
7 天前
7 天前
当所有人都默认大模型的游戏规则是「堆参数=烧钱=拼性能」时,一家中国公司悄悄改写了剧本:用别人1/10的算力成本,在数学推理、代码生成等核心测试上追平了行业标杆。2024年5月,它的一款模型突然发布,把百万token推理成本压到了1元人民币——是当时行业均价的1/70。这场「降维打击」直接引爆了全球AI圈的价格战,也让人们第一次意识到:原来大模型的效率天花板,远没到顶。问题是,他们怎么做到的?
你可以把传统大模型想象成一支全员出动的军队,不管面对什么任务,百万士兵全部冲锋,既浪费弹药又拖慢速度。而MoE(混合专家)架构更像一支特种部队:总兵力看似庞大,但每次只派出最擅长当前任务的小队。
具体来说,MoE把模型拆成了上百个「专家网络」,每个专家只专攻一个细分领域——有的擅长数学推理,有的精通代码生成,有的专啃自然语言理解。当一个输入进来时,模型会通过一个「路由器」判断:这个问题该派哪几个专家处理?比如解数学题,就激活逻辑计算和符号处理专家;写代码,就唤醒语法解析和函数调用专家。
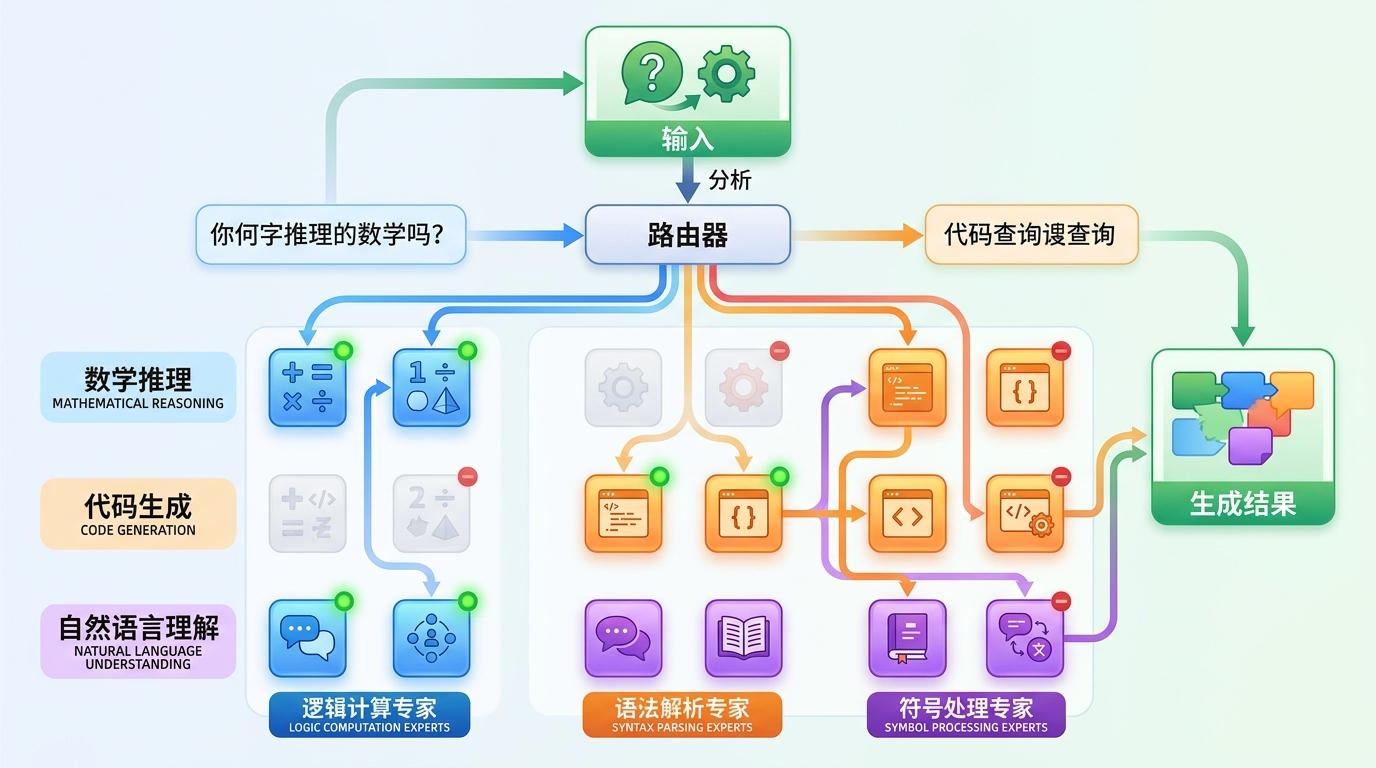
该团队的MoE设计更进了一步:他们把专家切分得更细,还加入了「共享专家」负责通用知识,避免不同专家间的能力重叠。数据显示,他们的模型总参数高达6710亿,但每次推理仅激活370亿——相当于用十分之一的兵力,打出了全员作战的效果。和传统模型相比,训练成本直接砍掉42.5%,推理速度提升了5.7倍。
当然,这种架构也有挑战:路由器很容易「偏心」,总找那几个最厉害的专家,导致其他专家闲置。他们用了一种「动态偏置调整」的方法,让路由器主动给冷门专家一些机会,保证所有专家都能均匀干活,不会出现「忙的忙死,闲的闲死」的情况。
如果说MoE解决了「计算效率」的问题,那MLA(多头潜在注意力)就是攻克「内存瓶颈」的关键。
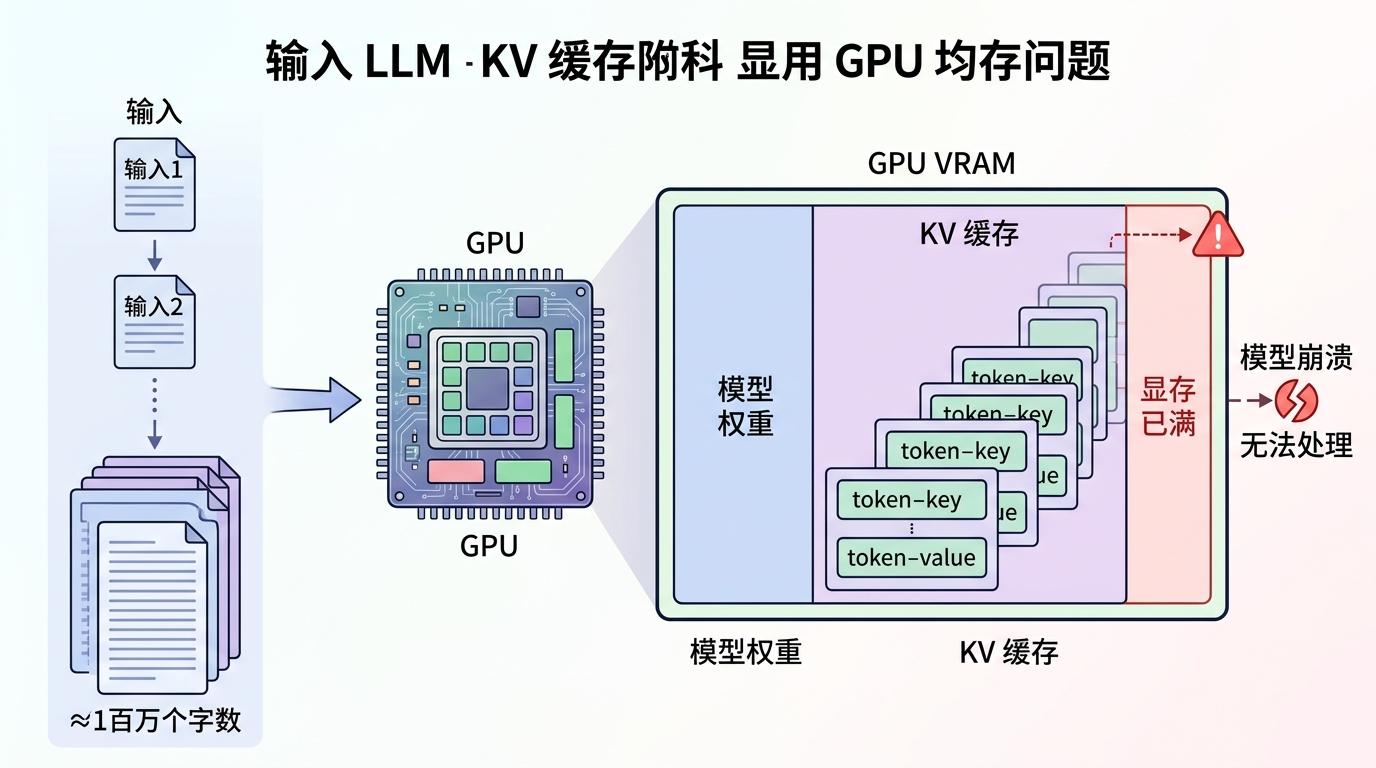
传统大模型的推理过程中,会产生大量的Key-Value(KV)缓存——相当于模型的「短期记忆」,用来存储上下文信息。随着输入文本变长,这些缓存会像滚雪球一样越积越大,很快就会把GPU显存占满,导致模型无法处理长文本,甚至直接崩溃。比如处理一本百万字的小说,传统模型的KV缓存可能要占几十GB显存,普通GPU根本扛不住。
MLA的思路很简单:把这些庞大的KV缓存「压缩打包」。它通过低秩矩阵分解技术,把高维的Key和Value向量压缩成只有原来1/60大小的低维潜在向量,就像把一部4K电影转成了清晰度几乎无损的小体积视频。推理时,模型只需要存储这些压缩后的向量,用到的时候再快速解压还原。
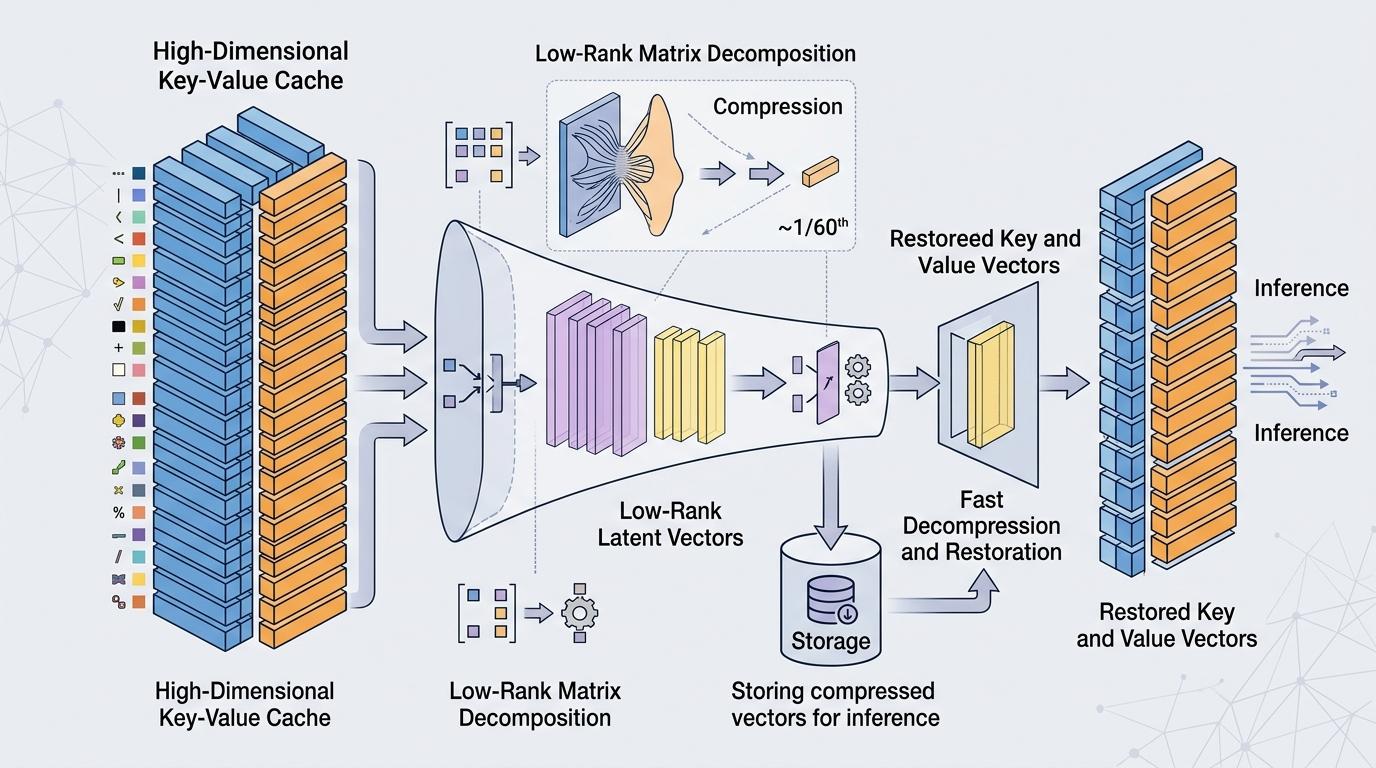
为了保证压缩后不丢失位置信息——这是Transformer模型理解上下文的关键,他们还发明了「解耦RoPE」技术:把文本的内容信息和位置信息分开处理,内容信息走压缩通道,位置信息单独编码,最后再合并到一起。实测显示,MLA能把KV缓存的显存占用降低93.3%,却能保持甚至超过传统注意力机制的性能。这意味着,用消费级GPU就能跑通原本只有数据中心才能支撑的长文本推理任务。
技术突破直接转化成了市场优势。2024年5月,该团队发布的模型API定价,输入百万token仅1元人民币,是当时GPT-4 Turbo的1/70,Meta Llama3 70B的1/7。这个定价像一颗炸弹扔进了AI圈:国内大厂纷纷跟进降价,最高降幅达97%,部分轻量级模型直接免费开放,一场持续大半年的价格战就此打响。
但价格优势只是表象,真正的影响在于,它打破了「大模型只能由巨头玩」的神话。以前,训练一个顶尖大模型需要数亿美元的投入,只有谷歌、OpenAI这样的巨头玩得起;现在,该团队用560万美元就训练出了能和GPT-4掰手腕的模型,是OpenAI训练成本的1/100。这让全球数以万计的中小开发者和创业公司看到了机会:原来不用烧几十亿,也能用上顶尖的AI技术。
当然,他们也面临着新的挑战:把模型从实验室搬到大规模商用场景,需要解决运维稳定性、硬件适配等一系列问题。比如2026年3月,他们的服务器曾崩了13个小时,暴露了运维监控和灾备机制的短板。而要把这套高效架构移植到国产芯片上,更是需要重构整个训练框架——毕竟之前的优化都是基于英伟达的CUDA生态做的。
当我们谈论这家公司时,不应该只盯着「价格屠夫」的标签,更应该看到它背后的逻辑:大模型的未来,不是比谁烧的钱更多,而是比谁用的效率更高。
从MoE的精兵作战,到MLA的显存压缩,再到GRPO强化学习的低成本训练,他们用一套组合拳证明:算力不是大模型的天花板,算法创新才是。这就像当年的智能手机革命,不是谁的硬件参数堆得越高谁就赢,而是谁能把硬件和软件的协同做到极致。
效率,才是AI时代的核心竞争力。 未来的AI战场,不会再是巨头们的独角戏,而是所有能把效率做到极致的玩家的竞技场。这家公司已经迈出了第一步,而接下来的故事,才刚刚开始。
点击充电,成为大圆镜下一个视频选题!