对抗知识焦虑,从看懂这条开始
App 下载
视频压缩不用像素块,靠语义Token省60%带宽
像素块替代|带宽节省|视频压缩|1D语义Token|微软亚洲研究院|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载像素块替代|带宽节省|视频压缩|1D语义Token|微软亚洲研究院|AIGC|人工智能
你有没有过这种经历:拍了段1080P的日常视频想发朋友,微信却提示“文件过大无法发送”?转成压缩包画质糊成马赛克,剪短又丢了关键内容——这背后是统治视频压缩几十年的“2D网格”逻辑在拖后腿:不管是蓝天还是人脸,都被切成大小固定的像素块逐块编码,明明用“一个人在笑”就能描述的内容,非要记录每块像素的颜色变化。2026年3月,微软亚洲研究院等团队的一项研究,直接把这套逻辑扔进了历史堆:他们用1D语义Token替代像素块,在保证画质的前提下,把视频体积砍去了60%以上。
传统视频压缩像切生日蛋糕:不管奶油花还是空白蛋糕胚,都切成大小一样的方块,每块单独打包。这种2D网格编码的问题在于,它看不到“奶油花是重点、蛋糕胚是背景”——简单区域和复杂区域用了一样多的编码资源,造成巨大浪费。比如一段奔跑的马的视频,马的轮廓是连贯的整体,却被切成上百个互不相干的块,明明“一匹马向前跑”一句话就能说清,却要逐块记录像素变化。
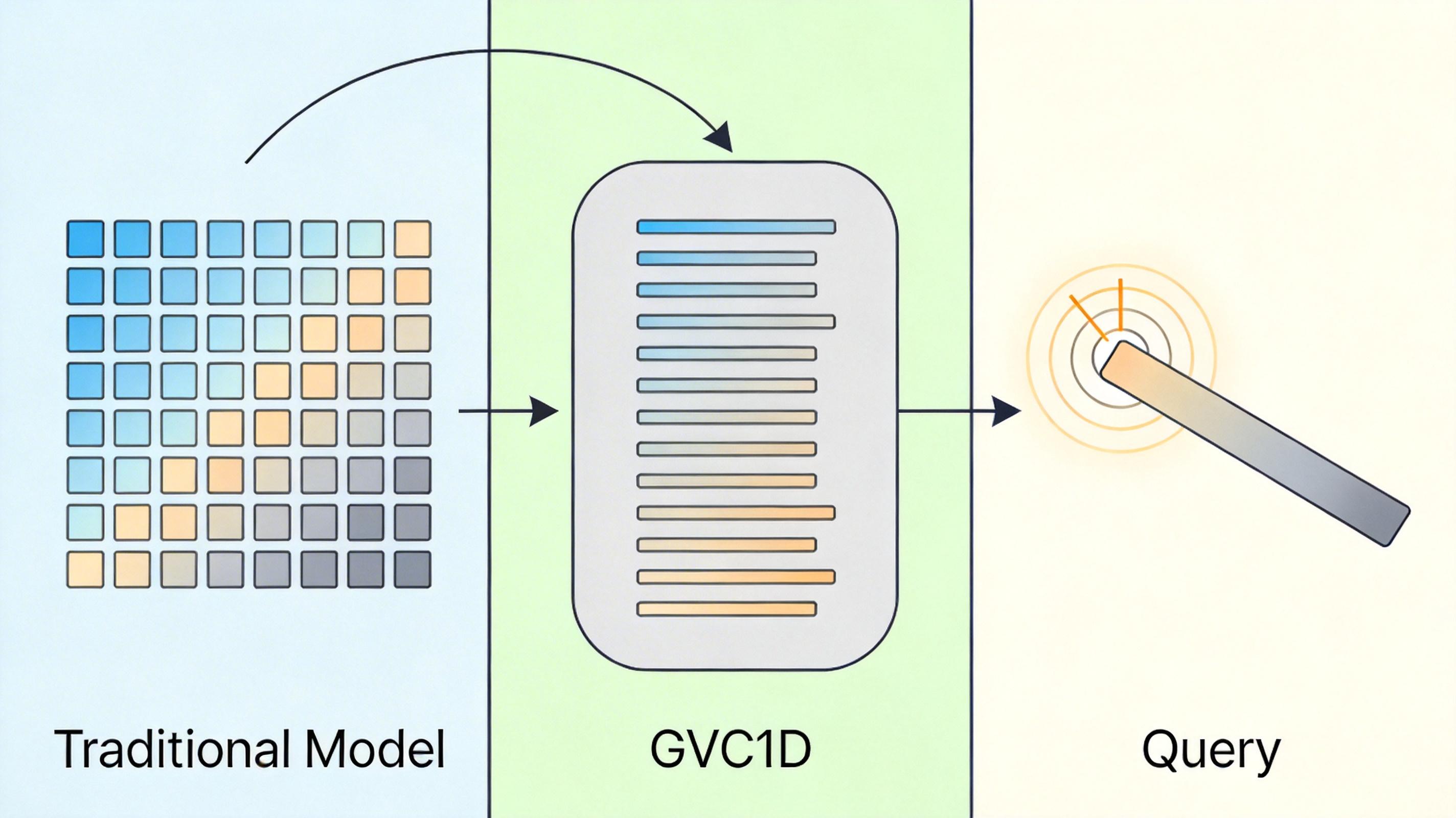
GVC1D的思路则像做读书笔记:不抄整本书,只把核心观点、关键人物摘成一条条笔记。它先把视频帧切成小像素块,再用Transformer的注意力机制,从这些块里“抓重点”,生成一组没有固定空间位置的1D语义Token。这些Token可能代表“人的脸部”“奔跑的马腿”“蓝天背景”,数量只有原始像素块的几十分之一,却承载了视频的核心语义信息。
直给技术要点:1D Token的数量和视频分辨率完全解绑——不管是720P还是4K,都能用32个左右的Token捕捉核心内容。这直接砍掉了2D网格带来的冗余,为压缩率的飞跃奠定了基础。
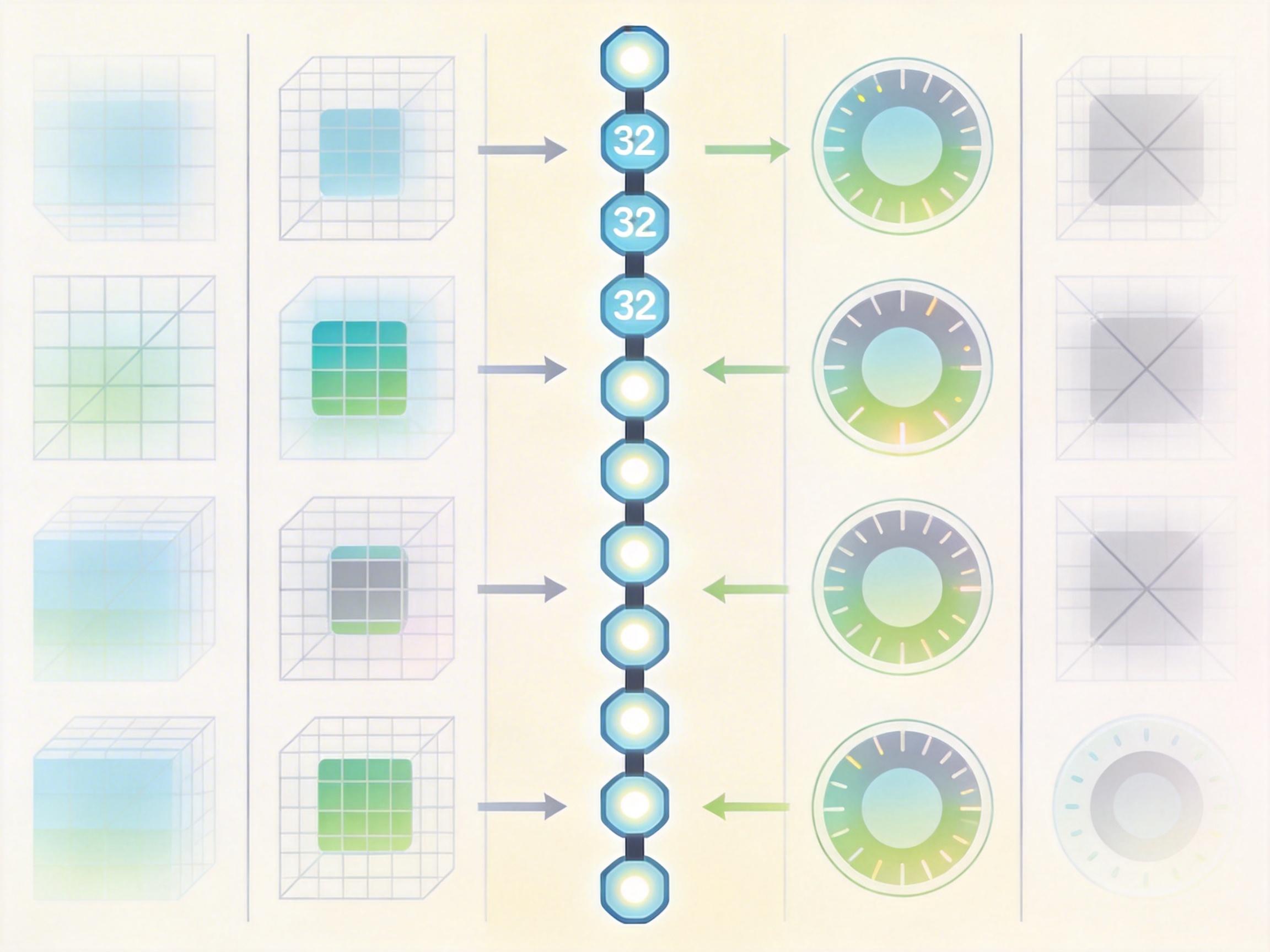
视频压缩的另一个难点是处理时间冗余——比如连续10帧里,只有人物的手在动,背景完全没变。传统方法靠“帧间预测”记住前一帧的内容,但面对长镜头、场景切换,这种“短期记忆”就不够用了。
GVC1D的第二个杀手锏是1D长期记忆模块。它不像传统方法那样存储前几帧的像素细节,而是把每帧的1D语义Token存入“记忆库”——相当于只记每段视频的“读书笔记”,而不是整本书。当需要编码新帧时,模型用查询Token从记忆库中提取关键语义,比如“3秒前出现过的戴眼镜的人”,而不是重新编码整个场景。
实验数据最有说服力:在HEVC-B数据集上,GVC1D比之前最好的感知编码器GLC-Video,在LPIPS指标上省了60.4%的比特率,DISTS指标更是省了68.8%——也就是说,达到同样的视觉质量,GVC1D只需要不到三分之一的带宽。低码率下的视觉对比更明显:传统编码会把栏杆纹理、人脸细节糊成一片,GVC1D却能还原出清晰的面部特征和衣服纹理,甚至比高码率的传统编码更自然。

不过,GVC1D离走进我们的微信聊天框,还有几道坎要跨。
首先是计算成本。虽然1D Token减少了码流,但它依赖的Transformer编码器、自回归熵模型都是计算大户——在A100 GPU上,1080P视频的编码时间是0.262秒,比部分高效神经编解码器慢了近30%。这意味着它暂时还跑不了实时视频通话,低功耗手机、智能摄像头这类设备更是难以承载。
其次是极端场景的泛化能力。目前GVC1D在自然视频上表现出色,但面对高速闪烁的游戏画面、风格化的动画、细节细碎的医学影像,它的语义Token可能抓不住重点——毕竟训练数据里这类内容占比不高,模型的抽象能力还没跟上。
最后是产业标准化。现在的GVC1D还只是个研究原型,要融入现有的视频生态,得解决和H.264、H.266等传统标准的兼容问题,还要说服硬件厂商为它开发专用解码芯片——这可不是一年两年能完成的事。
GVC1D的意义,从来不是“又快了多少、又小了多少”,而是它第一次把视频压缩从“处理像素”拉到了“理解内容”的维度。就像人类看书时不会逐字背诵,只会记住核心情节;未来的视频编码,也会越来越像“懂内容的智能编辑”,而不是“打包像素的流水线工人”。
当我们不再纠结“每块像素对不对”,而是关注“内容传没传清楚”,视频压缩的天花板才真正被打开。压缩的本质,是对信息的精准理解。 或许用不了多久,我们发4K视频就像发文字一样轻松——不是因为带宽变宽了,而是我们终于学会了只传真正重要的东西。