对抗知识焦虑,从看懂这条开始
App 下载
大模型不再向外借算力,转而自己挖潜力
AI数学题解题|自监督学习|错误轨迹利用|陈丹琦团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI数学题解题|自监督学习|错误轨迹利用|陈丹琦团队|大语言模型|人工智能
当你让AI解一道数学题,它可能算出错误答案,也可能瞎蒙出正确结果——但此前没人在意它算错时脑子里转过的弯。直到2026年,普林斯顿大学陈丹琦团队的两项研究,把这些被当成垃圾的错误轨迹,变成了让AI变聪明的核心养料。他们彻底放弃了“靠更大模型喂答案、靠堆算力砸出正确结果”的老路,转而让AI自己当自己的老师,从自己的错误里抠出进步的门道。这不仅能把训练成本砍到原来的几分之一,更让AI在没有外界帮助时,也能越算越聪明。问题是,这到底是怎么做到的?
你可以把AI做数学题的过程想象成一个学生考试:以前老师只会给个对勾或叉号,学生根本不知道哪步错了,下次还是会在同一个地方栽跟头。这就是传统强化学习的困境——只能根据最终结果给“二元奖励”,反馈信号太稀疏,AI找不到改进的方向。
陈丹琦团队的SD-ZERO方法,相当于让这个学生自己当自己的老师。它让同一个AI模型分饰两角:一个是“做题的学生”,生成初始答案;另一个是“改作业的老师”,对着答案和对错结果,不仅要写出正确答案,还要标注出错误步骤。
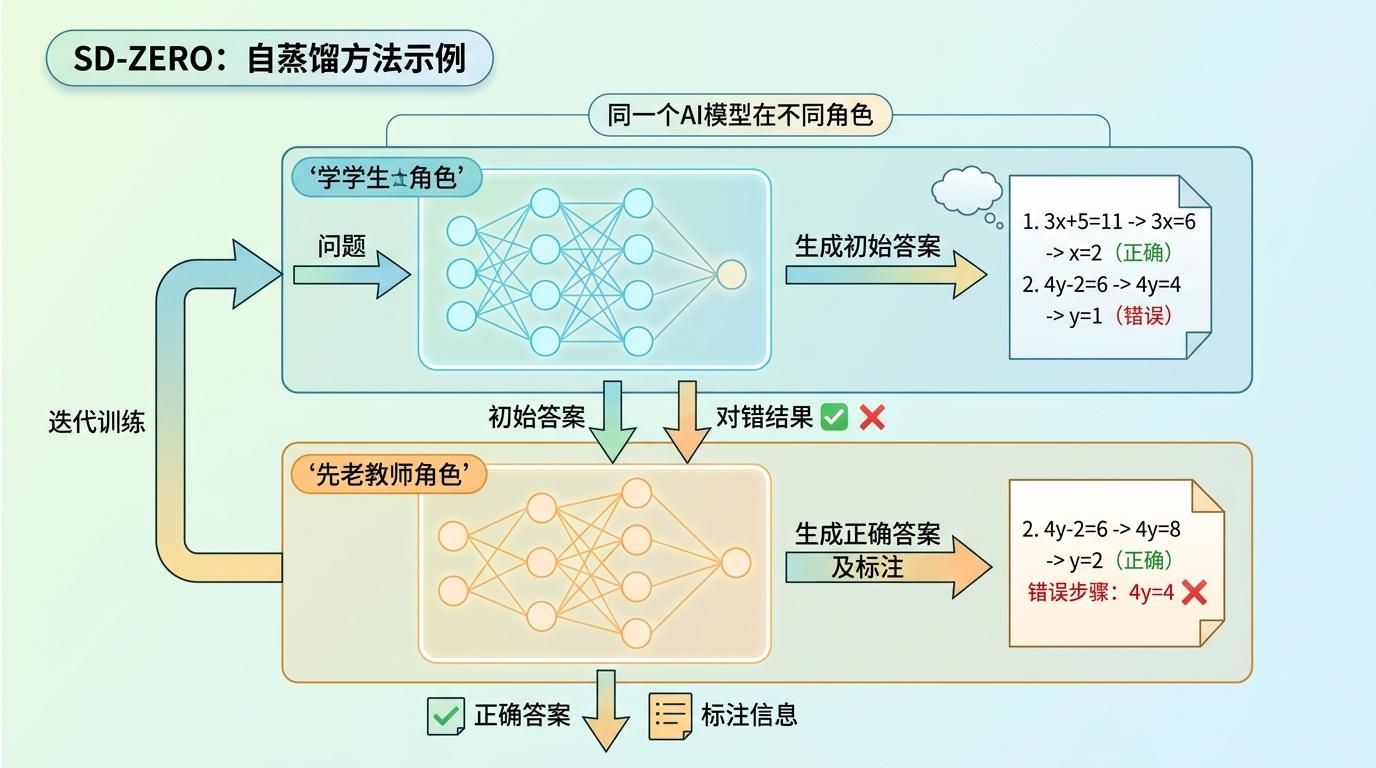
这个过程分两步:第一步是“自我修正训练”,AI会生成多个版本的答案,用外部工具验证对错后,对正确答案学习“怎么讲清楚思路”,对错误答案学习“怎么指出错在哪、重新推导”;第二步是“自我蒸馏”,把“老师”改作业的能力,浓缩成细到每个字符的监督信号,“喂”回“学生”模型里。
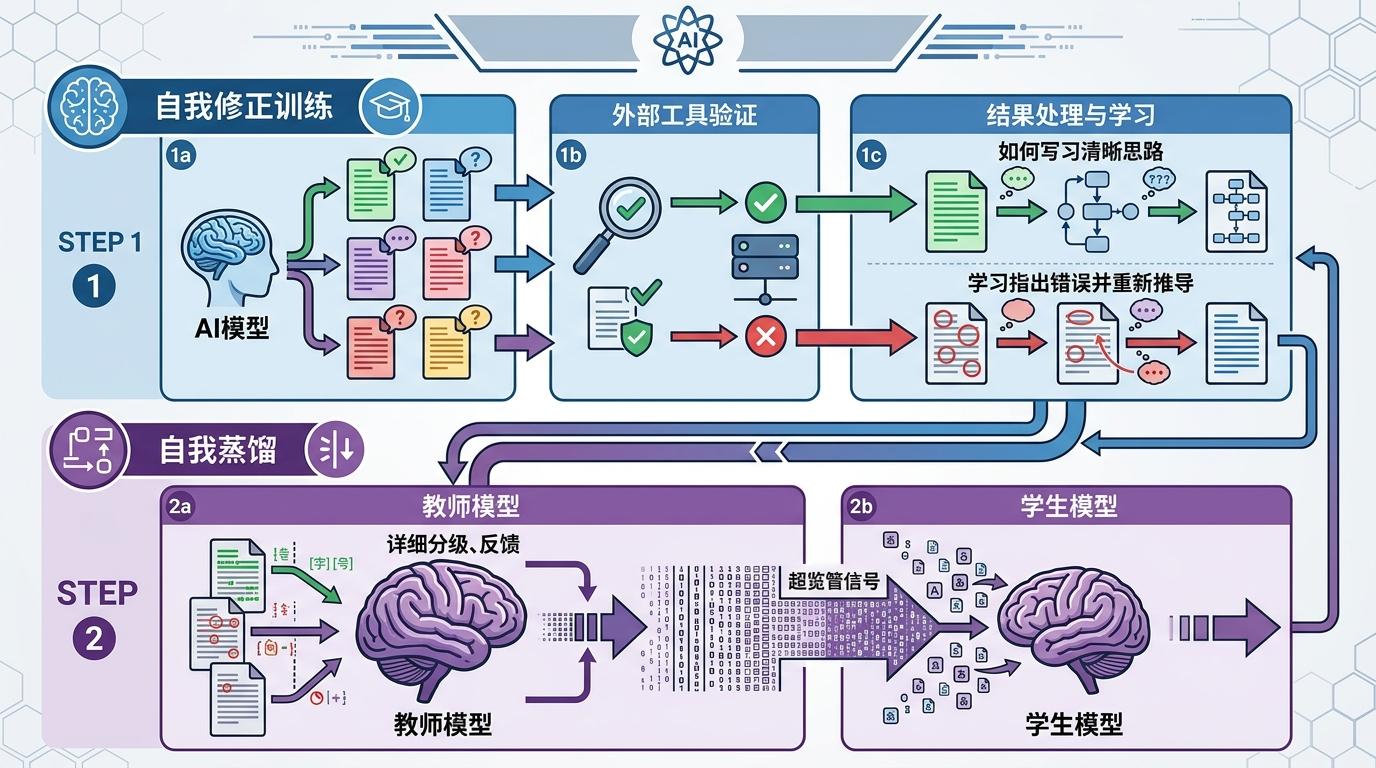
结果是,AI不用再等外部老师的指导,就能从自己的错误里精准定位问题。在数学和代码推理任务中,它用同样的训练样本,准确率比传统方法提升了10%以上,输出的内容还缩短了一半——因为它学会了一开始就避开错误,不用再反复试错凑答案。
如果说SD-ZERO解决的是“训练时怎么自己教自己”,那AggAgent解决的就是“考试时怎么自己检查答案”。在需要多步推理的复杂任务里,比如写代码、做科研调研,传统方法要么让AI生成多个答案投票选最多的,要么把所有答案凑成摘要——但前者会错过少数正确的答案,后者不仅费算力还容易丢关键信息。
AggAgent的思路,是把AI生成的多条推理轨迹,当成一个可以搜索的“案发现场”。它专门设计了一个“聚合智能体”,就像一个侦探,拿着四个工具在轨迹里找线索:可以调取所有轨迹的阶段性结论,在特定轨迹里搜关键词,精准提取某一步的原始思考,最后把这些线索拼成完整的正确答案。
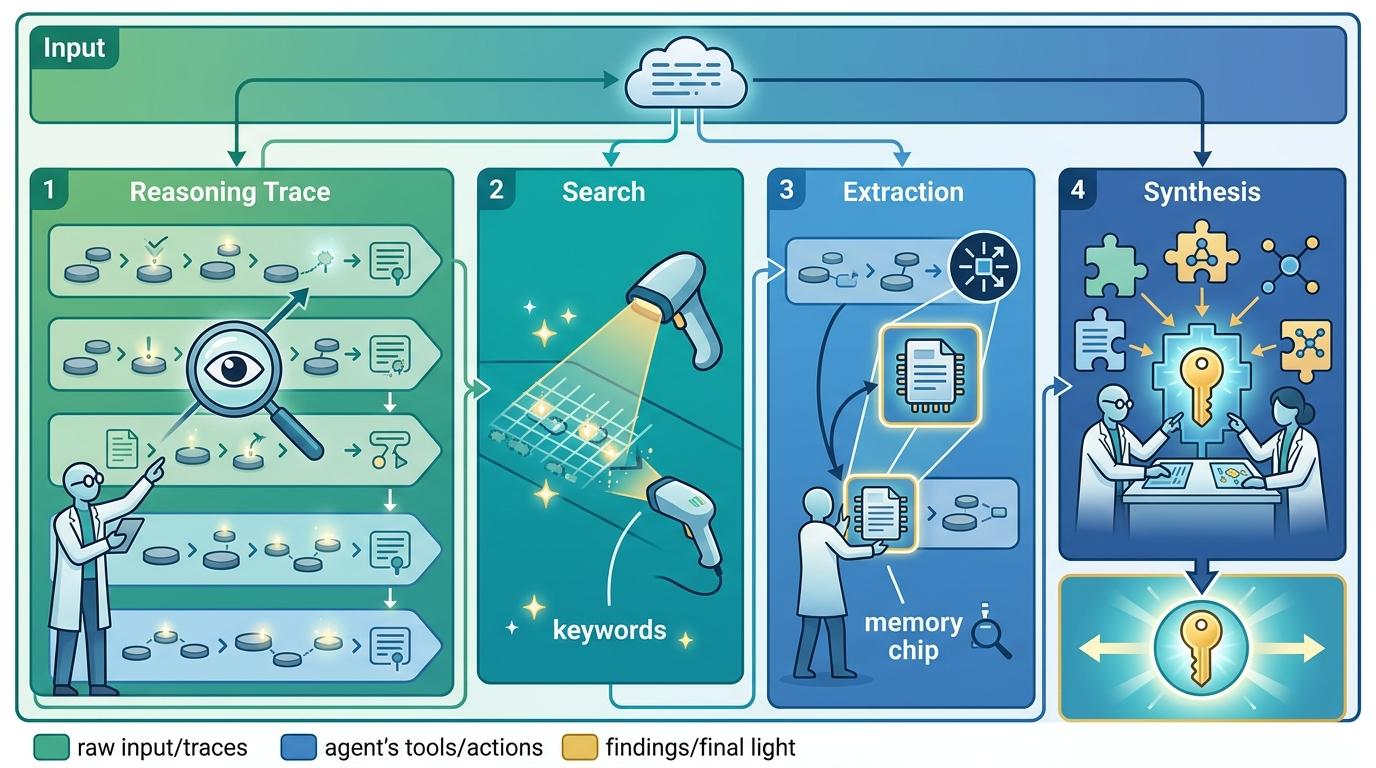
这个方法的厉害之处在于,哪怕8条轨迹里只有一条是对的,它也能通过跨轨迹的逻辑核对,把正确的证据链找出来;甚至能从多条失败的轨迹里,把零散的正确碎片拼出完整答案。更重要的是,它的额外算力消耗只有5.7%,远低于传统摘要聚合的41%——相当于用一杯咖啡的钱,干了一顿大餐的活。测试显示,它能让AI在长周期任务中的准确率平均提升5.3%,在深度研究任务里的提升更是超过10%。
SD-ZERO和AggAgent的底层逻辑其实是同一个:AI在推理过程中产生的所有中间步骤,不管对错,都是宝贵的“思考痕迹”,而不是该被丢弃的垃圾。这背后是AI“元认知”能力的觉醒——它开始能监控自己的思考过程,发现错误,甚至调整思路。
以前的AI更像一个只会刷题的机器,刷得越多可能分数越高,但不知道自己为什么对、为什么错;现在的AI开始像一个会反思的学习者,不仅能改自己的作业,还能从自己的错题本里总结规律。这种转变的意义,远不止提升几个百分点的准确率:它让AI摆脱了对“更大模型”“更多算力”的依赖,哪怕是小模型,也能通过自我反思获得接近大模型的推理能力;它还让AI的推理过程更透明,更容易找到出错的环节,为构建更安全、可信的AI打下基础。
当然,这种方法目前还有局限:比如SD-ZERO主要适用于数学、代码这种有明确对错的任务,在没有标准答案的开放领域,还需要找到新的“自我监督”方式;AggAgent的线索拼接能力,也还需要更复杂的逻辑判断来支撑。但不可否认的是,这条“向内挖潜力”的路,已经为AI的未来打开了新的大门。
当我们还在比拼AI的参数有多大、算力有多强时,陈丹琦团队的研究像一把钥匙,打开了AI“自我成长”的黑箱。我们终于意识到,AI的潜力,从来都不是藏在更大的模型里,而是藏在它每一次思考、每一次试错的轨迹中。
从向外借用到向内挖掘,这不仅是技术路径的转变,更是对AI认知的重塑:未来的AI,不再是一个需要不断投喂数据和算力的“巨婴”,而是一个能自我反思、自我进化的学习者。
错误不是垃圾,是成长的养料。