对抗知识焦虑,从看懂这条开始
App 下载
病理数据拖垮AI诊断?这个方法给数据“打假”
设备差异|多中心影像数据|阿尔茨海默病|扩散磁共振成像|ComBat标准化方法|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载设备差异|多中心影像数据|阿尔茨海默病|扩散磁共振成像|ComBat标准化方法|大语言模型|临床诊疗技术|医学健康|人工智能
想象一下:你召集20家医院,收集了上万份脑部扫描数据,训练出一个号称能早期诊断阿尔茨海默病的AI。结果上线后发现,它判断病情的依据不是患者的脑部病变,而是“这个患者用的是A品牌扫描仪,那个用的是B品牌”——就像用体温计品牌判断谁发烧,完全南辕北辙。为了抹平不同设备的差异,科学家发明了ComBat标准化方法,曾是多中心影像研究的“明星工具”。但加拿大舍布鲁克大学的团队最近发现,这个明星在真实临床数据面前,居然有个一碰就碎的“阿喀琉斯之踵”。
我们先搞懂核心问题:扩散磁共振成像(dMRI)能通过水分子扩散情况,推断大脑神经纤维的完整性,是阿尔茨海默病、脑损伤等疾病的重要诊断依据。理想状态下,不同医院测出的同一个健康人的dMRI指标应该一致,但扫描仪型号、参数甚至软件版本,都会给数据打上“设备烙印”——这就是需要ComBat解决的“站点效应”。
ComBat的核心逻辑是:假设每个站点的数据都服从以健康人群为中心的高斯分布,通过经验贝叶斯方法,把每个站点的数据“拉回”统一的标准分布。但这个假设在真实临床场景里不堪一击:医院扫描的大多是病人,这些患者的dMRI指标会因为病变系统性偏离健康值——比如阿尔茨海默病患者的自由水指标比健康人高1个标准差以上,脑损伤患者的轴向纤维密度低1.3个标准差。
在ComBat眼里,这些因病变产生的偏移,和因设备产生的偏移长得一模一样。当它计算“平均偏移量”来校正数据时,病理数据会严重扭曲计算结果:健康人的数据被错误“矫枉过正”,患者的病变信号反而被“抹平”。就像把正常人和病人一起摁向中间,最后谁的真实状态都没保住。
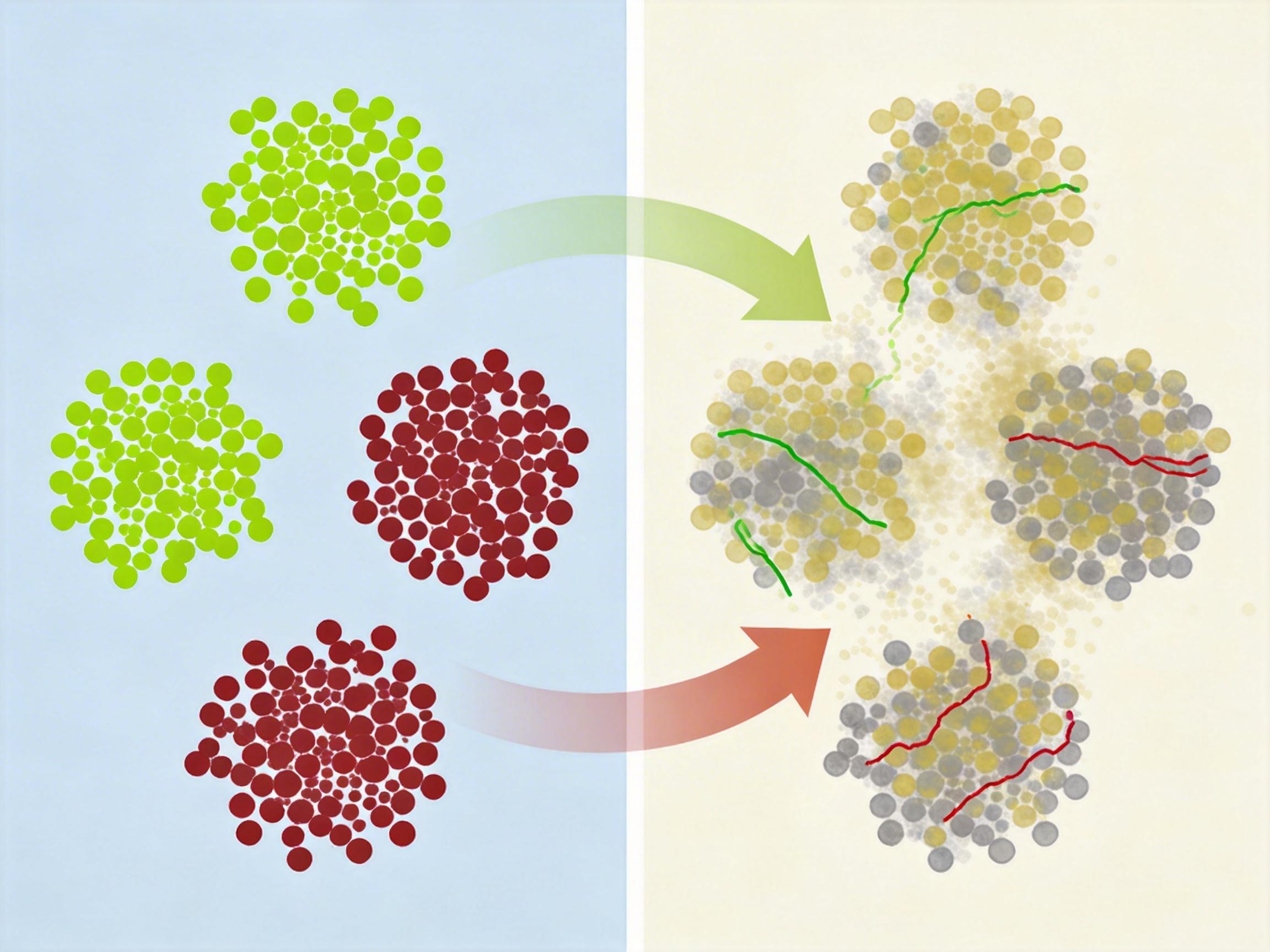
既然问题出在病理数据干扰了校正计算,那解决思路似乎很简单:先把病理离群值找出来过滤掉,再用干净的健康数据做标准化。但难点在于,脑部疾病的影响往往是“广泛而轻微”的——单个指标的偏移可能不显著,但多个脑区、多个指标的偏移组合起来,才是病变的信号。传统的单维度统计方法,比如Z-score、四分位距,根本抓不住这种复杂的异常模式。
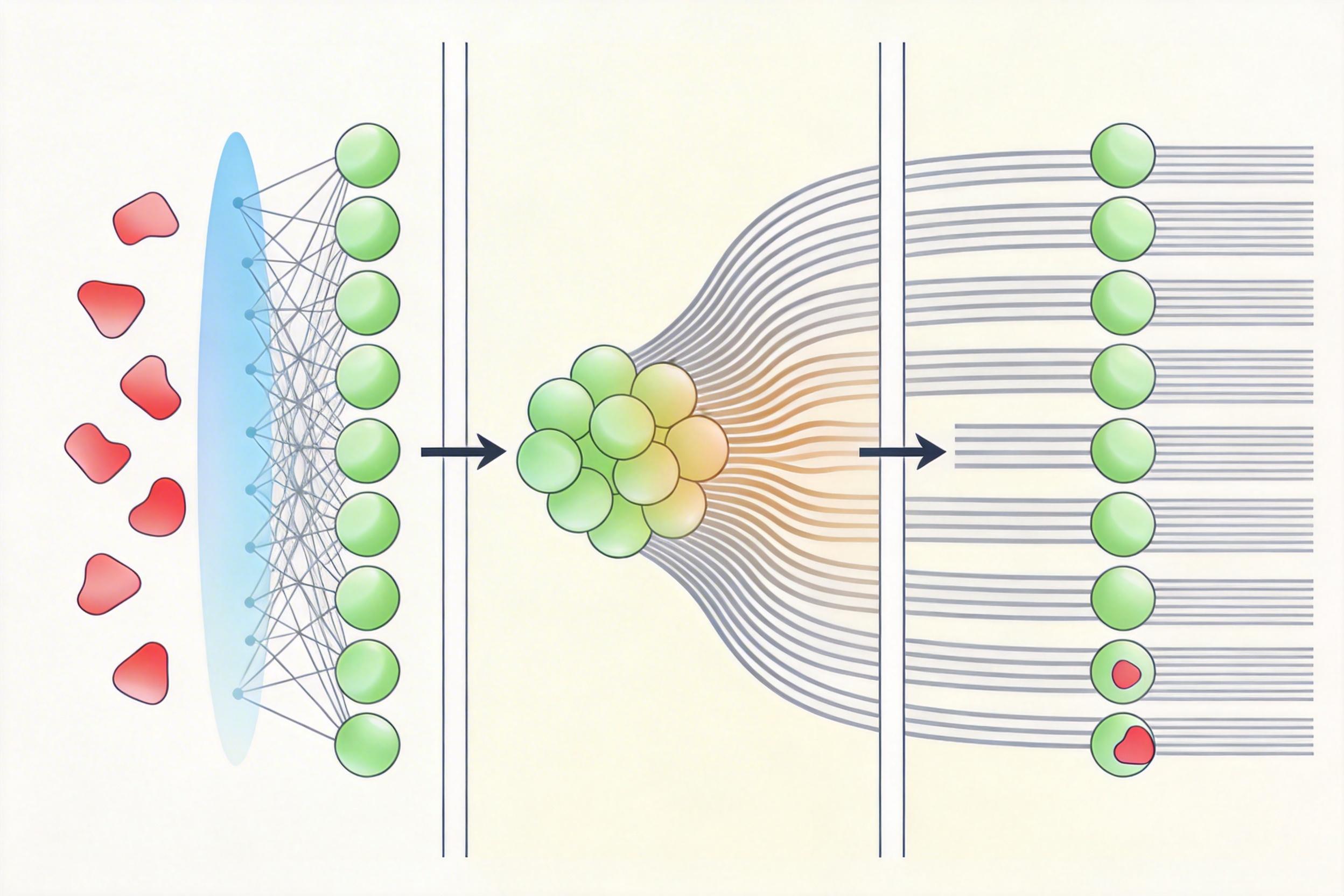
舍布鲁克大学的团队给出的方案是:用一个简单的多层感知机(MLP)做“数据打假人”。这个MLP输入一个人的430维特征(43个脑束×10个dMRI指标),输出他是不是病理离群值的概率。它不需要预先知道病变的方向,能自动从数据里学习病理异常的复杂模式。
Robust-ComBat的流程很清晰:第一步用MLP过滤掉病理离群值,得到干净的健康数据子集;第二步用这个子集估计站点效应,做ComBat标准化;第三步把校正参数应用到全体数据上——这样既保证健康人的数据被准确对齐,又保留了患者真实的病变偏移。
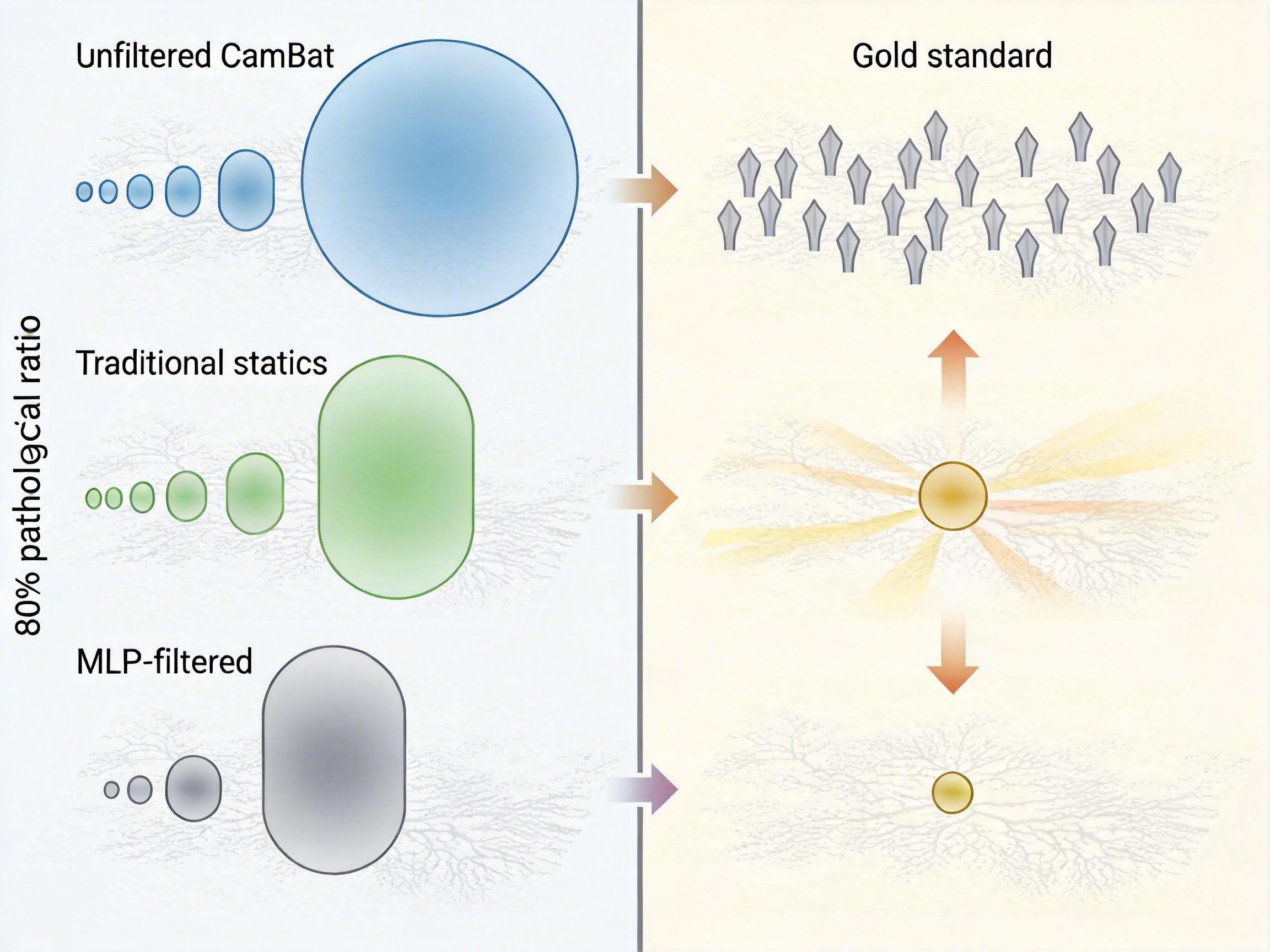
为了验证效果,团队做了一次“华山论剑”:测试了10种离群值过滤方法,搭配4种ComBat变体,在病理患者比例从3%到80%的场景下逐一验证。结果让人意外:那个结构最简单的MLP,成了全场冠军。
当病理患者比例达到80%时,不做过滤的ComBat标准化误差几乎是只用健康人时的两倍;传统统计方法要么过滤不彻底,要么误删健康数据,性能急剧下降;而MLP过滤后的结果,误差始终最接近“只用健康人”的黄金标准,甚至在80%的极端场景下,表现依然稳定。
更重要的是,这个方法的兼容性极强——无论是CovBat、ComBat-GAM还是Pairwise-ComBat,只要前置MLP过滤,性能都能显著提升。不过它也有局限:MLP的训练需要大量已标准化的高质量健康数据,对于样本量小的研究,只能退而求其次用均值-中位数偏移法等统计方法。
Robust-ComBat的厉害之处,不在于发明了多么花哨的新模型,而在于它精准戳中了一个被忽视的行业痛点:我们总用理想化的模型假设,去处理充满“意外”的真实世界数据。医学AI的瓶颈,很多时候不是模型不够聪明,而是数据里藏着太多“暗雷”——设备差异、病理干扰、样本不均,每一个都能让看似完美的模型在临床中失效。
更值得关注的是,这个方法的思路可以推广到所有多中心数据研究:从基因组学到蛋白质组学,从影像学到临床检验,只要数据里混着真实的“异常信号”,就需要先把这些信号和技术噪声分开。让数据“说真话”,才是医学AI真正能落地的前提。数据的干净,比模型的聪明更重要。