对抗知识焦虑,从看懂这条开始
App 下载
AI架构地震:扩散模型挑战自回归霸权,速度快10倍?
文本生成|AAAI大会|自回归模型|扩散语言模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载文本生成|AAAI大会|自回归模型|扩散语言模型|大语言模型|人工智能
在人工智能的世界里,一个“王朝”已经统治了数年。以GPT系列为代表的自回归(Autoregressive, AR)模型,如同一个严谨的线性思想家,通过“逐字预测”的方式构建出流畅的文本,奠定了当前大语言模型的基础。然而,这位思想家有一个致命弱点:它只能向前看,一旦落笔,便无法回头修改,这导致了逻辑谬误、前后矛盾等一系列“原罪”。现在,一个颠覆性的挑战者正从阴影中走出,它不按常理出牌,它的思考方式更像一位艺术家——它就是**扩散语言模型(Diffusion Language Model, DLLM)**。
这场架构之战的号角,在2026年2月初的AAAI顶会上被正式吹响。
2026年2月8日,华为诺亚方舟实验室的研究员王云鹤在AAAI会议上分享了团队在扩散语言模型上的最新进展。这场报告并非一次简单的成果展示,而是一次深刻的行业自省和未来路线的公开探讨。王云鹤和他的团队直面了扩散模型当前面临的九大核心挑战,从底层的注意力机制、词表设计,到训练范式、推理效率,再到更高阶的思维链构建和多模态统一架构的可能性。
报告的核心问题振聋发聩:**扩散模型能否突破自回归模型的局限,成为通往下一代通用智能的关键路径?**这个问题不再是学术圈的喃喃自语,而是伴随着蚂蚁集团、字节跳动、谷歌等巨头以及Inception Labs等初创公司的纷纷入局,变成了整个AI领域无法回避的战略抉择。
要理解这场变革的深刻性,必须回到两种模型最底层的“思维模式”差异上。
自回归模型(AR):像一个循规蹈矩的作家,从第一个字开始,依次写下第二个、第三个……每一步都依赖于之前的所有内容。这种“因果链条”保证了文本的局部流畅性,但也带来了无法并行、难以纠错的“线性枷锁”。正如Yann LeCun等AI巨擘所批评的,这种模式限制了模型的真正推理和规划能力。
扩散语言模型(DLLM):则像一位雕塑家。它从一整块“充满噪声”的混沌材料开始,通过一步步“去噪”和“精炼”,逐渐让清晰的、完整的作品浮现出来。它不是逐字生成,而是并行地、全局地优化整个文本。这种“完形填空”式的生成方式,赋予了它天然的几大优势:
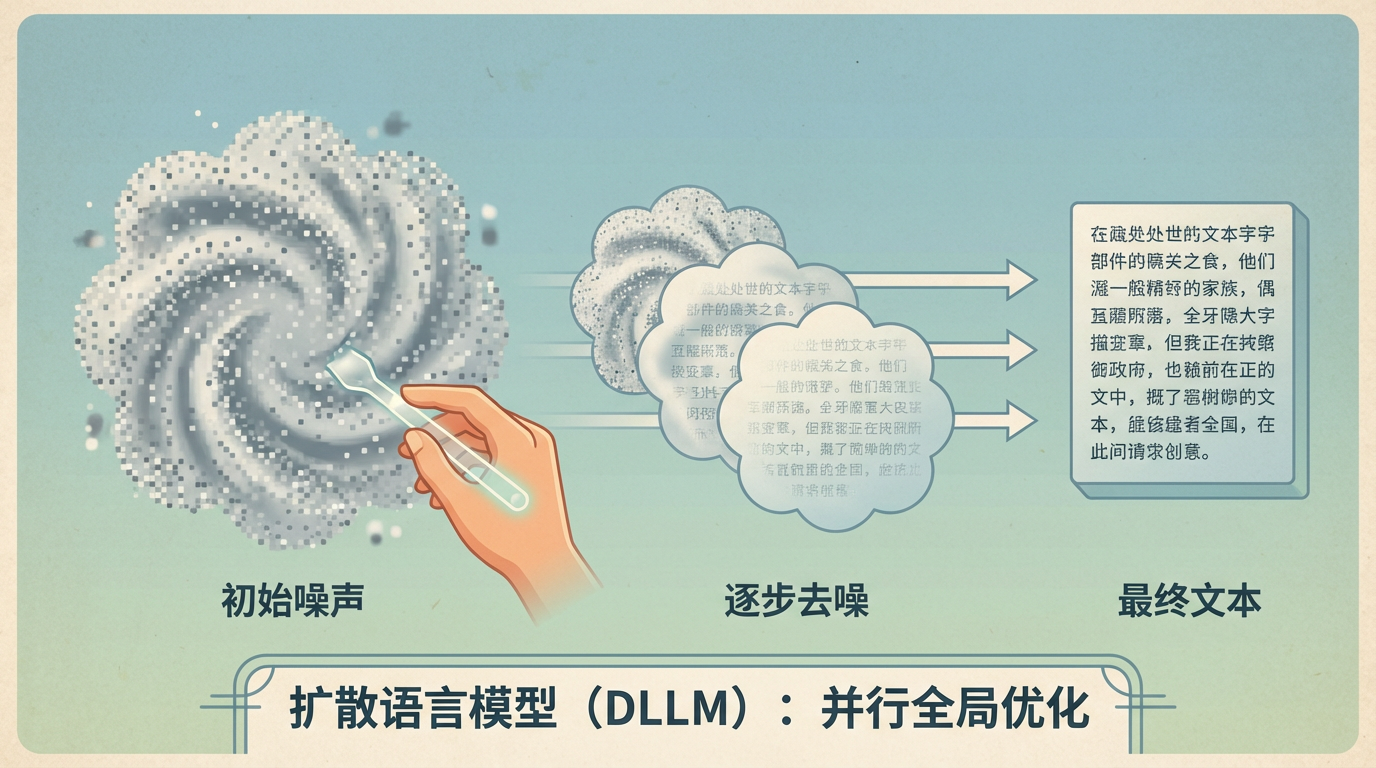
这场对决,本质上是“顺序思维”与“整体思维”的较量。而后者,似乎更接近人类创作与思考的本质。
尽管前景诱人,但正如王云鹤在报告中指出的,扩散模型的崛起之路布满荆棘。幸运的是,一场全球范围内的“突围战”已经打响,研究者们正用一系列天才的创新来逐一攻克难关。
推理效率的瓶颈:扩散模型的随机掩码使其无法利用自回归模型高效的KV Cache机制。为此,上海交通大学团队提出了**dLLM-Cache,通过复用相邻去噪步骤中变化不大的特征,实现了高达9倍的无损加速。英伟达与港大联合提出的Fast-dLLM**框架,则通过分块缓存和置信度并行解码,实现了惊人的27.6倍加速。
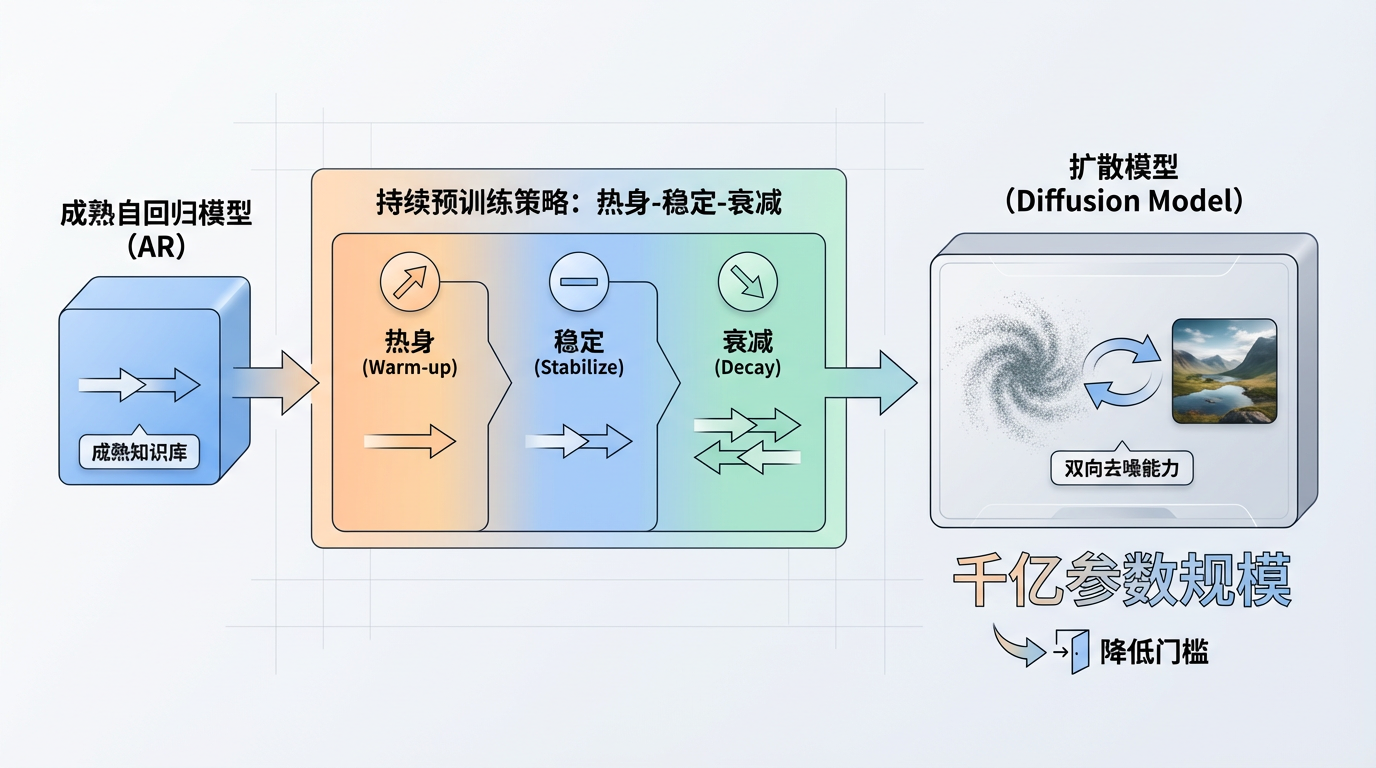
训练范式的革新:从零开始训练扩散模型成本高昂且不稳定。蚂蚁集团与中国人民大学联合推出的LLaDA 2.0项目给出了巧妙的解决方案:将成熟的自回归模型“平滑地”转化为扩散模型。他们通过一套精巧的“热身-稳定-衰减”持续预训练策略,让模型在继承AR模型知识的同时,学会了扩散模型的双向去噪能力。这一思路极大地降低了门槛,并成功将扩散模型推向了千亿参数规模。
如果说在纯文本领域,扩散模型尚在追赶,那么在多模态和智能体的未来战场上,它可能拥有“主场优势”。
扩散模型的统一生成框架,使其能更自然地融合不同模态的数据。传统的AR模型处理图文时,往往需要独立的编码器和解码器,而扩散模型可以将图像、文本甚至动作指令都视为可以“去噪”的信号。字节跳动的MMaDA模型已经在一个统一的扩散架构下,实现了文本、多模态理解和文生图三大能力。蚂蚁与人大推出的LLaDA-V也证明了扩散模型在视觉指令遵循上的强大潜力。
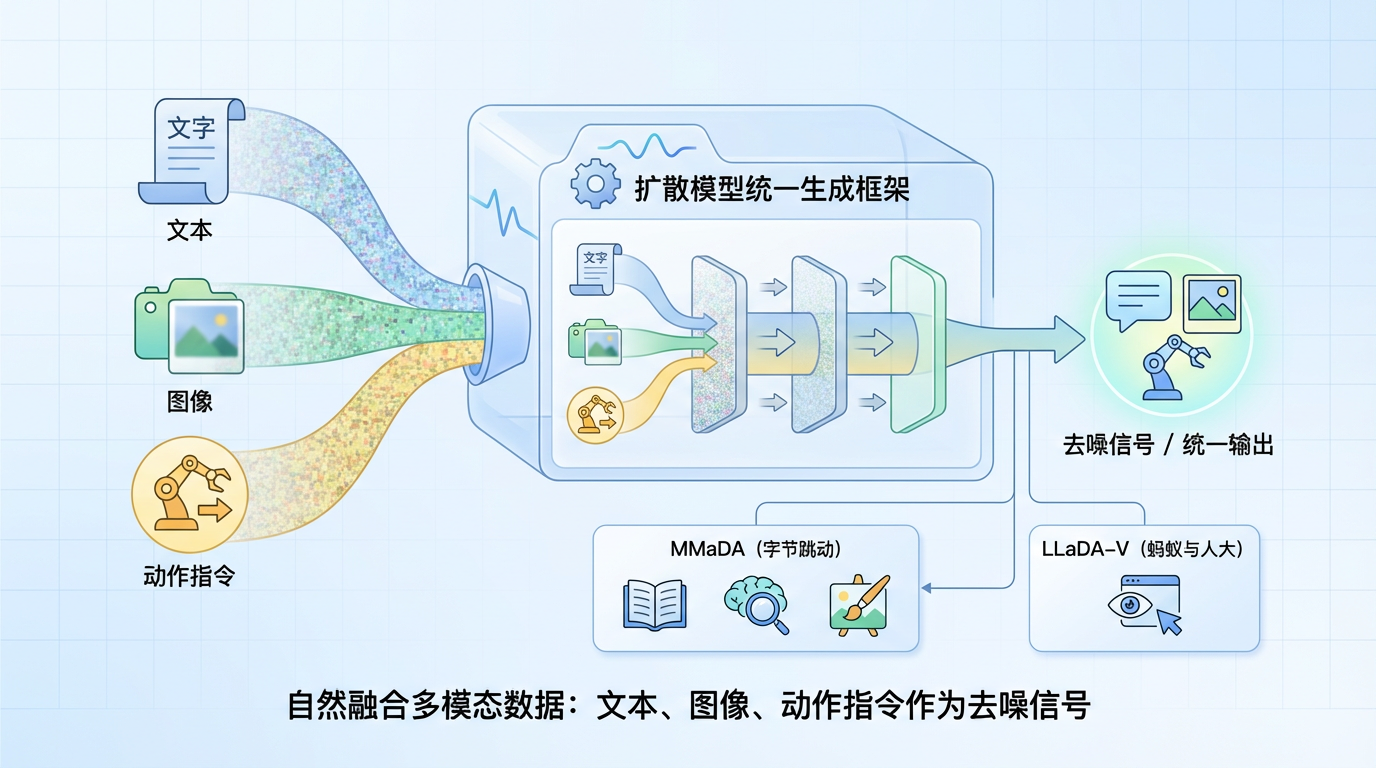
在更复杂的智能体(Agent)任务中,扩散模型的“规划-修改”能力显得尤为重要。智能体执行任务需要一个全局的计划,并根据环境反馈不断修正。扩散模型先生成整体方案(草稿),再局部优化的特性,与Agent的运作模式不谋而合。这正是王云鹤团队认为“diffusion搞到代码和agent场景很有意思”的原因所在。
通往未来的道路并非坦途。扩散模型依然面临挑战:如何保证生成内容的逻辑一致性和事实准确性?如何在大规模并行生成中避免“局部不连贯”的“并行生成诅咒”?以及,当模型具备强大的修改和“填空”能力时,如何防范其被用于制造更逼真的虚假信息?
此外,自回归模型自身也在进化,其庞大的生态系统和技术积累仍是巨大的护城河。未来的AI架构,可能不是一场零和游戏,而是两种范式的融合,例如采用“块级自回归+块内扩散”的混合模式,取长补短。
从实验室的理论探索,到千亿参数模型的成功训练,再到商业产品的惊艳亮相,扩散语言模型在短短一两年内走完了自回归模型数年的路。它以一种全新的、更灵活、更高效的“思考”方式,冲击着既有的AI范式。
这场由AAAI会议上的深刻追问所点燃的架构之战,远未结束。它不仅关乎代码、效率和参数,更关乎我们如何定义和构建“智能”。我们正在从教会机器“线性说话”,迈向教会它“整体思考”。无论最终谁将主导未来,这场竞争本身正在将人工智能推向一个更强大、也更接近人类心智的全新高度。下一个关键突破,或许就在不远的将来。