对抗知识焦虑,从看懂这条开始
App 下载
700万参数模型干翻40亿,AI推理换赛道了
推理能力|700万参数模型|ARC-AGI基准|多伦多大学|华为|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理能力|700万参数模型|ARC-AGI基准|多伦多大学|华为|大语言模型|人工智能
你可能默认AI模型是“越大越聪明”——要解决复杂推理,就得堆到千亿参数、烧几百万美元训练。但2026年4月,华为和多伦多大学的团队把这个常识砸得稀碎:他们用一个只有700万参数的小模型,在号称“AI智商测试”的ARC-AGI基准上,直接超过了40亿参数的大模型。这不是小打小闹的优化,而是换了一种让AI“思考”的方式。问题是,它怎么做到的?
先得搞懂之前的AI推理为啥卡壳。过去有两条路,都走不通。 一条是扩散模型的“短视路线”:就像让学生做“正确答案被涂掉一部分,复原就行”的练习题,训练时给正确答案加随机噪声,让模型学“去噪”。这种方法稳,能从易到难循序渐进,但到了考试就傻了——考的是“给你一个错误解题过程,让你纠错”,和训练时的“涂掉复原”完全是两码事,这就是“训练-测试不匹配”,模型根本不会真推理,只会做单步去噪。 另一条是递归模型的“冒险路线”:从纯噪声开始,让模型一步步迭代修正答案,像在荒原里摸黑找宝藏。这种方法能学长远规划,但太不稳定了——迭代几百步后,梯度要么消失要么爆炸,模型很容易走偏,训练到崩溃是常事。 两条路都有死穴,直到DRM把它们拧在了一起。
DRM的核心逻辑说穿了就是“偷懒找对地方”——前向一步,后向K步。 你可以把它想象成爬山:以前的递归模型是从山脚直接往上爬,容易迷路摔下山;扩散模型是在山顶附近找路,却不知道怎么下山再上山。DRM则是先坐缆车到半山腰(前向一步:从正确答案加噪声,生成一个“半对”的中间状态),然后从这里开始,一步步摸索着往上爬(后向K步:用4步递归迭代,把半对的状态修正成完全正确的答案)。 关键是,这4步迭代的整个链条,会一起计算梯度反向传播。模型不再只看眼下的一步,而是要考虑“我现在走的这一步,会不会让后面三步更容易”——这就逼出了它的“隐式规划能力”。同时,训练时的迭代过程和测试时完全一致,再也不会出现“练的是一套,考的是另一套”的尴尬。
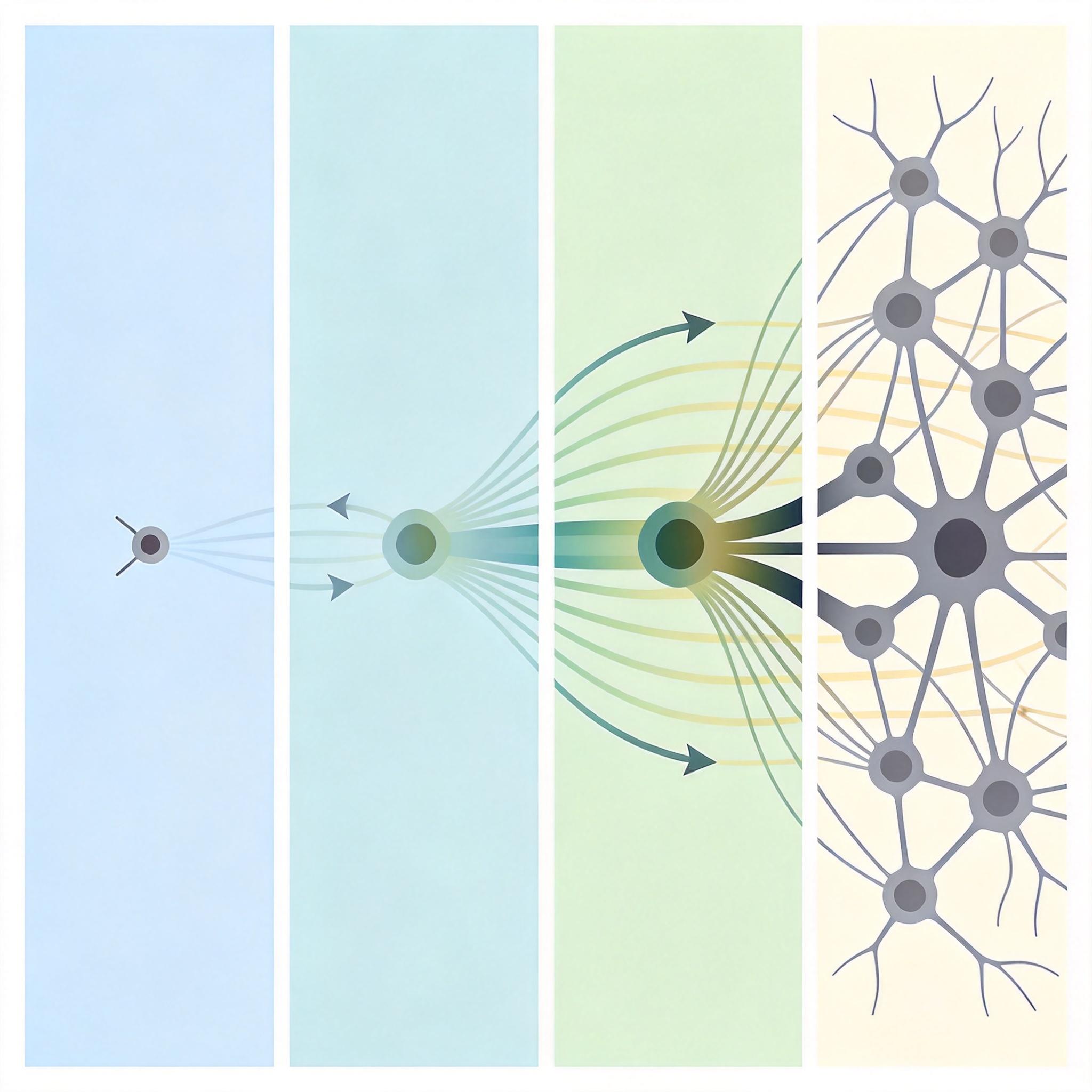
直给的技术逻辑是:先采样一个噪声等级,把正确答案“污染”成半对状态,再让模型用4步递归把它修正回来,全程用固定窗口的梯度回传避免崩溃。就这么简单的改动,700万参数的模型直接干翻了40亿参数的对手。
当然,DRM也有它的局限。它必须依赖递归结构,没法直接用到普通Transformer上;而且现在的噪声设计只适合ARC这种网格推理任务,换成文本、音频这类数据,还得重新摸索怎么加噪声;推理时要走4步迭代,比单步模型慢,不适合极端实时的场景。 但更值得关注的是,它打破了“堆参数=高性能”的路径依赖。过去几年,AI圈陷入了一种“军备竞赛”:你做千亿参数,我就做万亿,算力成本翻着跟头涨,却没多少人想过换一种训练逻辑。DRM用700万参数的结果证明,真正的突破不在堆多少参数,而在怎么让参数更聪明地工作。 它的实验数据更狠:训练集准确率到了99%以上,验证集性能还在涨——这说明它学的不是死记硬背的答案,而是通用的推理规则,抗过拟合能力强得离谱。
当大家都在往“更大的模型”这条路上挤的时候,DRM拐进了一条“更聪明的训练”的小路。它不是要取代大模型,而是给了AI推理另一种可能——在边缘设备、嵌入式系统、低成本场景里,小模型也能做出高质量的推理。 这背后其实是AI发展的一个转向:从“追求规模”回到“追求效率”。毕竟,真正能改变世界的AI,不是只有少数大厂能玩得起的巨无霸,而是普通人也能用、随处都能跑的“轻量级智能”。 小模型的胜利,是效率的胜利。