对抗知识焦虑,从看懂这条开始
App 下载
AI正在改写无障碍,便利背后藏着三道坎
无障碍辅助技术|生成式AI|肢体障碍者|听障人士|视障用户|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载无障碍辅助技术|生成式AI|肢体障碍者|听障人士|视障用户|AI产业应用|人工智能
当视障用户对着手机问出“这张账单的截止日期是几号”,AI能准确读出数字;当听障人士戴上眼镜,对面的说话声会实时变成眼前的字幕;当肢体障碍者盯着屏幕上的图标,眼动追踪系统能帮他“点”开应用——这些曾出现在科幻里的场景,如今正成为残障人士的日常。生成式AI正以惊人的速度渗透进无障碍领域,它不仅是辅助工具的升级,更像是为残障群体打开了一扇通往更平等世界的门。但很少有人注意到,这扇门的背后,还横着几道容易被忽略的坎。
你可以把生成式AI理解成一个“全能翻译官”——它能把视觉信号转成语音,把语音转成文字,把复杂的指令转成简单的操作,甚至能读懂人的眼神和手势。在视觉辅助领域,AI图像识别技术能像人眼一样拆解画面:识别钞票面额、读出路牌文字、描述照片里的场景,精度比传统工具提升了40%以上;在听觉辅助上,实时字幕技术能把100多种语言的口语转成文字,延迟控制在0.5秒内,让听障人士和普通人打电话时几乎没有障碍;对于肢体障碍者,眼动追踪和个性化手势识别技术,让他们不用动手就能操控电脑、智能家居,甚至用眼神“打字”聊天。
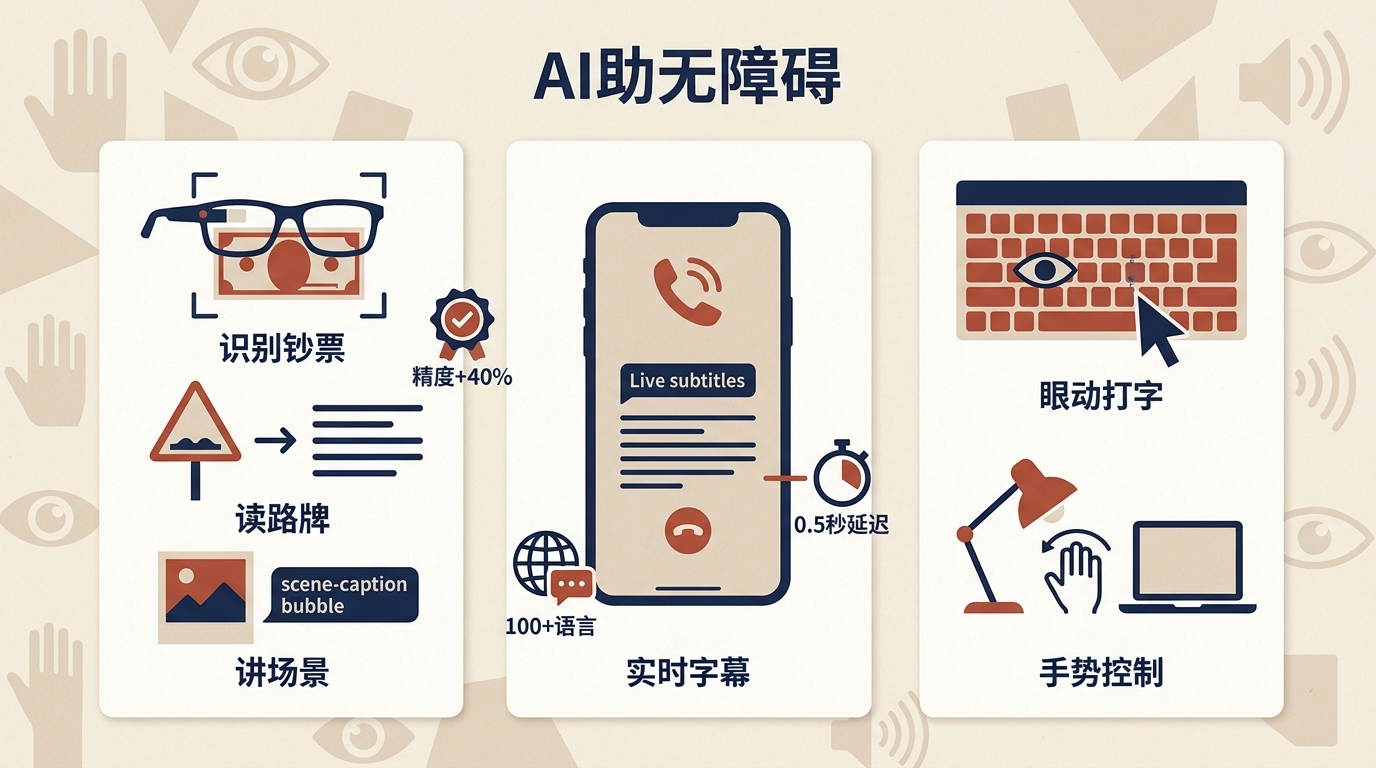
这些技术的核心,是多模态AI的融合——它能同时处理文本、图像、音频、动作等多种信号,就像人的大脑整合所有感官信息一样。比如一款智能眼镜,能同时捕捉眼前的画面和耳边的声音,把视觉描述和语音转写同步推送到用户的视野里;一款沟通辅助设备,能通过摄像头识别用户的手势,再把手势转成自然语言输出,让无法说话的人也能流畅表达。
AI给无障碍领域带来的改变显而易见,但它的局限性同样不容忽视,甚至可能成为新的障碍。
第一道坎是“算法偏见”。大部分AI模型是用普通人的数据训练的,残障群体的样本严重不足——比如语音识别模型对非标准发音的识别率只有30%,远低于普通人的95%;图像识别模型常常把轮椅用户的动作误判为“异常行为”。2022年宾夕法尼亚州立大学的研究显示,所有测试的语言模型都对残障相关词汇有隐性负面偏见,比如提到“聋人”时更倾向于生成“无助”“可怜”这类词汇。
第二道坎是“幻觉风险”。AI生成的内容可能出现完全错误的信息,这对依赖辅助工具的用户来说是致命的——比如视觉AI把“停止”路牌误判成“通行”,或者把药物剂量读错。某厂商在新功能里专门加入了警告:“有风险的场景下,不要依赖AI的描述”,但很多用户还是会因为信任AI而忽略提醒。
第三道坎是“数字鸿沟”。先进的AI辅助设备价格不菲,一款智能眼镜要几万元,定制化的沟通设备甚至要十几万,大部分低收入残障家庭根本买不起。同时,AI工具的操作复杂度也在提升,很多老年残障用户连基本的设置都不会,更别说调整个性化参数了。
要让AI成为真正普惠的无障碍工具,不能只靠技术升级,还要解决更底层的问题。
首先是“用户中心设计”。必须让残障人士直接参与AI产品的开发——比如让听障用户测试语音转文字的准确率,让视障用户评估图像描述的详细度,让肢体障碍用户优化手势识别的灵敏度。英国NHS的康复工程部门就采用了这种方法,他们在用户家中观察设备的使用场景,最后设计出的肌电图开关,误触发率降低了60%。

其次是“数据公平”。要专门收集残障群体的训练数据,比如非标准发音、特殊手势、残障人士的日常场景等,还要建立偏见检测机制,及时发现并修正算法中的歧视性内容。Google的Project Euphonia项目,就收集了大量非典型语音数据,把言语障碍者的语音识别准确率从31%提升到了95%。
最后是“政策兜底”。政府需要出台补贴政策,降低AI辅助设备的价格,同时推动公共服务的AI无障碍化——比如要求医院、银行、学校的AI系统必须支持残障用户的操作习惯,要求短视频平台必须提供AI生成的字幕。
AI给无障碍领域带来的,从来都不是“完美解决方案”,而是“更多可能性”。它能让残障人士更独立,但不能代替他们发声;它能降低沟通的门槛,但不能消除偏见的壁垒。
技术的温度,从来都不是来自代码本身,而是来自开发者是否愿意蹲下来,倾听那些被忽略的需求。AI的终极目标,是让每个人都被看见。 当我们把残障群体的需求真正放在技术的核心,而不是当成“附加功能”时,AI才能真正成为推动平等的力量。