对抗知识焦虑,从看懂这条开始
App 下载
AI读懂代码算对数学,靠的是这两套机制
双模态理解|AI核心研究者|改写规则机制|数学推理|代码智能|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载双模态理解|AI核心研究者|改写规则机制|数学推理|代码智能|大语言模型|人工智能
当你用中文说"写个冒泡排序算法",AI能立刻吐出可运行的Python代码;给它一道高中竞赛级数学题,它能像学霸一样一步步推导到正确答案——这些在今天习以为常的功能,背后站着一位31岁的研究者。他的论文被引用超3.7万次,是代码智能和数学推理领域的隐形支柱。2026年3月,这位核心人物的离职,让AI圈突然意识到:那些让AI突破能力边界的技术,原来和具体的人绑定得如此紧密。而支撑AI读懂代码、算对数学的,正是两套改写规则的底层机制。
你可以把早期的AI代码模型想象成只会背单词的外语学习者——能认出代码里的每个符号,却看不懂整段代码的逻辑,更没法理解人类用自然语言说的"我要一个能统计用户行为的函数"。直到2020年,CodeBERT的出现打破了这堵墙。
这是首个能同时处理自然语言和编程语言的双模态预训练模型。它的核心创新是把两种完全不同的语言放进同一个训练体系:一边是213万对"自然语言描述-代码片段"的配对数据,让AI学习"统计用户行为"和user_behavior_counter()之间的对应关系;另一边是645万条无注释的纯代码,通过一种叫"替换标记检测"的任务,让AI像玩找不同游戏一样,学会识别代码里的语义逻辑。
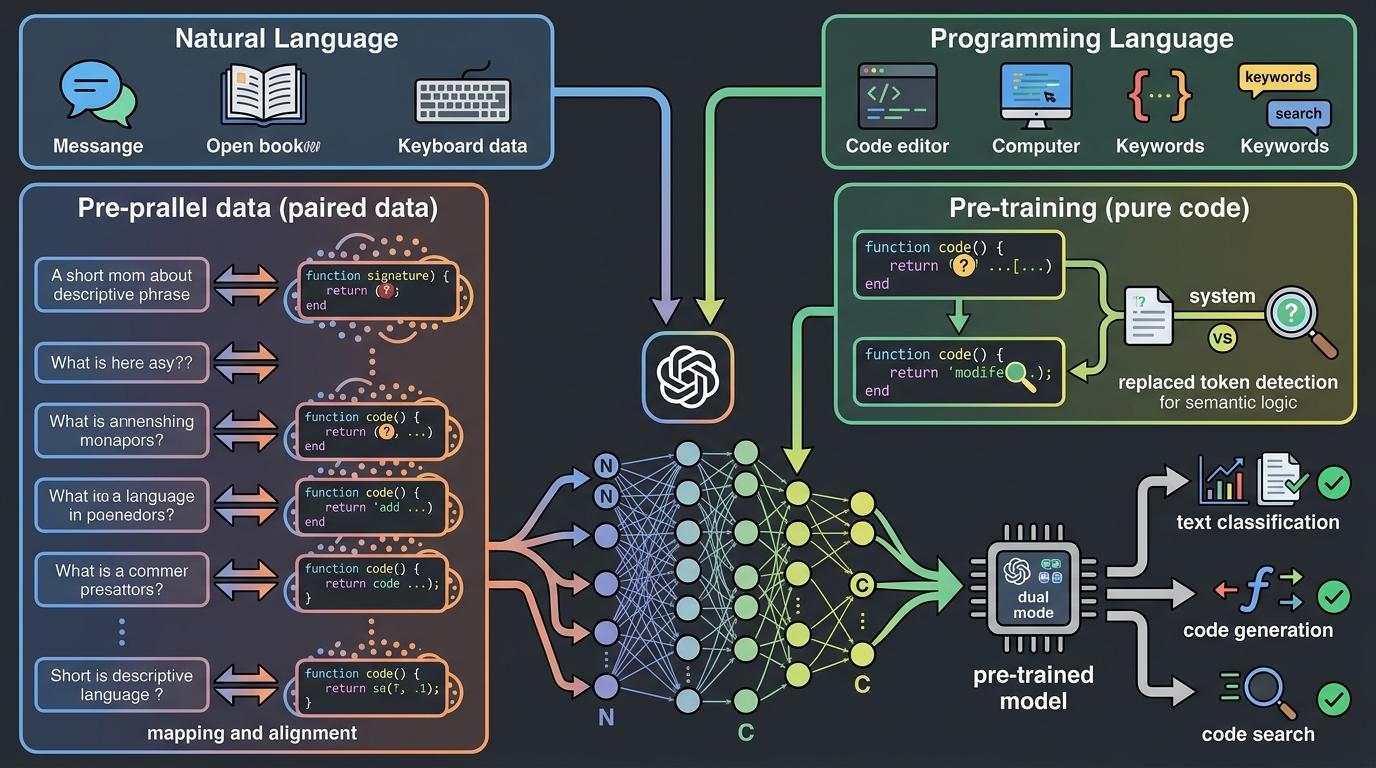
简单说,之前的AI看代码是看一串符号,CodeBERT看代码是看一段有意义的"文字"——它能把人类的需求翻译成代码,也能把代码翻译成人类能懂的说明书。这种能力后来成了所有AI代码工具的基础,从GitHub Copilot到各类代码助手,本质上都是这套双模态思路的延伸。
如果说双模态预训练解决了AI"听懂问题"的难题,那数学推理就是要让AI"会解难题"。2024年之前,大模型做数学题经常犯低级错误,要么算错加减乘除,要么在多步骤推导中逻辑崩盘,而且训练这类模型需要巨量的算力——直到GRPO算法的出现。
GRPO的全称是群体相对策略优化,它是对传统强化学习算法PPO的一次简化革命。传统PPO训练AI做数学题时,需要同时训练两个模型:一个负责解题,一个负责给答案打分(价值函数),就像老师既要教学生做题,又要实时批改作业,成本极高。
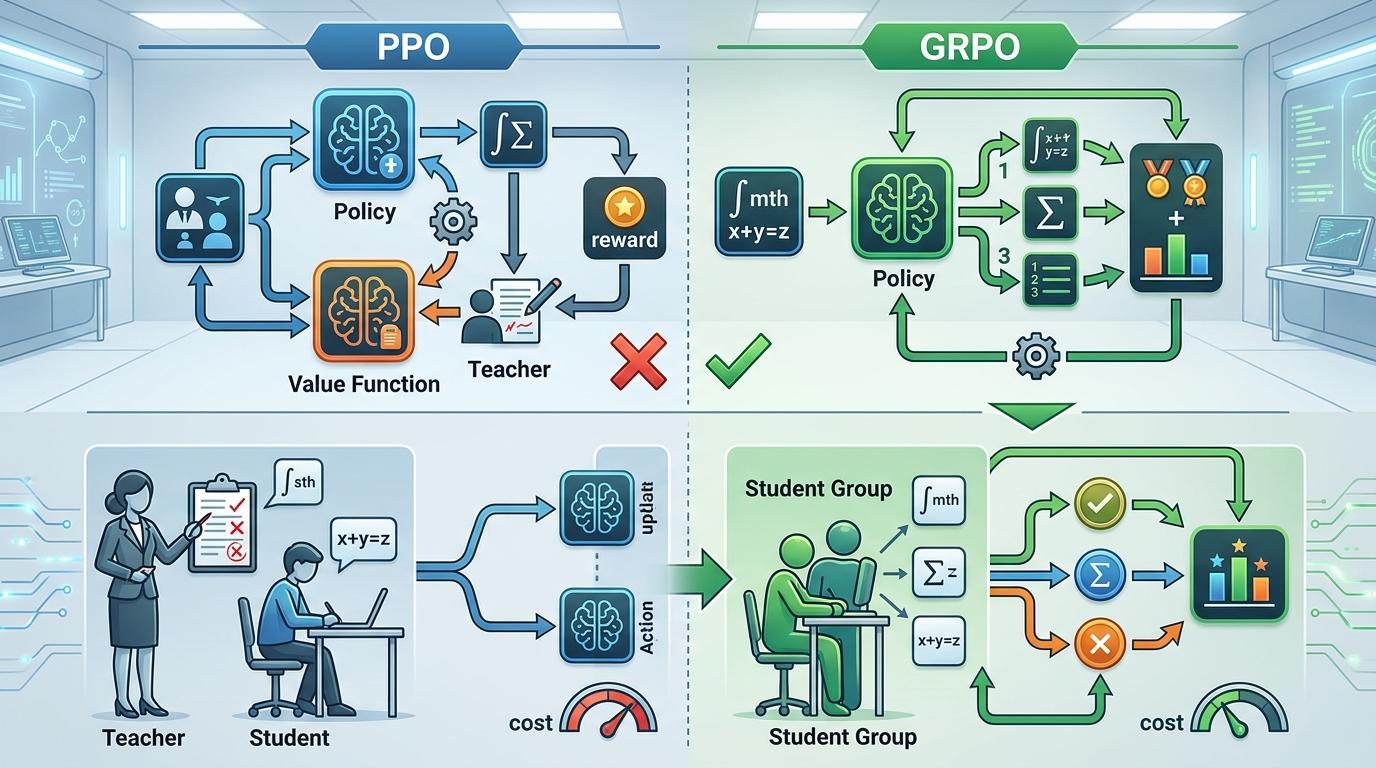
GRPO直接砍掉了打分的模型。它让AI针对同一道数学题生成多个答案,然后只比较这些答案的相对好坏——比如给正确答案打1分,错误答案打0分,再让AI学习"怎么生成更多得1分的答案"。这种方式不仅把训练资源消耗降低了一半,还让AI的数学推理能力突飞猛进:用70亿参数的模型,在MATH竞赛数据集上拿到了51.7%的准确率,性能接近GPT-4和Gemini-Ultra。
更关键的是,GRPO不需要依赖人类标注的偏好数据,只要能自动验证答案对错就能工作——这让它能快速推广到所有有明确对错标准的任务上,比如代码调试、逻辑推理,甚至是化学分子式推导。
但这些技术还远没到完美的地步。在实验室的基准测试里,AI能在代码生成和数学推理上拿到高分,但一到真实世界就露怯:面对超过10万行的大型代码库,AI会因为上下文太长而"失忆";面对需要结合多个领域知识的复杂数学题,AI会在中间步骤逻辑断裂。
比如在真实的软件开发场景中,代码不是孤立的函数,而是嵌套在多层类、依赖第三方库、包含异常处理的复杂系统——目前最好的AI模型在处理这类任务时,准确率会比处理简单函数下降50%以上。数学推理也是一样,实验室里的题目都是标准化的,但真实世界里的问题往往没有明确的题干,需要先拆解问题,再选择合适的方法。
为了突破这些天花板,现在的研究者正在把双模态预训练和GRPO这类算法结合起来:让AI用代码的逻辑来辅助数学推导,用数学的严谨性来优化代码生成;同时拉长模型的上下文窗口,让AI能处理百万级别的代码或推理步骤。但这些进步,依然离不开像郭达雅这样的研究者在底层机制上的持续创新。
当我们讨论AI的代码智能和数学推理能力时,很容易陷入对参数规模、跑分数据的追逐,却忽略了真正驱动进步的,是那些改写底层规则的机制创新——是让AI能跨语言理解的双模态预训练,是让AI能用更少资源学更多的GRPO算法。
技术的迭代永远会有新的突破,但每个突破的背后,都是一个个研究者在实验室里反复试错、打磨细节的结果。机制创新,才是AI智能跃迁的核心引擎。未来AI能走多远,依然取决于我们能找到多少像双模态预训练、GRPO这样,能让AI真正"理解"和"思考"的底层逻辑。