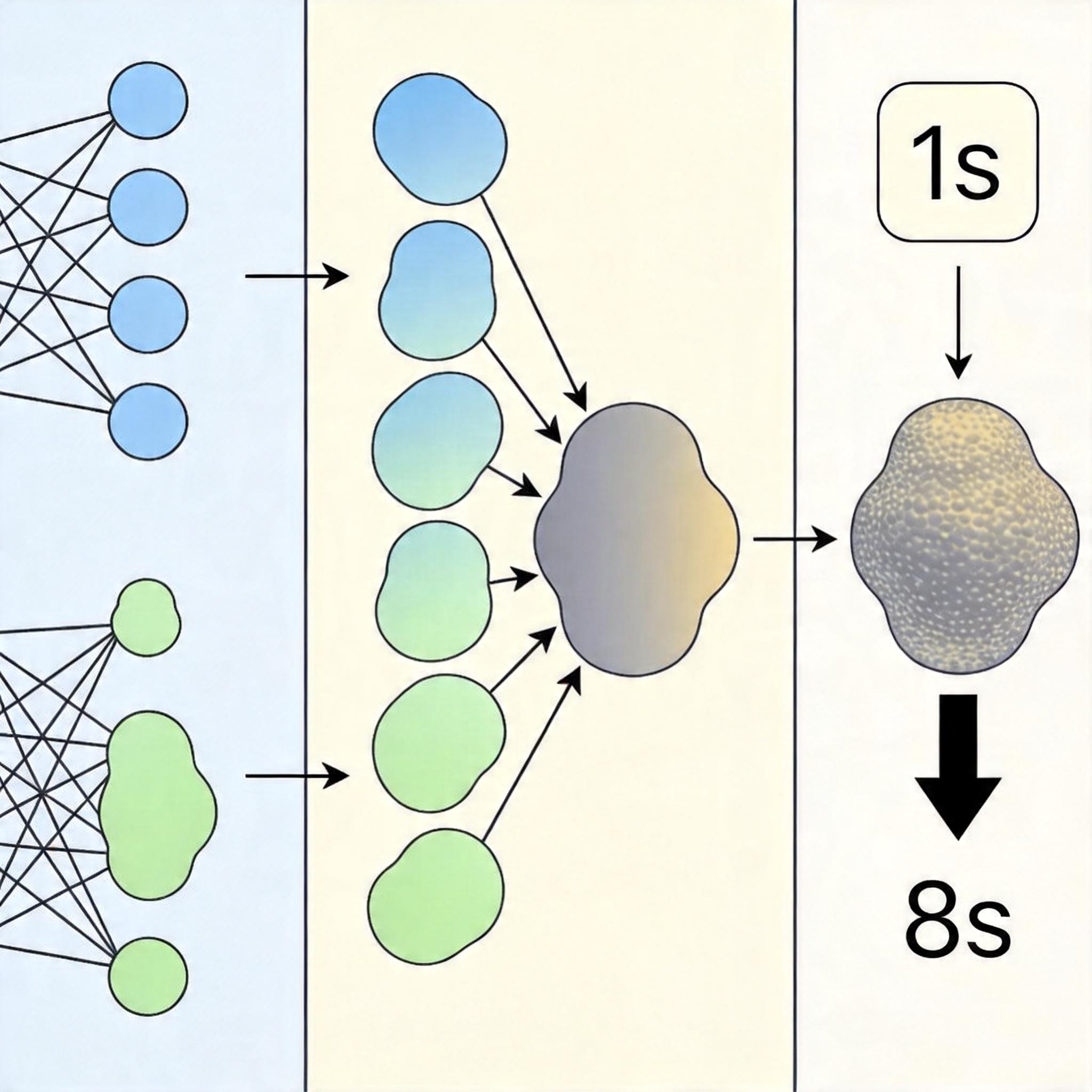
模型训练好了,怎么用才能发挥出最大实力?团队最后加了个“小绝招”——几何自集成。
你可以把这个方法想象成:让同一个学生从正面、侧面、倒着、翻过来等8个角度看同一张模糊的画,然后把8个角度画出的清晰图拼在一起,取平均值。具体来说,就是把带噪图像做8种几何变换:水平翻转、垂直翻转、旋转90°/180°/270°,还有这些变换的组合,然后分别输入模型得到8个去噪结果,再把结果转回到原来的方向,最后取平均值。
这个方法的原理很简单:神经网络对图像的方向有点“脸盲”,同一个物体,正着看和倒着看,模型给出的结果可能会有细微差别。把8个结果平均,就能抵消这些随机波动,得到更稳定、更准确的输出。当然,天下没有免费的午餐:这个方法会让推理时间变成原来的8倍,从1秒左右涨到8秒,适合对精度要求极高但不着急出结果的场景,比如专业摄影修图、医学影像处理。
实验显示,这个“组合技”虽然只带来了0.027分贝的PSNR提升,但胜在稳定可靠——就像给已经很完美的画,再补了几笔精细的细节。
当我们为AI模型的性能瓶颈发愁时,总习惯性地想“换个更复杂的模型”,就像总觉得成绩不好是因为没买更贵的辅导书。但这次的突破告诉我们:有时候,把现有的“辅导书”读透、读全,比不断买新书有用得多。
这不仅仅是图像去噪领域的突破,更是AI研究范式的一次小小转向:当模型架构趋于成熟时,性能的天花板,往往不在模型本身,而在我们喂给它的数据、训练它的方法,以及使用它的策略。数据决定下限,训练决定上限。未来,或许会有更多研究者从“追新模型”转向“挖深潜力”——毕竟,把一件事做到极致,本身就是一种创新。
点击充电,成为大圆镜下一个视频选题!