对抗知识焦虑,从看懂这条开始
App 下载
给AI改50万次知识,它反而越改越稳
智能仓库管理系统|终身归一化|知识编辑|中科大团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载智能仓库管理系统|终身归一化|知识编辑|中科大团队|大语言模型|人工智能
想象一下,你要给一个装满知识的大仓库连续改50万次货:删掉过期的旧资料,补上刚更新的新信息,还要保证每一次改动都不碰乱其他货架上的东西。这对人类仓库管理员来说是天方夜谭,但对现在的大语言模型来说,已经是可以实现的日常。中科大团队的一项研究发现,当给模型做百万级的连续知识编辑时,它不仅不会越改越乱,反而会越改越稳——早期的编辑经验居然能帮后续的改动更精准。这背后藏着一个叫终身归一化(LN)的核心机制,它就像给模型装了个智能仓库管理系统,让每一次知识更新都走对路。
过去给大模型改知识,就像在一本写满字的书上涂改:改个三五处还能看,改多了要么把之前写的内容糊成一团——这叫「灾难性遗忘」;要么整本书的字迹都开始扭曲,连原本清晰的内容也认不出来了——这就是「模型崩溃」。

你可以把模型的参数想象成一堆牵着手的人,每改一个知识,就相当于拉其中几个人换位置。改的次数少,其他人还能保持队形;改多了,整个队伍就彻底散了。之前的编辑方法要么不敢动核心参数,要么一动就牵一发而动全身,根本撑不住上万次以上的连续改动。
直到研究者发现,那些能撑过百万级编辑的模型,都偷偷用了同一个技巧:终身归一化(LN)。它不是简单的数值调整,而是在每一次编辑时,都悄悄记录下参数变化的规律,就像仓库管理员记下来每次货物的摆放习惯,下次再补货时,不用重新规划就能精准找到位置。
中科大团队首次揭开了LN的底层逻辑:它本质上是在做「递归贝叶斯追踪」——每一次编辑后,模型都会把这次的改动规律当成「经验」存起来,下次再改的时候,就用之前的经验来校准这次的方向。
打个比方,你第一次给模型改「李白的出生地」,模型会记住「改历史人物出生地需要调整哪几个参数」;第二次改「杜甫的出生地」,它就不用从头摸索,直接沿用之前的经验,只改最相关的参数,不会碰乱其他内容。
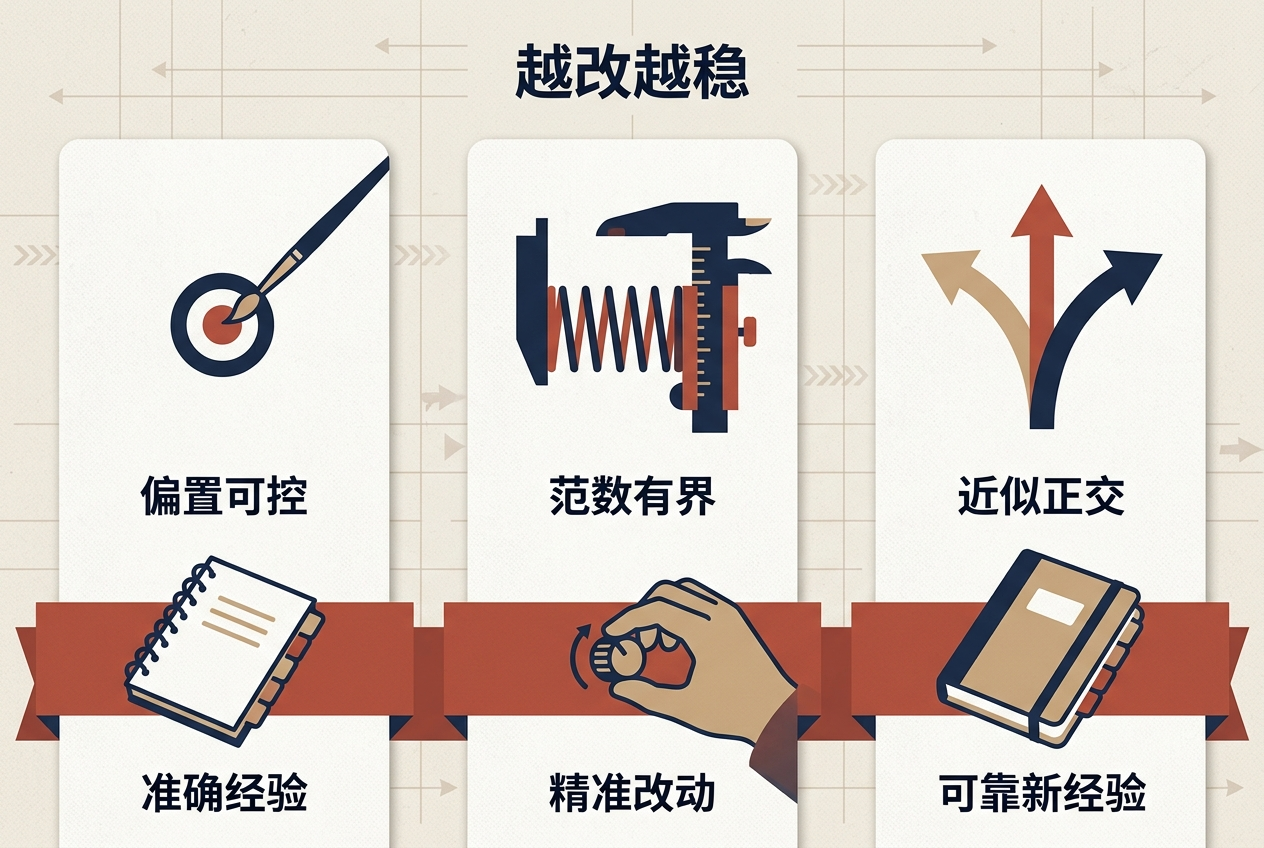
更关键的是,LN和岭回归结合后,每次的参数更新都会满足三个关键条件:偏置可控,只改该改的地方;范数有界,不会越改幅度越大;近似正交,每次改动的方向尽量不跟之前的重叠。这就形成了一个「越改越稳」的闭环:准确的经验→精准的改动→更可靠的新经验。
团队在这个基础上做了StableEdit,给LN加了两个小补丁:编辑前先用少量数据「热身」,让初始经验更准确;再用「完全白化」把参数间的关联理清楚,让每一次改动的方向更纯粹。在50万条的WikiBigEdit和200万条的UltraEditBench测试里,它的稳定性远超之前的方法。
在WikiBigEdit的50万条连续编辑测试中,StableEdit的表现让人大吃一惊:它不仅能准确记住每一次新增的知识,还能保持95%以上的原始模型能力——用GLUE五任务测试,它的性能几乎和没改过的模型一样。
研究者做了个反直觉的对比:一组模型从第一条编辑开始做满50万次,另一组直接从第25万条开始做。结果显示,做满全程的模型,在后25万条的编辑准确率反而更高。这就像仓库管理员越干越熟练,后面的补货速度和准确率都比新手期强。
更有意思的是,StableEdit的「热身」数据不需要和编辑内容相关——用医学数据热身,再改历史知识,性能几乎没下降。这说明它热身的不是「知识」,而是「编辑的感觉」,就像运动员热身是为了找到运动状态,而不是提前练项目。
当我们还在担心AI会「记不住事」的时候,它已经学会了「越干越熟练」。这不仅仅是一个技术突破,更给我们打开了一个新的想象空间:未来的AI可能不需要定期「回炉重造」,它可以像人类一样,在日常的学习和调整中不断进化,把每一次经验都变成下一次进步的阶梯。
好的学习,是让经验成为拐杖,而非包袱。 这句话不仅适用于AI,也适用于每一个在成长的人。毕竟,真正的终身学习,从来不是学了多少东西,而是能不能把每一次经历都变成下一次的底气。