对抗知识焦虑,从看懂这条开始
App 下载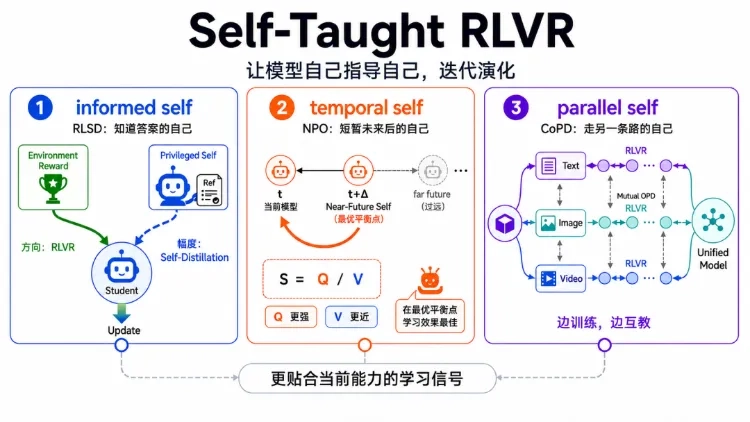
AI开始自己教自己,三条路径刷新进化逻辑
无监督学习|中科院信工所|京东|多模态任务|自我训练|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载无监督学习|中科院信工所|京东|多模态任务|自我训练|大语言模型|人工智能
当我们还在讨论怎么给AI喂数据、调参数时,有一群模型已经开始自己当自己的老师了——不用人类标注,不用专家示范,就靠“不同版本的自己”互相拉扯,性能居然比传统训练快了一倍,还能同时学会好几个领域的本事。2026年5月,京东与中科院信工所的团队公布了三套AI自我训练的核心方案,把“自己教自己”这件事拆成了三个可落地的技术路径。这不是实验室里的空想,而是已经在多模态任务上打败了现有基线的实用方法。更重要的是,它指向了一个没人敢轻易下定论的未来:AI的进化,或许真的可以脱离人类的手把手指导。
你可以把大模型的训练想象成做练习题:以前是老师把答案写在旁边,学生照着抄,但抄得多了会养成依赖——考试时没了答案,就会瞎编一个“标准答案”写上去。传统的自蒸馏方法就犯了这个错:给模型注入“特权信息”(比如参考答案)当老师,结果模型学歪了,反而会在推理时捏造自己没见过的答案。
该团队的RLSD方法把这件事拆成了两步:方向交给强化学习,由环境奖励判断每个输出是该夸还是该罚,保证大方向不跑偏;幅度交给自蒸馏,用“看见答案的自己”和“没看见答案的自己”的输出差异,调整每个细节的学习力度。就像学车时,教练只告诉你往哪开,而具体打多少方向盘,由你自己反复试错调整。
在多模态任务测试中,这套方法200步的训练效果就超过了传统方法400步的表现,还彻底解决了“捏造答案”的问题。但它也有局限:必须有明确的“特权信息”可用,在没有标准答案的开放任务里就派不上用场。
如果说RLSD是让“现在的学霸自己”教“现在的学渣自己”,那NPO就是让“明天的自己”来教“今天的自己”。传统的辅助学习信号要么太超前(比如直接用顶级专家的轨迹),模型学不会;要么太落后(比如用自己昨天的训练数据),没法突破瓶颈。
NPO的核心逻辑很简单:找一个比现在的自己强一点,但又没强太多的“近未来版本”当老师。这个“未来的自己”是沿着同一训练路径走了几步的模型,它的知识刚好是现在的模型踮踮脚就能够到的。研究团队用一个公式量化了这种平衡:有效学习信号=新知识量/学习难度,而“近未来的自己”刚好能让这个值最大化。
他们在Qwen3-VL-8B模型上测试,把传统方法的平均分从57.88拉到了63.15,还解决了训练后期容易陷入瓶颈的问题。更有意思的是,这个思路不止能用在强化学习里——只要是需要找合适学习目标的场景,“找一个比自己强一点的自己”都成立。
现在的大模型还有个难题:怎么让一个模型同时学会写代码、做数学题、理解图片?以前要么把所有数据混在一起训,结果模型会顾此失彼;要么先训好几个专家模型再合并,结果合并后的模型学不到专家的真本事。
CoPD方法给出了一个新解法:让几个“平行的自己”一起长大。一开始,它们都是同一个基础模型,然后分别去学不同的本事——一个学代码,一个学数学,一个学图像。但它们不是孤立的,每隔一段时间就会互相“上课”:学代码的模型会给学数学的模型讲怎么写推理步骤,学数学的模型会给学图像的模型讲怎么分析数据逻辑。
就像几个一起长大的兄弟,各自有自己的专长,但从小互相影响,最终每个人都能懂点其他人的本事。测试结果显示,用这种方法训出来的单一模型,不仅能打败每个单独的专家模型,还不会出现“顾此失彼”的情况。这可能预示着一种新的模型训练范式:未来的大模型,或许不是一个单一的“超级大脑”,而是一群“平行大脑”的协同体。
这三套方法看起来解决的是不同问题,但本质上是同一个逻辑:让AI自己给自己找最适合的学习节奏。以前我们总觉得,AI的进化需要人类不断投喂数据、调整算法,但现在我们发现,AI自己最知道自己该学什么,该怎么学。
当然,这并不意味着人类可以完全放手。这些方法的底层逻辑还是人类设计的,而且AI的“自我进化”目前还局限在给定的框架里——它还不会自己设定学习目标,更不会自己调整模型结构。但它确实撕开了一道口子:AI的进化,或许真的可以有自己的节奏。
最好的老师,永远是“刚好比你强一点的自己”。这句话不仅适用于AI,也适用于每一个在成长路上的人。