对抗知识焦虑,从看懂这条开始
App 下载
AI替你熬夜炼丹,科研终于能回归思考
深度学习训练|科研助理|自动化实验|开源框架|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载深度学习训练|科研助理|自动化实验|开源框架|AI智能体|人工智能
凌晨三点的实验室,屏幕亮着淡蓝色的光——不是有人在赶论文,是服务器在跑第72轮训练。深度学习研究者的日常,就是在改超参、等结果、再改超参的循环里打转,Deadline前要重复上百次。最崩溃的不是熬红的眼,是明明早就想好了要试什么,却要把80%的时间耗在机械的等待和操作上。这些本该用来思考的时间,能不能交给AI?GitHub上的一个开源框架给出了肯定的答案:你睡觉的时候,它在自动跑实验;你写论文的间隙,它已经把结果表格整理好了。
你可以把这个AI Agent的工作流,类比成一个严谨的科研助理的日常:先复盘之前的实验结果,想清楚下一步该试什么;然后动手调整代码和参数,先跑个小测试确保没问题,再正式提交训练;训练时盯着进程,确保没出故障;最后看结果、记笔记,再开启下一轮。
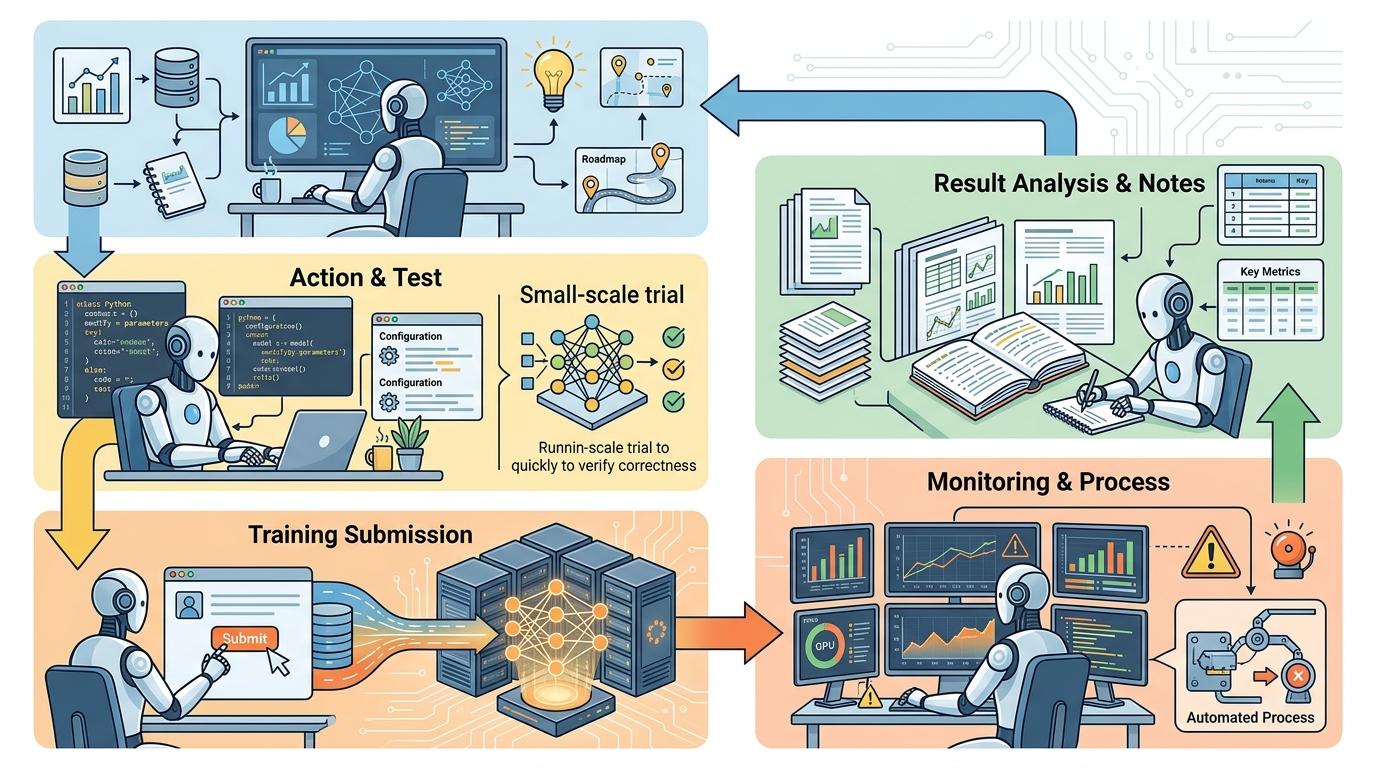
这就是它的核心——THINK→EXECUTE→MONITOR→REFLECT的自主循环。
🧠 THINK:它会读取你定下的研究目标,再翻一遍之前的实验记录,分析当前的最优结果,决定下一步该调哪个超参数、换哪个损失函数,甚至要不要加个数据增强策略。
⚙️ EXECUTE:确定方案后,它自动修改代码或配置文件,先跑2步前向反向传播做个“干跑测试”,确认没bug再把任务推到GPU上。
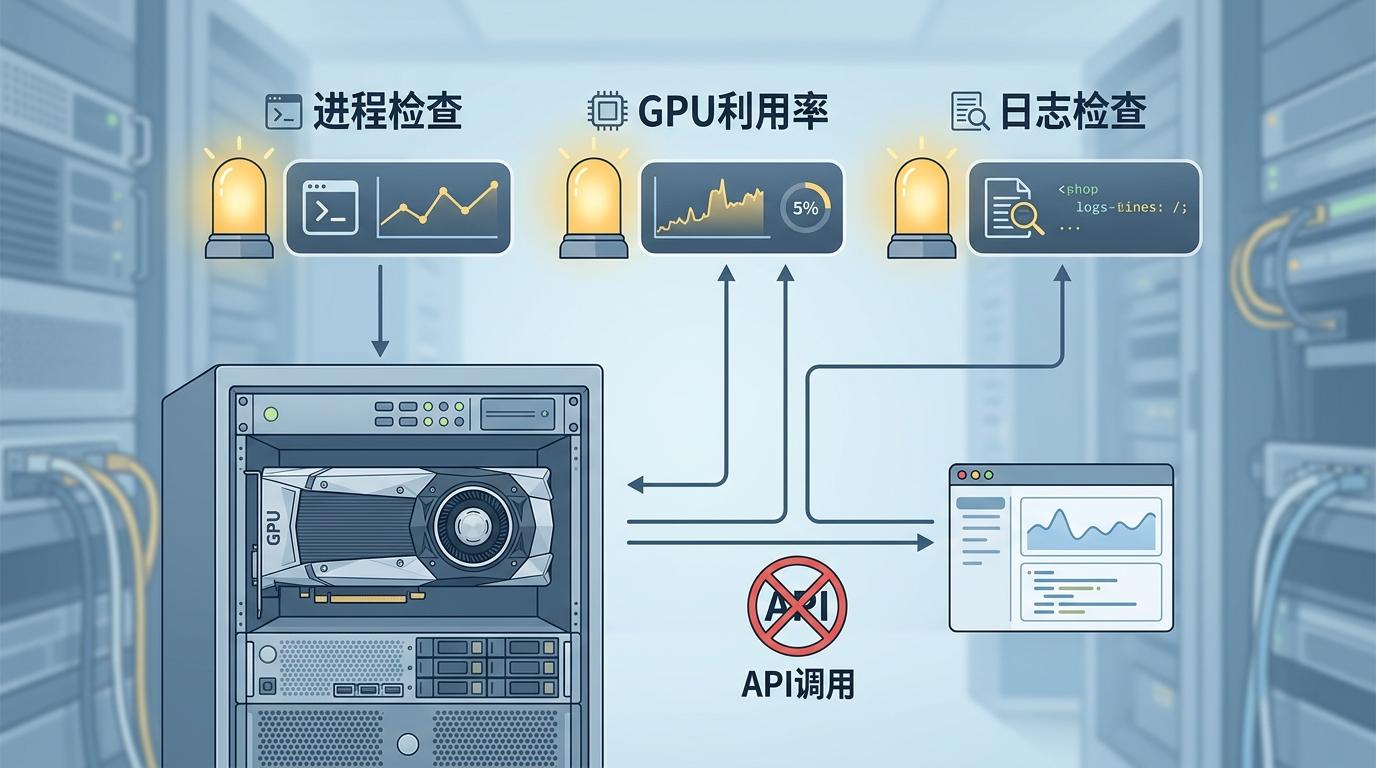
👀 MONITOR:这是它最省钱的一招——训练时完全不调用大语言模型API,只靠三个系统命令:看进程活着没、看GPU在干活没、看日志最后几行。全程零API成本。
🔍 REFLECT:训练结束,它自动解析日志、提取指标,和之前的最优结果对比,把关键信息记下来,接着开启下一轮循环。
长时间运行AI Agent有个老问题:做的实验越多,积累的记忆就越长,不仅调用大模型的成本会飙升,推理速度也会越来越慢——就像你让一个人抱着几百页的笔记做决策,效率怎么都高不起来。
这个框架用了个聪明的解法:两层恒定记忆系统。
第一层是“固定记忆”,就是你一开始写下的项目说明,最多3000字符,相当于给AI定下的研究“初心”,永远不会变。
第二层是“滚动记忆”,它自己会把关键实验成果压缩到1200字符以内,只保留最近15条决策,就像一个随身的实验小本子,只记最有用的内容。
两层加起来,总记忆量恒定在5000字符左右。不管它跑1天还是跑半年,上下文都不会膨胀,成本和速度始终稳定。
这个设计的妙处在于,它既让AI记住了该做什么,又不会被冗余信息拖累——就像一个有经验的研究者,永远只盯着最关键的变量,不会在无关细节上浪费精力。
在GitHub的README里,作者特意加了一段严肃的声明:严禁用这个框架做学术造假,核心的idea必须由人来提供,AI只是帮你跑通机械的流程。
这不是空喊口号,而是戳中了AI科研工具的核心边界:它可以替你熬无数个夜,跑上百轮实验,但不能替你提出问题、做出判断。就像实验室里的自动化仪器,再精密也需要人来设定参数、解读结果。
有人担心AI会“抢了研究者的饭碗”,但实际的应用场景里,它更像是一个“科研放大器”——把人从机械劳动里解放出来,让你有更多时间去想真正重要的问题:这个实验结果意味着什么?下一步该往哪个方向创新?
目前它已经在多个真实项目里跑通了:连续运行30多天,完成500多轮实验,单项目指标提升了52%,还能同时管理4台GPU服务器。你甚至可以用手机APP实时监控进度,躺床上就能给它发指令换方向。
当AI开始帮研究者“跑实验”,我们真正要讨论的不是“AI会不会取代科学家”,而是“科学研究该把时间花在哪里”。
深度学习的进步,从来不是靠熬了多少夜、跑了多少轮实验,而是靠那些跳出循环的思考——是突然想到的一个新假设,是对结果的一次深度解读,是在无数次失败里找到的那个突破口。
工具解放双手,思考定义价值。
未来的科研实验室里,AI会成为每个研究者的“夜班助理”,而人类,只需要专注于那些只有人能做的事:提出问题,创造新知。