对抗知识焦虑,从看懂这条开始
App 下载
机器人不再只懂执行,部署后还能自己变强
货架整理|自主学习|双臂机器人|LWD系统|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载货架整理|自主学习|双臂机器人|LWD系统|AI智能体|人工智能
想象一下:你买了台机器人帮你整理货架,第一天它还会把牛奶碰掉,一周后却能精准补货、纠正错放的商品,甚至学会了最快的理货路线——而且全程没人教它。这不是科幻场景,而是真实发生在16台双臂机器人身上的事。过去机器人的宿命是「出厂即定型」,要升级就得回炉重训,但现在,一套叫LWD的系统让它们能在真实环境里边干活边进化。为什么之前做不到?这背后藏着机器人行业卡了十年的死结。
过去机器人训练像养温室里的花:只能用完美的人类示范数据,失败的轨迹全当垃圾扔掉。就像学骑车只看别人怎么骑得稳,自己摔的跤全不算数——结果一到真实世界,稍微变个场景就手足无措。
LWD的第一个突破,就是把「失败」捡了回来。它让机器人把所有执行轨迹——成功的、卡壳的、被人纠正的——全传到云端的「数据飞轮」里。这个飞轮的逻辑很简单:机器人越多、跑的时间越长,攒的经验就越多;算法从这些经验里学,把优化后的策略再发回机器人,形成「干活→攒经验→变聪明→再干活」的闭环。
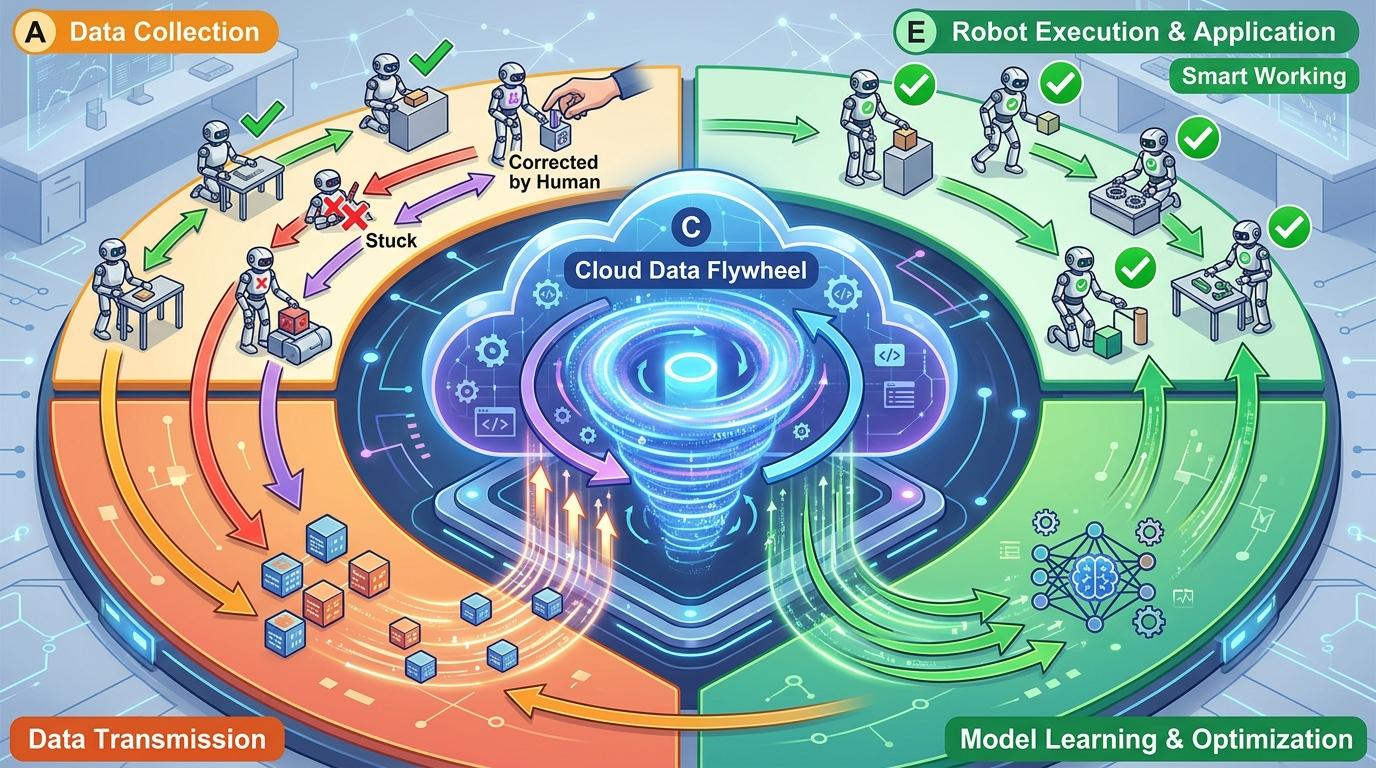
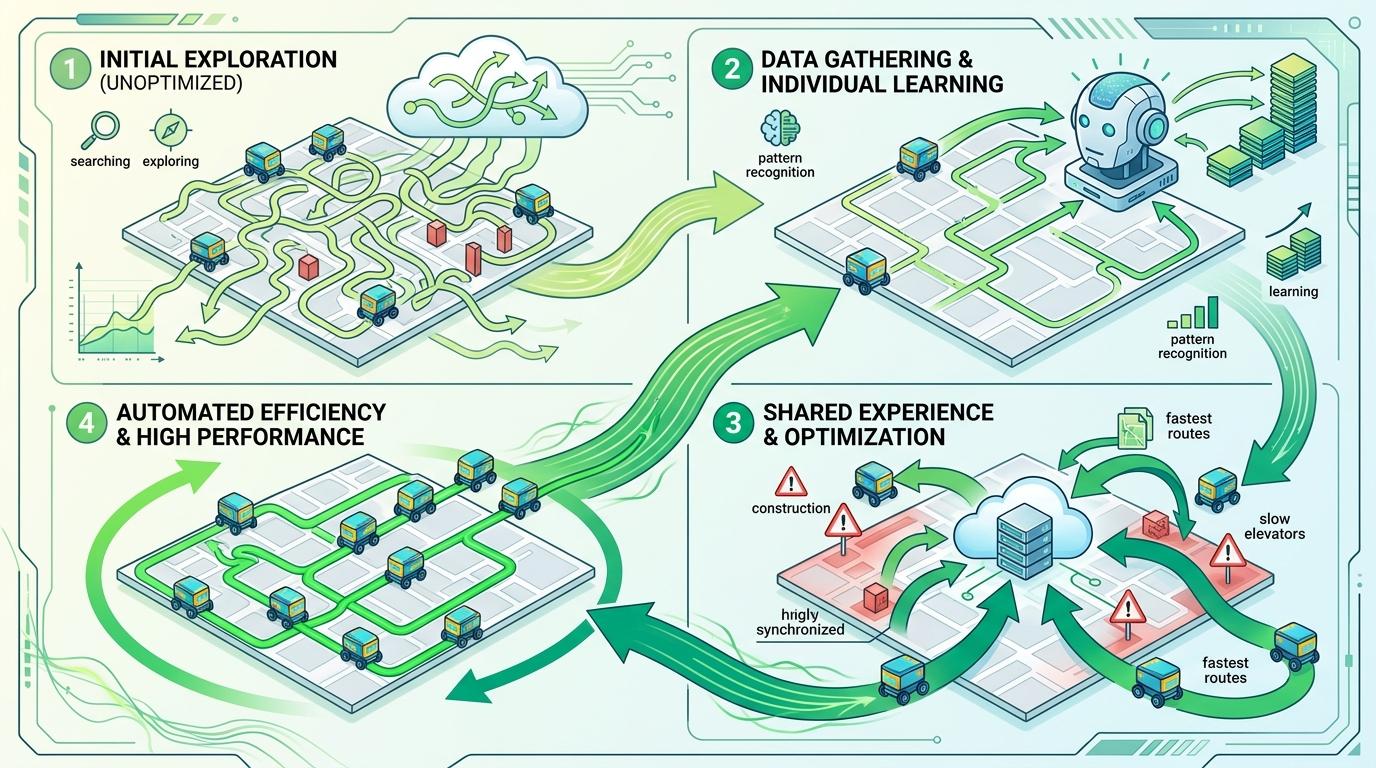
你可以把这个飞轮想象成一群外卖员跑熟商圈:一开始大家都绕路,跑得多了就摸出了最快的路线,还会分享哪里有临时修路、哪个小区电梯难等。不同的是,机器人的「经验分享」是算法自动完成的,16台机器人跑一天,攒的经验抵得上过去人工标注几个月。
光有数据还不够,机器人得知道「哪个动作好」「怎么改得更好」。LWD靠两个核心算法解决了这两个问题——你可以把它们理解成机器人的「阅卷老师」和「家教」。
第一个算法叫DIVL(分布式隐式价值学习),是负责打分的「阅卷老师」。传统打分是直接给个分数,比如「这个动作80分」,但真实环境里数据太杂,单一分数很容易不准。DIVL的做法是「估一个分数区间」:比如这个动作的得分大概率在70到90之间,再从这个区间里取最合理的值。就像老师改作文,不说「得85分」,而是说「在良好到优秀之间,扣分项是逻辑有点散」——这样的判断更稳,也更贴合真实世界的不确定性。
第二个算法叫QAM(伴随匹配的Q学习),是负责改错题的「家教」。现在机器人的动作是像画油画一样「多步生成」的,传统强化学习要改的话,得把整幅画重新画一遍,不仅慢还容易画崩。QAM的聪明之处是「只改局部」:在每一步画的时候微调一下,慢慢把动作往高分方向推,就像家教不用你重写整篇作文,只帮你把某一段的逻辑理顺。
更关键的是,这两个算法从离线训练到在线学习全程通用,避免了过去换算法时的「水土不服」——机器人不用在「实验室模式」和「真实世界模式」之间切换,学起来更顺畅。
有人可能会问:这和之前的机器人学习有什么不一样?答案是:它终于把「实验室里的成功」搬到了「真实世界的日常」。
这次实验用的是16台双臂机器人,做的全是接地气的任务:给商超补货架、调鸡尾酒、泡功夫茶、装鞋盒——这些任务要么环境乱(货架上的商品随时变),要么步骤多(调酒要8个连续动作),要么要求精细(功夫茶要控制倒水的速度)。结果是,随着部署时间变长,所有任务的成功率都在涨,尤其是长步骤任务,周期时间缩短了,卡顿也少了。

但它也不是没有局限:现在还只能在同类型的机器人之间共享经验,跨机型的学习还没解决;而且数据传输和算法训练都依赖云端,一旦断网就「罢工」。更重要的是,机器人学的是「怎么把事做成」,但还不懂「为什么不能这么做」——比如它知道怎么拿杯子,却还没建立「杯子掉地上会碎」的常识。这些都是接下来要啃的硬骨头。
过去我们总说「机器人是人类的工具」,但LWD让这个定义开始松动——它不再是只能执行指令的机器,而是能像学徒一样,在干活中慢慢成长。这背后的逻辑其实很朴素:人类的智慧从来不是从完美的示范里学来的,而是从无数次试错、观察和调整中攒出来的。
部署即进化,不是机器人变聪明了,而是我们终于学会了让机器人像人一样学习。当机器能从真实世界里自己找答案,它们才真正具备了走进我们日常的资格。