对抗知识焦虑,从看懂这条开始
App 下载
AI修视频:从补马赛克到救比特流
NTIRE挑战赛|BSCVR-P网络|MGTV-AI团队|比特流损坏|视频修复|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载NTIRE挑战赛|BSCVR-P网络|MGTV-AI团队|比特流损坏|视频修复|多模态视觉|人工智能
你有没有过这种经历:直播球赛到绝杀时刻,画面突然炸成色块;远程会议刚要展示关键数据,屏幕撕裂成马赛克;甚至存了十年的家庭录像,一打开满是错位的拖影。这不是网络卡,是视频的「比特流」坏了——数据在传输或存储时丢了码,解码器读不懂,就把错误变成了满屏乱码。传统的去模糊、去噪根本不管用,这相当于视频得了「内伤」,得用AI来做手术。2026年NTIRE挑战赛上,全球153支队伍同台竞技,终于拿出了能治这种「内伤」的方案。
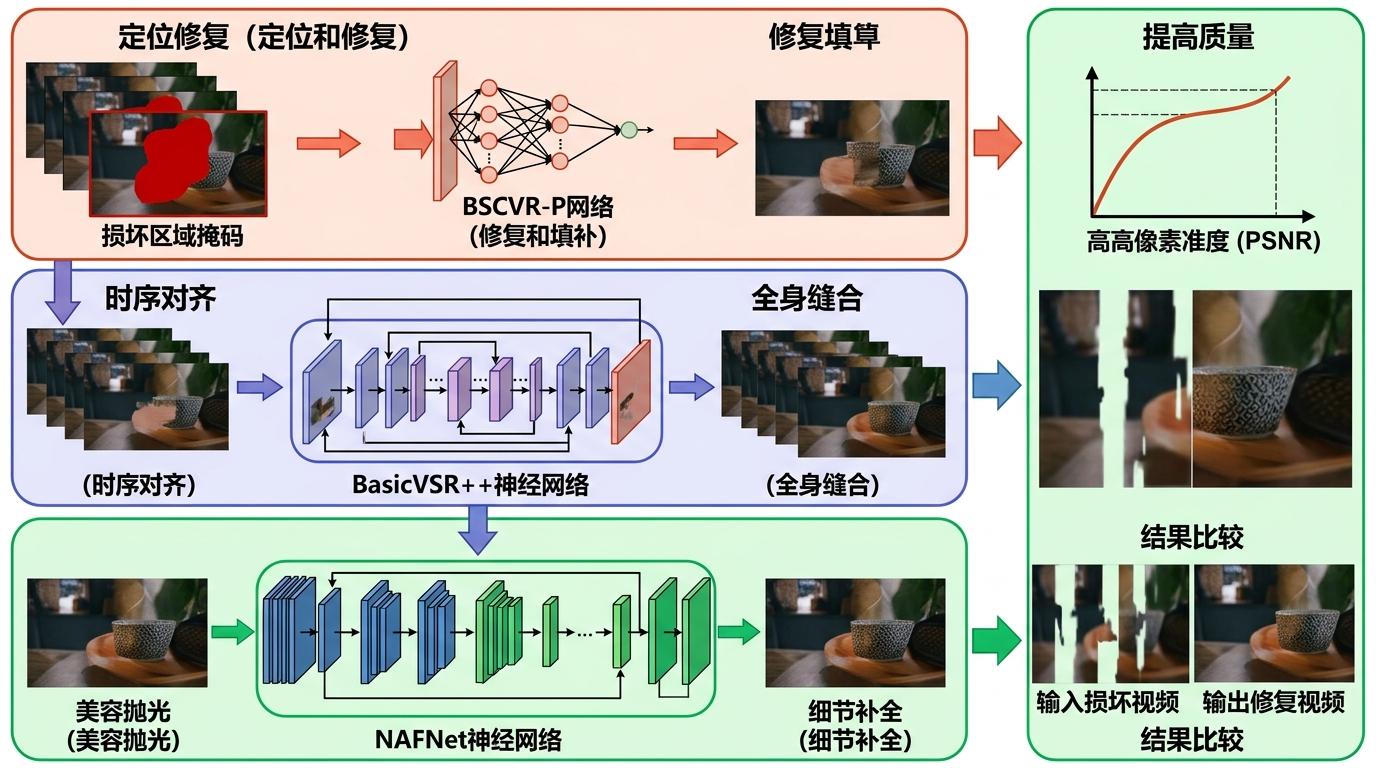
MGTV-AI团队的方案像一场精密的外科手术,分三步搞定:先用BSCVR-P网络定位「病灶」——也就是官方给的损坏区域掩码,把缺失的内容先填上;再用BasicVSR++做「全身缝合」,把前后帧的时序对齐,避免修复后画面跳帧;最后用NAFNet做「美容抛光」,把边缘锐化、细节补全。这套三阶段流水线稳扎稳打,让他们拿到了像素精度(PSNR)的第一,修复后的视频和原片像素误差最小。
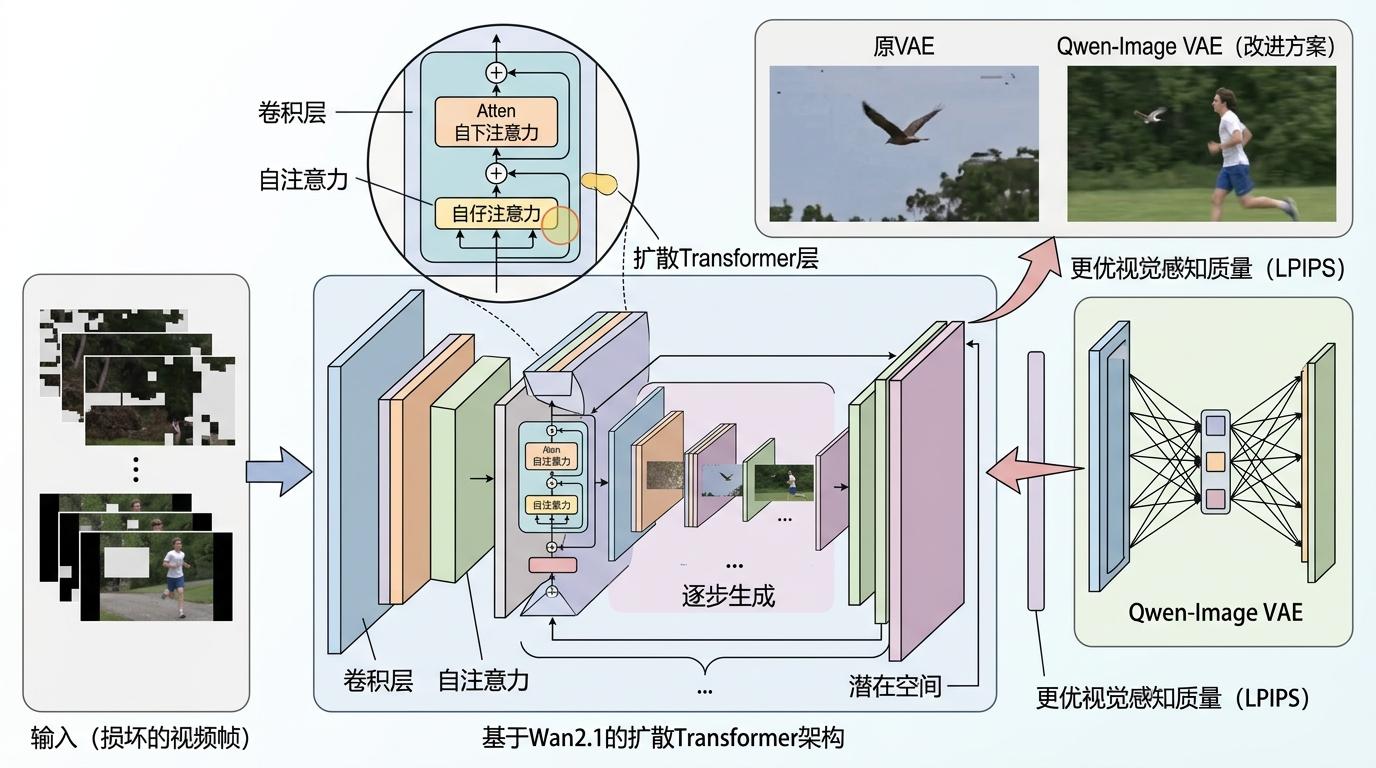
而RedMediaTech团队则是「重拳出击」,直接用上了AI生成领域的王牌——扩散模型。他们基于Wan2.1的扩散Transformer架构,把损坏的视频丢进去,模型就能根据周围的上下文「脑补」出缺失的内容,一步生成完整的帧。为了应对快速运动的场景,他们还把原模型的VAE换成了Qwen-Image VAE,让模型能更好地处理复杂动态。这套方案虽然像素精度略逊一筹,但视觉感知质量(LPIPS)拿到了第一,修复后的画面更自然,像没坏过一样。
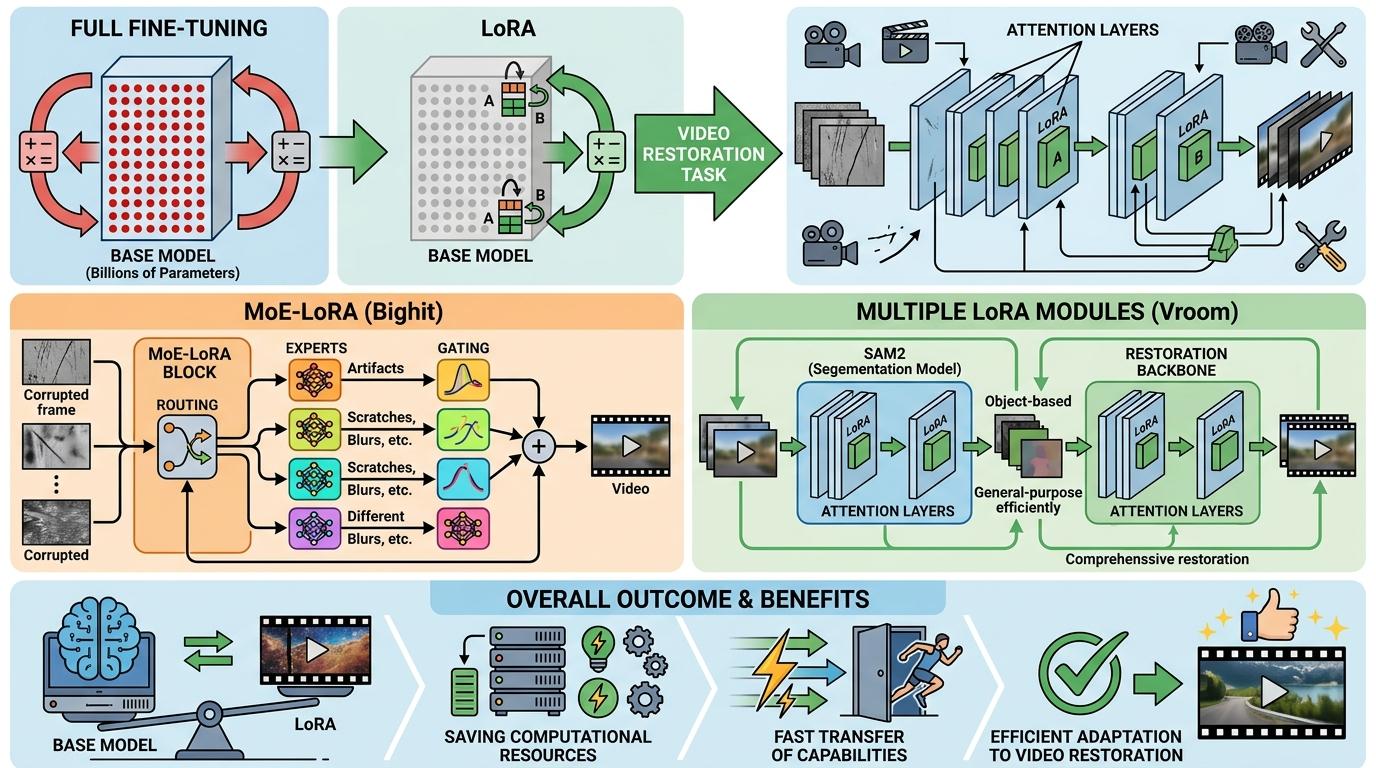
这次挑战赛透露出一个明确的趋势:没人再从零开始训练模型了,大家都在「站在巨人肩膀上」干活。几乎所有参赛队都用了「视觉基础模型+参数高效微调」的组合——比如用SAM2提取图像结构特征,指导边界修复;用DINOv3提取语义特征,从视频其他帧「回忆」类似内容来填空。
这里的关键是LoRA(低秩适应)技术。基础模型动辄几十亿参数,全量训练成本太高,LoRA只在模型的注意力层插入几个小矩阵,训练时只更新这些小矩阵的参数,就能让大模型适配视频修复任务。比如季军Bighit团队用了MoE-LoRA,让多个轻量级「专家」动态处理不同的损坏模式;第四名Vroom团队在SAM2和修复主干网络里都加了LoRA模块。一半的参赛队都用了这种技术,既省了算力,又能快速把大模型的能力迁移到具体任务上。
但顶尖方案的背后,依然藏着难以突破的瓶颈。从比赛的可视化结果看,哪怕是冠亚军的方案,在修复极精细的纹理——比如鸟笼的铁丝网、视频里的文字——时,还是会出现模糊或偏差;在处理长视频时,帧与帧之间的时序稳定性也不够,偶尔会有闪烁。AI能「脑补」出合理的大结构,但要100%还原原始细节,尤其是当比特流数据完全丢失时,依然做不到。
更现实的问题是计算成本。冠军的三阶段模型和亚军的扩散模型,推理时都需要大量算力,根本没法在手机、摄像头这些边缘设备上实时运行。现在的方案大多是实验室里的原型,要用到直播、视频通话这些实时场景,还得把模型压缩几十倍,同时保证修复质量不下降——这几乎是个不可能完成的任务。
NTIRE 2026挑战赛像一面镜子,照出了AI视频修复的现在和未来:我们已经能治好视频的「重伤」,但还做不到「完美复原」;我们能站在大模型的肩膀上快速前进,但还得解决落地的最后一公里问题。
更值得关注的是,这次比赛的核心不是比拼谁的模型更复杂,而是比拼谁能把现有技术组合得更巧妙——把基础模型的知识、高效微调的方法、多阶段的策略结合起来,就能解决以前解决不了的问题。这或许是AI应用的真正逻辑:不是要发明全新的技术,而是要把已有的技术用到对的地方。
技术进步永远在解决旧问题,同时制造新问题。AI能修好比特流损坏的视频,但要让每个人都能在手机上实时享受这种技术,还有很长的路要走。