对抗知识焦虑,从看懂这条开始
App 下载
免费AI时代落幕,算力账单逼出行业新规则
电力成本|API调用费|GPU芯片|云服务商|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载电力成本|API调用费|GPU芯片|云服务商|AI算力|人工智能
当你上周还在免费调用AI写方案,这周就收到部分功能需付费解锁的提示时,可能没意识到——一场由电费和GPU芯片倒逼的行业革命已经到来。2026年4月,从云服务商到模型厂商集体调价、分层:有的把输入框分成“快速”和“专家”两个入口,有的给免费用户设置排队门槛,还有的悄悄把API调用费涨了83%。曾经无限畅用的AI“免费午餐”,正在变成需要按分量付费的“自助餐”。这一切的源头,是那个被用户忽略的隐形账单:AI每回答一个问题,都在烧掉真金白银的算力和电力。
你可以把AI大模型想象成一个超级能吃的“计算巨兽”——训练它的时候要喂进去几千万美元的“饲料”,也就是GPU集群、电力和训练数据;而每次回答问题的“推理”过程,就是它在持续啃食算力资源。
顶级模型单次训练成本高达数千万美元,GPT-3训练一次要耗掉1300兆瓦时电力,相当于美国130户家庭一年的用电量;GPT-4的训练能耗更是它的50倍。到了推理阶段,成本压力只会更大:一个复杂的AI查询,耗电量是传统谷歌搜索的60倍。而且用户量、问题复杂度每上升一个台阶,成本就会跟着线性甚至指数级增长。
免费模式下,平台就像在给无限多的人免费供应大餐——用户多了就会宕机,算力不够就会卡顿。有数据显示,C端用户80%的请求其实用低成本的轻量模型就能解决,但剩下20%的复杂问题,却要吃掉80%以上的算力资源。这就逼着厂商必须把用户和需求分层,让愿意为复杂服务付费的人,来承担对应的算力成本。
当算力成本的“地心引力”越来越强,AI行业正在形成一种“哑铃型”的商业范式:一头是免费的轻量模型,用来吸引流量、满足简单需求;另一头是付费的高端服务,针对复杂推理、专业场景收费。
比如有的厂商把对话分成“快速模式”和“专家模式”——前者用小模型快速响应,成本低、速度快;后者调用大模型深度处理,按token(可以理解为AI计算的“最小单位”,比如一个词或一个字)计费。还有的推出会员制,免费用户每月只能用几次深度分析功能,付费会员则解锁更高额度和专业工具。
这种分层不是厂商想“割韭菜”,而是成本倒逼的理性选择。有基金经理算了一笔账:如果80%的简单请求用低成本模型覆盖,能把整体算力消耗降低60%以上。而按token计费的模式,就像按用水量收水费——用多少付多少,既能让用户清晰感知成本,也能让厂商的投入和收益匹配。不过这种模式也有局限:如果用户的问题太复杂,token消耗会像流水一样上涨,可能带来超出预期的账单。
面对算力成本的压力,AI行业同时在打一场“降本战役”——从技术和硬件层面,想尽办法让AI“少吃快跑”。
模型压缩是最常用的手段:把模型的参数从32位浮点压缩到8位甚至4位,就像把一本厚书压缩成口袋本,既能减少内存占用,还能提升推理速度,能耗最多能降45%,而准确率损失几乎可以忽略。还有知识蒸馏技术,让小模型“模仿”大模型的输出,就像让学生抄学霸的作业,用小模型的成本获得接近大模型的效果。
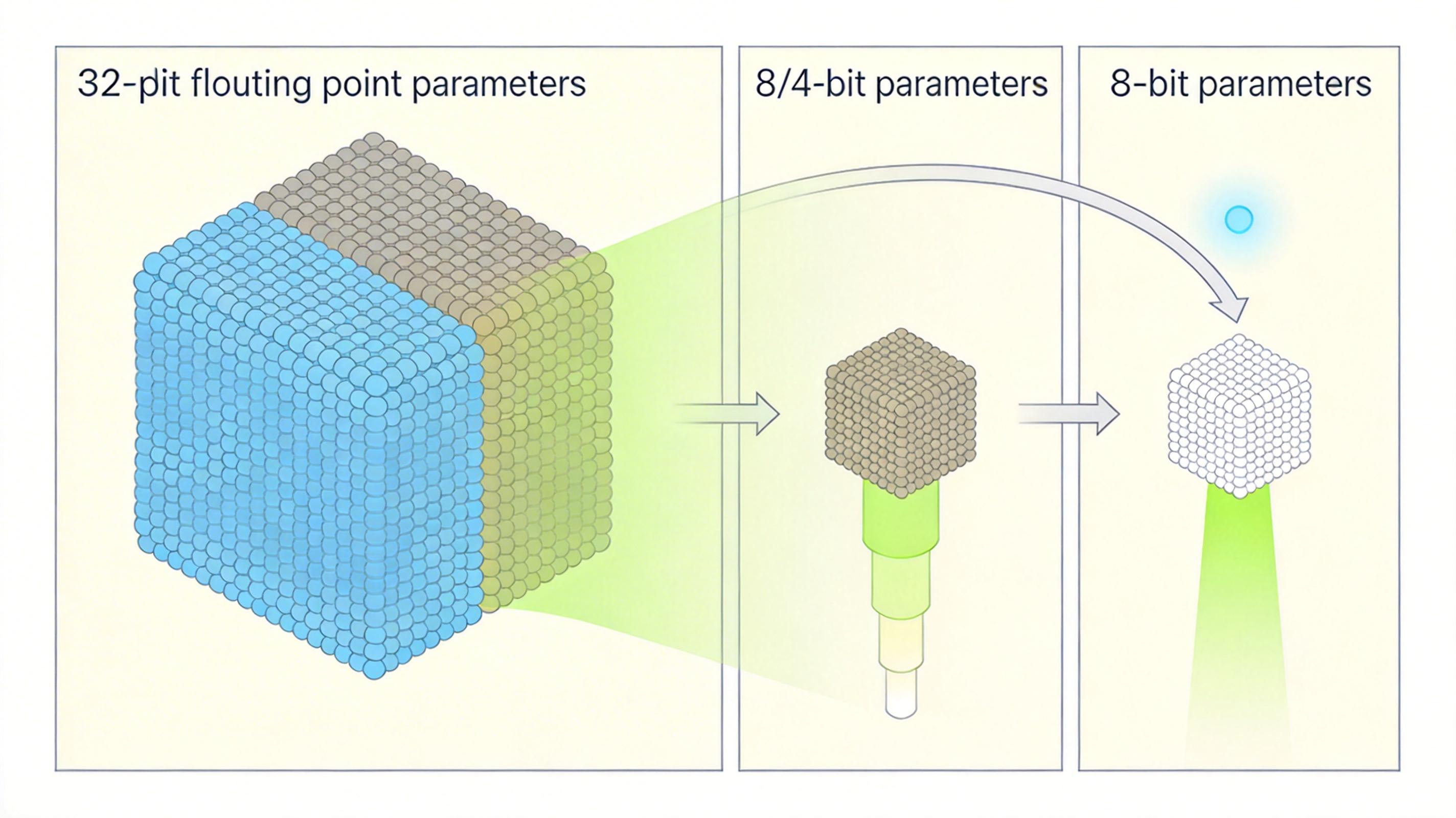
硬件方面,专用AI芯片、TPU正在替代部分GPU的工作,这些芯片针对AI计算优化,能效比更高。数据中心也在转向绿色节能:用液冷替代传统风冷,把PUE(数据中心能源使用效率)降到1.05左右,比传统数据中心节能15%以上。不过这些优化都有门槛,小厂商很难承担研发和硬件升级的成本,行业马太效应可能会越来越明显。

AI从“免费狂欢”走向“付费分层”,本质上是技术回归商业理性的过程。曾经我们以为AI是取之不尽的“魔法工具”,现在才发现它和所有产业一样,受限于物理世界的资源约束——GPU的数量、电力的供应、成本的核算。
算力成本的“地心引力”,正在把AI从云端拉回地面。它不再是资本烧出来的炫技玩具,而是要真正创造价值、匹配成本的产业工具。算力有界,价值无限——未来的AI,会在成本约束下,长出更高效、更务实的商业形态。而用户终会明白:那些能解决真问题的AI服务,从来都不便宜,但值得付费。