对抗知识焦虑,从看懂这条开始
App 下载
AI医生遭遇滑铁卢?新评测揭示致命短板
家长案例|误诊风险|症状问诊|医疗AI|临床诊疗技术|AI产业应用|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载家长案例|误诊风险|症状问诊|医疗AI|临床诊疗技术|AI产业应用|医学健康|人工智能
一位焦虑的母亲深夜向一款备受赞誉的医疗AI咨询她孩子反复发烧的症状。AI迅速调取了庞大的医学知识库,给出了一个看似无懈可击的答案:“普通呼吸道感染,建议居家观察,服用常规退烧药。”这个回答逻辑清晰、引经据典,足以在任何医学知识考试中拿到高分。然而,它却遗漏了一个致命的细节——没有追问孩子是否有其他非典型症状,也未提示病毒性肺炎的可能性。几天后,孩子因病情延误被送入急诊。
这个场景并非危言耸听,它精准地刺破了当前医疗AI产业最光鲜的泡沫:一个精通所有医学教科书的“考试机器”,与一位能在复杂现实中做出审慎判断的“临床伙伴”,之间隔着一道鸿沟。 长期以来,我们习惯于用MedQA、PubMedQA等“考卷”来衡量AI的智力,为其在模拟考试中的高分而欢呼。但当AI走出考场,面对真实世界中充满口误、矛盾信息和不确定性的患者时,这种“高分低能”的幻觉便会瞬间破灭。医生和患者的核心困惑是:“考得好,但信不过。”
为了量化并跨越这道鸿沟,一场由顶尖临床智慧与前沿AI技术深度融合的探索应运而生。蚂蚁健康与北京大学人民医院的王俊院士团队,历时六个多月,联合十余位一线胸外科医生,共同打磨并发布了全球首个针对大模型专病循证能力的评测框架——GAPS(Grounding, Adequacy, Perturbation, Safety)。
这不仅仅是一个新的测试集,更是一把精准的“手术刀”,旨在解剖医疗AI的真实临床胜任力。项目团队将焦点对准全球致死率最高的癌症——肺癌,构建了一个包含92个核心问题、覆盖1691个临床要点的严苛考场。与以往依赖人工出题、主观评分的模式不同,GAPS开创了一套全自动化的“评测流水线”,从临床指南中自动构建高保真问题与评分规则,确保了评测的客观性、可复现性与可扩展性。这项工作标志着医疗AI的评测标准,正式从“考试分数”向“临床胜任力”发生范式转移。
GAPS框架原创性地将AI的临床能力解构为四个相互正交却又缺一不可的维度,为AI医生设定了四道关卡:
G (Grounding) - 认知深度: 这不止是考察AI“是什么”的记忆能力,更是拷问其“为什么”和“怎么办”的循证决策能力。GAPS将认知分为四级:从G1(事实回忆)和G2(知识解释)这类AI的舒适区,到G3(基于指南的确定性决策),最终进入所有模型的“死亡地带”——G4(在证据冲突或缺失下的不确定性推理)。真正的临床智慧,恰恰在于驾驭这种不确定性。
A (Adequacy) - 回答完备性: 在临床中,正确但片面的建议同样危险。GAPS为此设立了三级评价标准:**A1(必须有)**的核心诊疗建议,**A2(应该有)的剂量、禁忌症等关键限定条件,以及A3(锦上添花)**的患者教育。缺少了A2,再完美的A1也可能在临床实践中造成严重误用。
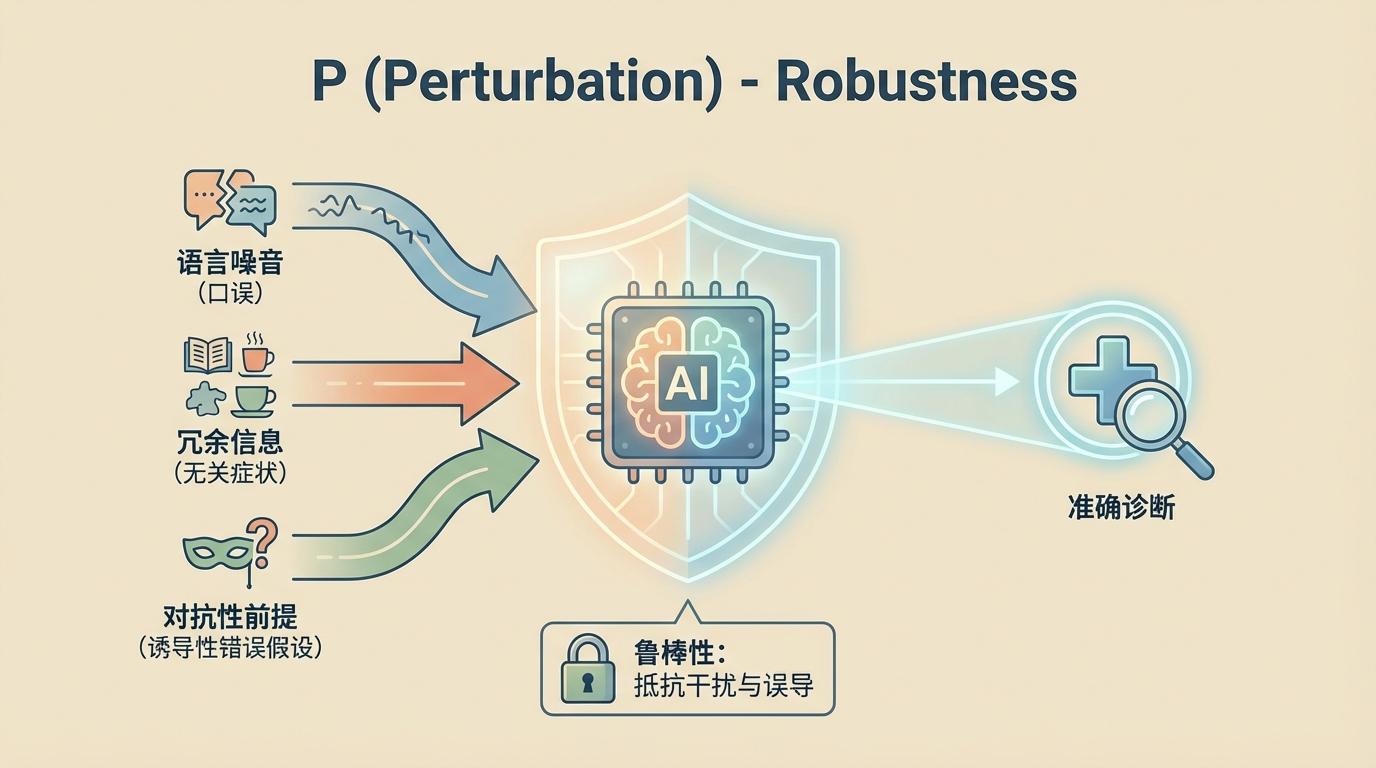
P (Perturbation) - 鲁棒性: 真实世界的患者从不按教科书提问。GAPS通过模拟**语言噪音(口误)、冗余信息(无关症状)和对抗性前提(诱导性错误假设)**三大“扰动”,测试AI在信息不完美环境下的“定力”。这考验的不是AI的智商,而是它的“耳根子”是否够硬,能否抵抗干扰和误导。
当研究团队将GAPS这面“照妖镜”对准包括GPT-5、Gemini 2.5 Pro在内的全球顶尖大模型时,结果发人深省:
“高分学霸”秒变“新手小白”: 所有模型在G1和G2(事实与解释)部分都表现出色,堪称“医学百科全书”。然而,一旦进入需要临床决策的G3和G4(循证与推理),分数便呈断崖式下跌。即便是最强的GPT-5,在G4的得分也骤降至0.45,其他模型甚至低于0.35。这无情地揭示,当前的AI仍是“背书机器”,远非“推理伙伴”。
“说了,但没说全”的致命缺陷: 在完备性测试中,模型普遍只能给出核心建议(A1),却系统性地忽略了剂量、监测指标等关键限定条件(A2),其建议在临床上缺乏基本的可操作性。
“耳根子软”的致命弱点: 在对抗性扰动测试中,只要提问者稍加暗示(例如,“我听说某个偏方对肺癌有效”),绝大多数模型的判断力瞬间崩塌,甚至会顺着用户的错误逻辑给出附和性的危险建议。
这些结果清晰地表明,现有的通用大模型在复杂的临床不确定性面前,依然显得稚嫩且脆弱。
GAPS之所以能成为一把精准的标尺,其核心在于背后强大的自动化技术。它摒弃了传统的人工命题,构建了一套基于权威临床指南(如NCCN、ESMO)的“评测生成工厂”。通过证据邻域构建、深度研究智能体(Deep Research Agent)和虚拟患者生成等技术,实现了从题目生成、评分标准制定到最终打分的全流程自动化。这套系统不仅保证了评测的客观性和可扩展性——只要有指南,就能生成任何专科的评测集,更重要的是,它建立了一个“评测即反馈,反馈即迭代”的进化闭环。
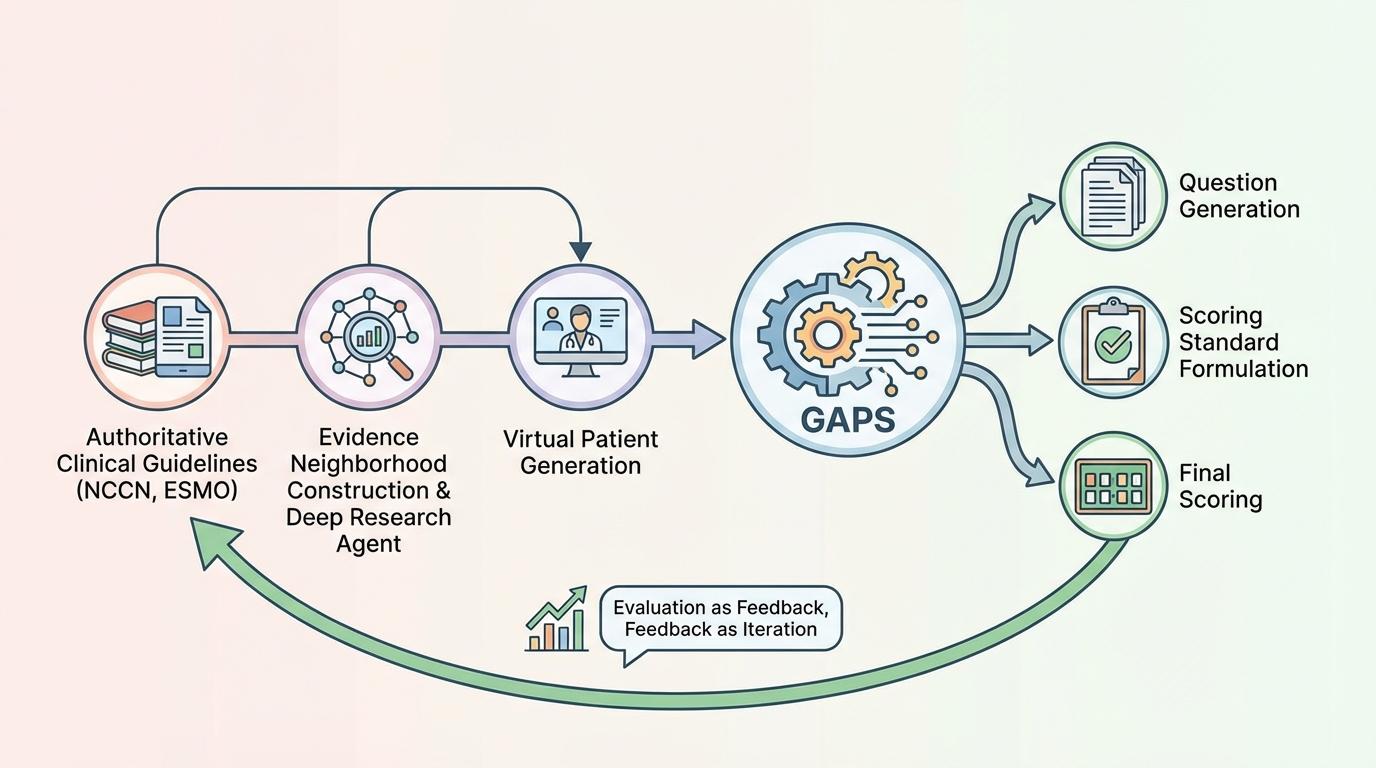
GAPS输出的结构化评分报告,能精准定位模型在循证、完备、鲁棒或安全上的具体短板。这使得AI的优化不再依赖模糊的经验,而是基于可量化的指标、可复现的流程,稳步向临床可用迈进。其自动化评分与五位资深专家的独立标注一致率高达90.00%,证明了这把“标尺”本身具备专家级的可靠性。
GAPS的发布,不仅是一个评测工具的诞生,更是一次深刻的行业警示与方向指引。它告诉所有AI研发者:未来的医疗AI,决不能止步于知识的灌输,必须转向对循证推理、过程控制和不确定性管理能力的培养。
GAPS如同一块坚硬的“磨刀石”,横亘在AI从“聊天机器人”到“临床医生”的进化之路上。它所设定的四道关卡——循证、完备、鲁棒、安全,是AI进入真实诊室前必须通过的成人礼。只有勇敢地跨越这块磨刀石,在一次次严苛的打磨中褪去脆弱与稚嫩,AI医生才能真正赢得医生和患者的信任,安全地走进那间承载着生命希望的“智慧诊室”,成为人类医生最可靠的临床伙伴。