对抗知识焦虑,从看懂这条开始
App 下载
AI旗舰“变笨”真相:不是模型退化,是系统失衡
实际使用成本|模型升级|用户体验|基准测试数据|AI旗舰模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载实际使用成本|模型升级|用户体验|基准测试数据|AI旗舰模型|大语言模型|人工智能
2026年4月,一款被寄予厚望的AI旗舰模型上线。官方数据显示它在编码、视觉任务上的得分全面超越前代,甚至领先行业竞品;但用户的吐槽却刷爆了社交平台——有人说它连单词里的字母数都数错,有人发现它改简历时会编造不存在的学校,还有开发者反馈它编程时变得冲动莽撞,动辄误改代码。更让用户愤怒的是,花了和之前一样的钱,实际使用成本却涨了35%,想退回旧版本还被彻底堵死。这场“升级变降级”的闹剧,到底是模型真的“变笨”了,还是另有隐情?
官方晒出的基准测试数据漂亮得无可挑剔:编码任务得分从80.8%跃升至87.6%,视觉理解能力提升了13个百分点,多工具调用成功率稳居行业第一。合作企业也给出正面反馈,称它能自主发现代码逻辑错误,把人工复核工作量减少了三成。
但真实的用户体验却是另一个极端。Reddit上一条吐槽帖获得2300个点赞,用户晒出的测试里,这款旗舰模型居然说“strawberry”里有两个字母P;X平台上,1.4万用户点赞了“新版本不如旧版”的评论;有开发者对比编程3天的结果,发现新版本一次做对的比例从83.8%降到74.5%,修改重试次数直接翻倍。
这种撕裂的核心,在于实验室测试和真实场景的本质差异。基准测试用的是标准化、单一化的任务,而用户面对的是复杂的多轮对话、长文档处理、跨工具调用的真实工作流——这些场景里,决定体验的从来不是模型本身的参数,而是一整套系统的协同。
用户感知到的“变笨”,是七层系统变量共同作用的结果,每一层的微小偏差叠加起来,最终演变成了体验的雪崩。
第一层是分词器的变更。新版本采用了新的文本拆分规则,同样一段文字,转换成模型能识别的“token”数量增加了35%,代码和技术文档的增幅甚至超过40%。这意味着用户每发一条指令,要花更多的钱,模型处理长文本时也更容易“内存不足”。
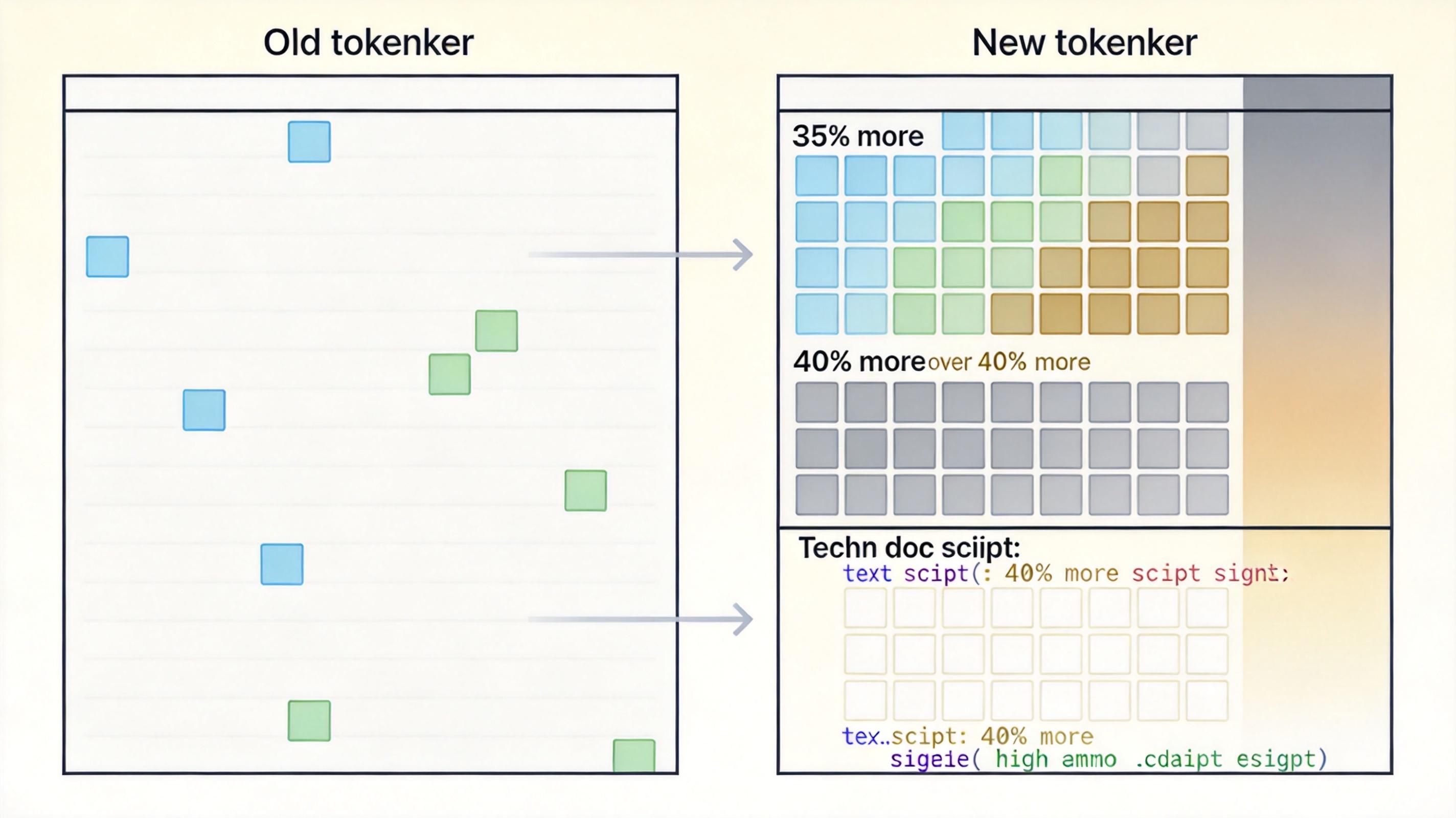
第二层是自适应推理机制的默认配置。这套让模型自主决定“思考深度”的技术,理论上能平衡效率和效果,但实际默认设置却偏向了“快速响应”而非“准确推理”。用户说“根本没法让它好好思考”,本质是模型在简单任务上节省资源的策略,被用到了需要深度推理的场景里。
第三层到第七层,则是从提示词设计、API接口、硬件部署到安全约束的层层错位:提示词要求模型“先读文件再修改”,但系统不把“搜索”算“读取”,导致模型反复发起无效请求;同一用户的不同请求可能被分配到AWS、谷歌、英伟达的不同硬件上,性能波动像坐过山车;安全约束的收紧让模型变得过于保守,动辄以“超出范围”拒绝合理请求。
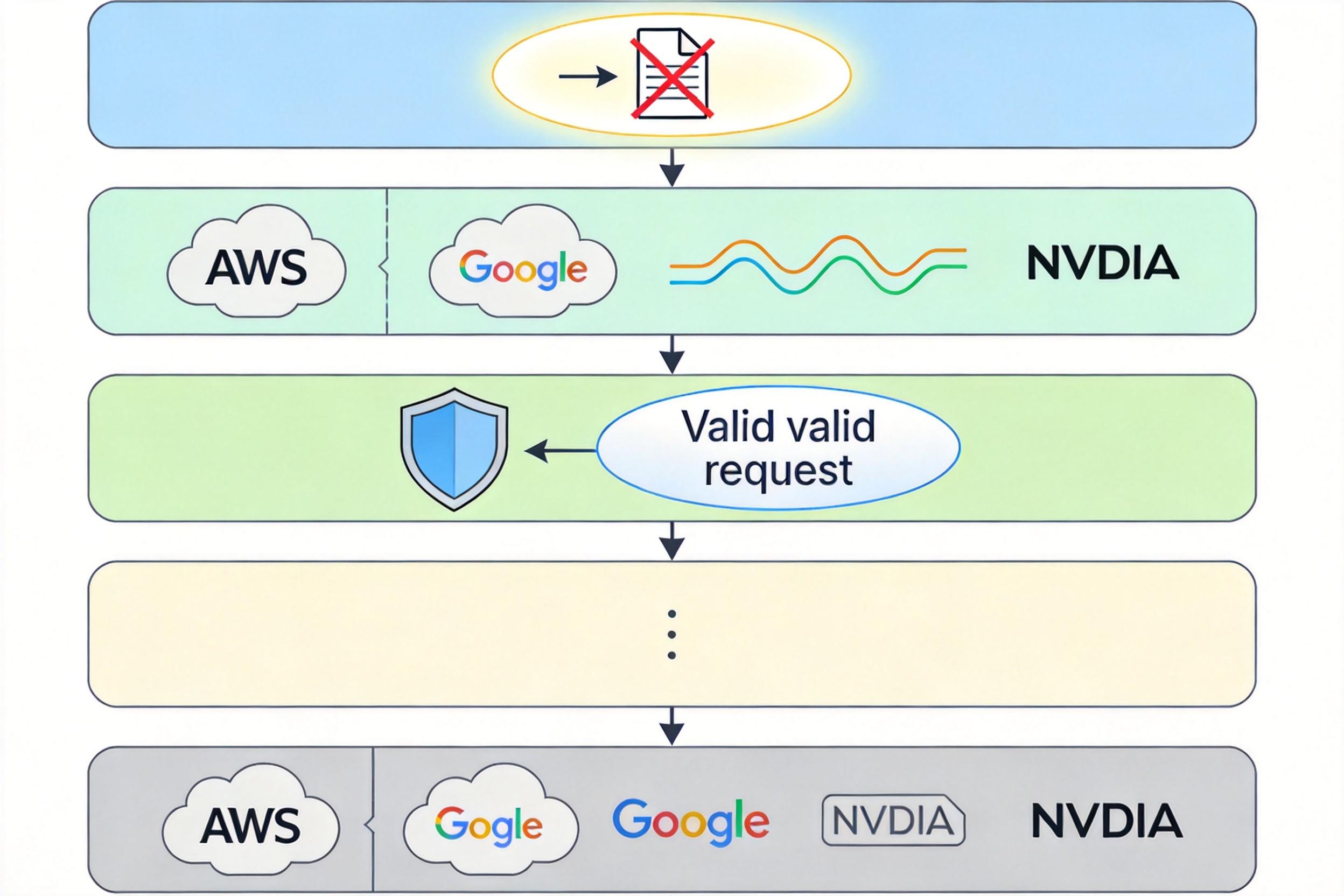
这些问题单独看都是小bug,但叠加起来就成了系统性的体验灾难:token消耗激增导致上下文“腐烂”,无效请求污染了对话历史,硬件波动让输出结果前后矛盾,最终让用户产生“模型变笨了”的错觉。
这场争议的本质,是技术迭代与用户体验的失衡,更是企业与用户之间信任的崩塌。
AI行业的定价逻辑正在从“补贴抢市场”转向“按成本收费”,但这家企业选择了最生硬的方式:保持标价不变,却通过分词器偷偷抬高实际成本,还直接下线旧版本,断了用户的退路。有企业用户反馈,月度账单直接涨了40%,却只能被迫接受。
更关键的是,企业在技术迭代中完全忽视了用户的知情权和控制权。自适应推理的参数锁死,用户无法调整思考深度;思考过程默认隐藏,用户看不到模型的“决策依据”;API接口的变更没有兼容旧有工作流,导致开发者的集成代码大规模失效。
这种“技术至上”的傲慢,正在将用户推向竞争对手。谷歌已经组建突击队攻坚AI编程模型,OpenAI则在强调“保持版本稳定”——当用户发现其他产品能提供更稳定、更可控、更透明的体验时,这场“变笨”争议带来的就不只是口碑下滑,而是实实在在的市场份额流失。
当我们讨论AI“变笨”时,我们真正在讨论的是:当AI从实验室里的技术演示,变成支撑千万人工作的基础设施,我们需要的到底是什么?是跑分榜上的漂亮数字,还是稳定、可控、可信任的使用体验?
这场争议像一面镜子,照出了AI行业的尴尬:我们能训练出性能超强的模型,却还没学会如何把它变成可靠的工具。用户要的从来不是“最聪明”的AI,而是“好用”的AI——就像一台不会突然死机的电脑,一辆不会半路抛锚的汽车。
AI的终极进化,从来不是模型参数的竞赛,而是系统协同的艺术。 当技术的每一次迭代,都能以用户的真实体验为锚点,而非单纯的性能指标,这样的AI才真正值得被信任。