对抗知识焦虑,从看懂这条开始
App 下载
国产端侧GPU不只是显卡,更是工厂的隐形大脑
工业自动化|IMR架构|端侧GPU|LX系列GPU|砺算科技|智能制造|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载工业自动化|IMR架构|端侧GPU|LX系列GPU|砺算科技|智能制造|前沿科技
上海车间里的机械臂正以0.01毫米的精度抓取零件,24小时无休。没人会注意到,驱动它完成每一次旋转、每一次校准的,不是进口的工业控制器,而是一枚藏在机身里的国产端侧GPU——就是那种普通人眼里只会用来玩游戏的“显卡”。
你可能不会把“游戏帧率”和“汽车零件良率”联系在一起,但在2026年的智能制造车间,这已经是正在发生的现实。当砺算科技把自家的LX系列GPU塞进工业设备时,它填补的不只是国产高性能端侧GPU的空白,更是给中国工厂的“自主可控”补上了关键的一块拼图。为什么一枚显卡能成为工厂的核心?这得从它藏在纳米缝隙里的本事说起。
大多数人对GPU的认知还停留在“游戏画面流畅度”,但在工业场景里,它是能同时干三件事的“超级员工”:一边用并行计算处理机械臂的运动控制数据,一边用图形渲染能力跑数字孪生工厂的实时仿真,还要给AI视觉检测模型做本地推理——全程不用依赖云端,延迟低到可以忽略不计。
砺算LX系列GPU能做到这一点,核心是选对了IMR(立即模式渲染)架构。你可以把它理解成一个“反应超快的绘图员”:接到渲染指令就立刻动手,画完就把结果交出去,不像另一种主流的TBR架构那样要先攒一堆指令再批量处理。这种特性刚好戳中了工业场景的命门——它需要的不是“批量处理的效率”,而是“实时响应的精准”。
更重要的是,IMR架构是国际通用的成熟标准,砺算在这个基础上做了全自主的优化:从指令集到驱动程序全是自己写的,既能完美兼容Windows上的工业软件,也能直接适配国产操作系统。这意味着工厂不用为了换GPU重构整个系统,插上去就能用——这在过去的国产GPU产品里,是想都不敢想的事。
单枚GPU的能力再强,也撑不起一个智能工厂的全部算力需求。当你需要用数字孪生仿真整个车间的生产流程,或者训练一个能识别上百种零件缺陷的AI模型时,就得把成百上千枚GPU连在一起,组成一个超级计算集群。
传统的集群用铜线连接GPU,就像用电话线传视频——带宽有限,距离一远就卡。光跃LightSphere X超节点解决这个问题的办法,是把铜线换成了光信号。你可以把它想象成给每枚GPU都装了一条光纤宽带,数据传输速度是铜线的10倍以上,延迟却只有几微秒。当128枚GPU通过光互连组成集群时,它们的协作效率比传统集群提升了25%——训练Deepseek V3大模型时,同样的任务能少花四分之一的时间。
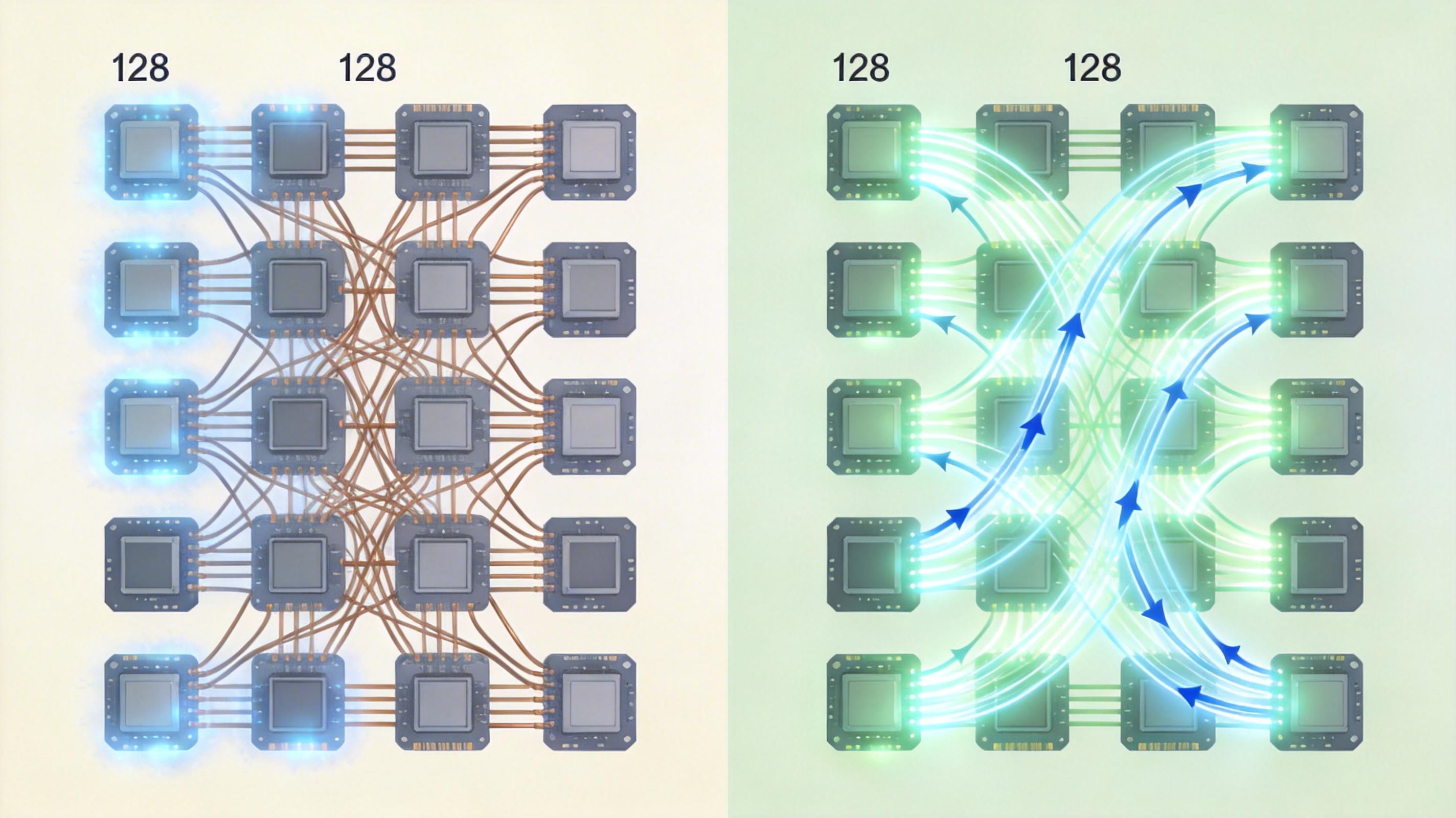
我认为,光互连的意义远不止“更快”这么简单。它打破了GPU集群的规模天花板,以前最多只能把几十枚GPU连在一起,现在几百枚、上千枚都能稳定协同。这意味着中国工厂不用再依赖进口的高端集群设备,用国产GPU就能搭建起自己的超级算力平台——而算力,正是智能制造的“电力”。
国产GPU能走到今天,不是某一家企业单打独斗的结果,而是上海整个产业链闭环的功劳。砺算的LX系列GPU,从芯片设计到流片量产,再到软件适配,全是在上海完成的:设计团队在张江的实验室里画芯片版图,制造环节靠的是本地的6nm工艺生产线,甚至连驱动程序的测试,都是和上海的智能制造企业一起完成的。
这种闭环带来的不仅是“自主可控”,更是“快速迭代”。以前国产GPU要兼容一款工业软件,可能需要半年时间,现在因为产业链上下游就在同城,工程师们可以面对面沟通,几周就能完成适配。摩尔线程、芯原微电子这些上海的GPU企业,能在短短几年里从追赶到接近国际水平,靠的就是这种“拧成一股绳”的协同效应。
当然,现在的国产GPU还不是完美的:高端制程的芯片产量还不够大,软件生态的丰富度也比不上国际巨头。但最关键的一步已经迈出去了——我们不再是“跟着别人的规则玩游戏”,而是开始用自己的技术,定义适合中国工厂的算力标准。
当你下次再看到工厂里的机械臂精准舞动时,不妨停下来想想:驱动它的那枚国产GPU,不仅在计算着运动轨迹,更在重构着中国制造业的底气。
过去我们说“造不如买”,但当国际环境把这条路堵死时,才发现“自己造”的意义,从来不是“替代别人的产品”,而是“掌握自己的节奏”。从一枚端侧GPU的自主设计,到一个光互连集群的搭建,再到整个产业链的闭环,中国智能制造的“算力骨架”正在一点点变得结实。
算力自主,才是制造强国的根。 那些藏在纳米缝隙里的晶体管,正在驱动着一个属于中国的智能制造时代。