对抗知识焦虑,从看懂这条开始
App 下载
AI看图能拿满分,动起来却连入门都难
AI评测|主动探索|空间推理|李飞飞团队|ESI-Bench|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI评测|主动探索|空间推理|李飞飞团队|ESI-Bench|多模态视觉|人工智能
当你想知道抽屉里有没有东西时,会直接拉开看;想确认杯子容量,会倒进水试一试。但过去AI做空间推理题,只能盯着静态图片猜——就像让一个被绑在椅子上的人,判断身后柜子里藏着什么。
2026年5月,李飞飞团队发布的ESI-Bench,第一次把AI从“看客”拉成了“行动者”:它要求AI必须主动移动、操作、探索,才能拿到解题的关键信息。而测试结果让所有人意外:当下最顶尖的多模态大模型,在被动看图时能逼近人类水平,但一到要自己“动起来找答案”时,准确率暴跌最多超80%。这到底是哪里出了问题?
传统的空间智能评测,本质是考“视力”:给AI一张或几张图片,问“A在B左边还是右边”“抽屉里有东西吗”——这些题不需要推理,只要能“看”清画面就行。但人类的空间智能从来不是这样:我们会绕到物体背后、拉开抽屉、翻转容器,通过行动把模糊的信息变清晰。
这就是ESI-Bench的核心突破:它第一次闭合了**感知-行动回路**——一个让智能体通过“观察→行动→新观察→新行动”循环获取信息的机制。你可以把它理解成:以前考试是老师把所有答案线索都印在试卷上,现在是给你一把实验室钥匙,要你自己进去找证据。
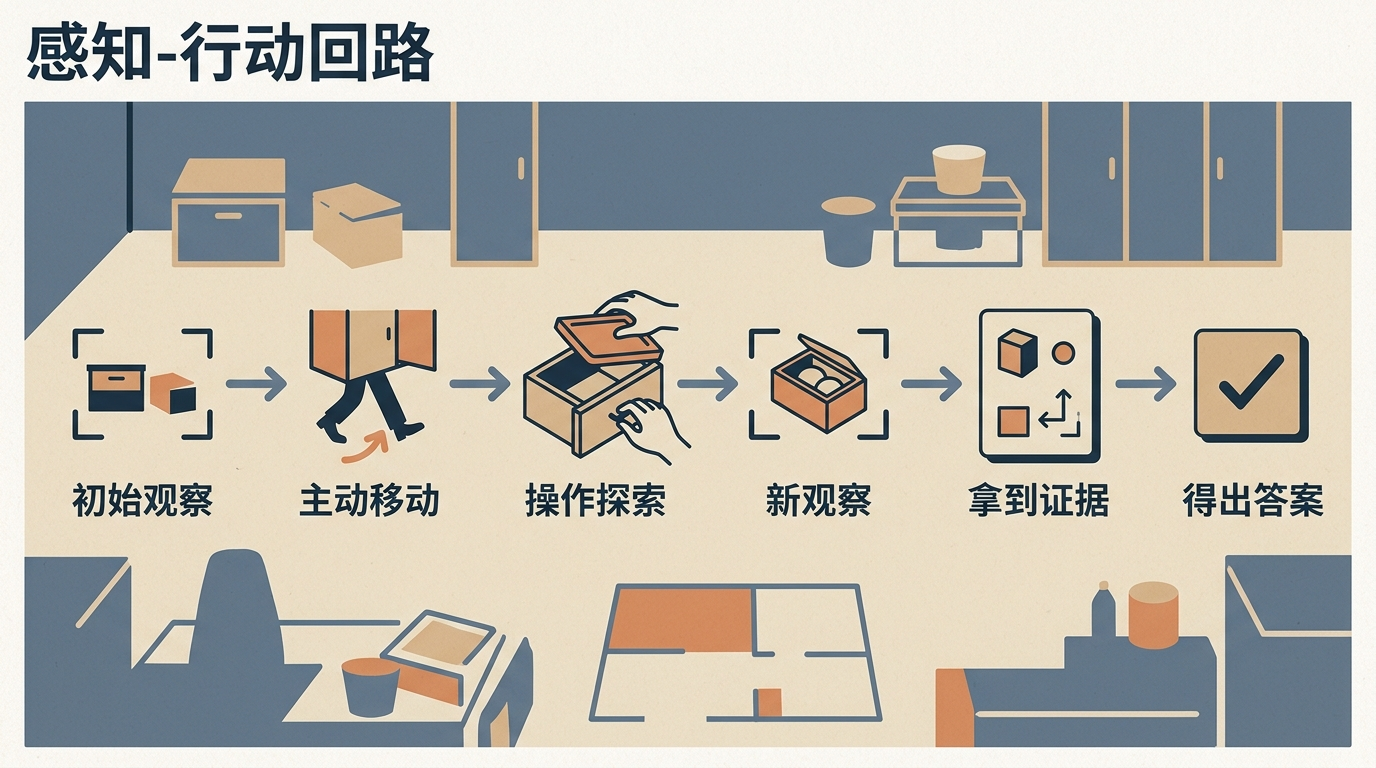
ESI-Bench在OmniGibson仿真平台上搭建了3081个任务,覆盖人类空间认知的四大核心维度:物体识别、空间布局、数量判断和目标导向行动。每个任务都设置了“行动强制”:比如要判断容器能不能装下物体,AI必须主动走近、掀开盖子甚至翻转容器;要比较两个杯子的容量,得把水倒出来试。没有任何捷径,必须“动”才能拿到答案。
测试结果暴露了当前AI的核心缺陷:感知不是瓶颈,行动才是。
团队用GPT-5、Gemini 3.1等顶尖模型做了对比:如果给模型“上帝视角”的最优观测,Gemini 3.1在“部分遮挡”任务上的准确率能从14.6%暴涨到95.1%——这说明AI的“视力”其实没问题,只要给对视角就能看懂。但问题是,AI根本找不到那个“对的视角”。
团队把这种现象命名为动作盲视:AI做出一个错误动作,得到一个无效视角,错误的视角又会引导它做出更错的动作,形成不可逆的级联失败。比如在“结构围合”任务中,AI和“上帝视角”的准确率差距高达49.7%;更讽刺的是,给GPT-5多看几张随机角度的图片,它的准确率反而会从53.9%降到49.1%——信息变多了,判断却更差了。
更关键的是,AI还存在“元认知缺陷”:它不知道自己“不知道”。人类在判断前会主动找能证伪自己假设的视角,比如绕到柜子背面确认,而AI往往看了一两步就自信下结论,哪怕证据还模糊不清。在“材质透明度”任务中,人类主动探索的准确率是93.6%,而Gemini 3.1只有52.3%——差距的核心,是AI没有“怀疑自己”的能力。
有人可能会想:既然2D看图有局限,那用3D重建场景不就行了?但ESI-Bench的测试打破了这个幻想。
如果给AI完美的3D真值场景,确实能提升部分任务的表现——比如Gemini在“材质透明”任务上,2D版本得分44.0%,3D版本能涨到60.4%。但如果是真实世界中不完美的3D重建,结果会更糟:用当前最先进的VGGT模型重建场景后,AI在“几何配置”任务上的得分从2D基线的27.5%暴跌到9.9%。

这是因为不完美的3D重建会引入“有毒信息”:几何伪影、遮挡补全错误、深度偏差……这些失真的信息会误导AI的推理,反而不如2D图片“虽然信息少,但至少不失真”。这也给当前的具身智能研究提了个醒:盲目追求3D化没用,先把“怎么找对视角”的问题解决,比什么都重要。
ESI-BENCH的出现,就像给AI出了一份“实景操作题”,而不是“选择题”。它让我们看清:当前AI的“聪明”,大多是在静态数据里训练出来的“纸上谈兵”,而真正的智能,是能在复杂的真实世界里,主动找答案的能力。
智能的本质,从来不是“看得懂”,而是“会行动”。从被动感知到主动探索,这不仅是评测范式的转变,更是AI从“工具”向“智能体”进化的必经之路。或许未来的某一天,AI会像人类一样,在遇到问题时先停下来想一想:“我该做点什么,才能找到答案?”