对抗知识焦虑,从看懂这条开始
App 下载
AI视频编码新逻辑:给机器的眼睛精准节流
自动驾驶识别系统|JRD阈值|视频压缩方案|机器视觉|中山大学团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动驾驶识别系统|JRD阈值|视频压缩方案|机器视觉|中山大学团队|多模态视觉|人工智能
当你用手机刷视频时,算法会优先保证人脸清晰、背景模糊——这是给人眼的“定制压缩”。但如果看视频的是自动驾驶的AI、监控摄像头的识别系统,这套逻辑就完全失效了:AI不需要看清天空的云彩,却要死死盯住行人的脚踝、车辆的转向灯。
2026年4月,中山大学团队拿出了一套专门给AI“省流量”的方案:他们测出了机器视觉的“底线”,能在保证AI精准识别的前提下,把视频码率压缩到让人眼无法忍受的程度——这相当于给AI的眼睛装了个智能节流阀。
要给AI节流,首先得搞懂AI对图像的“容忍度”——这就是JRD(可识别差异阈值),指AI刚好能完成任务的图像失真极限。就像人眼能接受轻度模糊的照片,但AI不行:不同任务对图像细节的依赖天差地别。
团队用最新的VVC编码标准,把COCO数据集里的图片压缩成64种质量梯度,再用高精度AI模型逐一测试:目标检测只需要框出物体,哪怕压缩到QP=43(图像严重模糊),AI还能认出这是个人;但关键点检测要定位关节,QP到40就会把脚踝当成膝盖;实例分割要描出轮廓,容忍度介于两者之间。
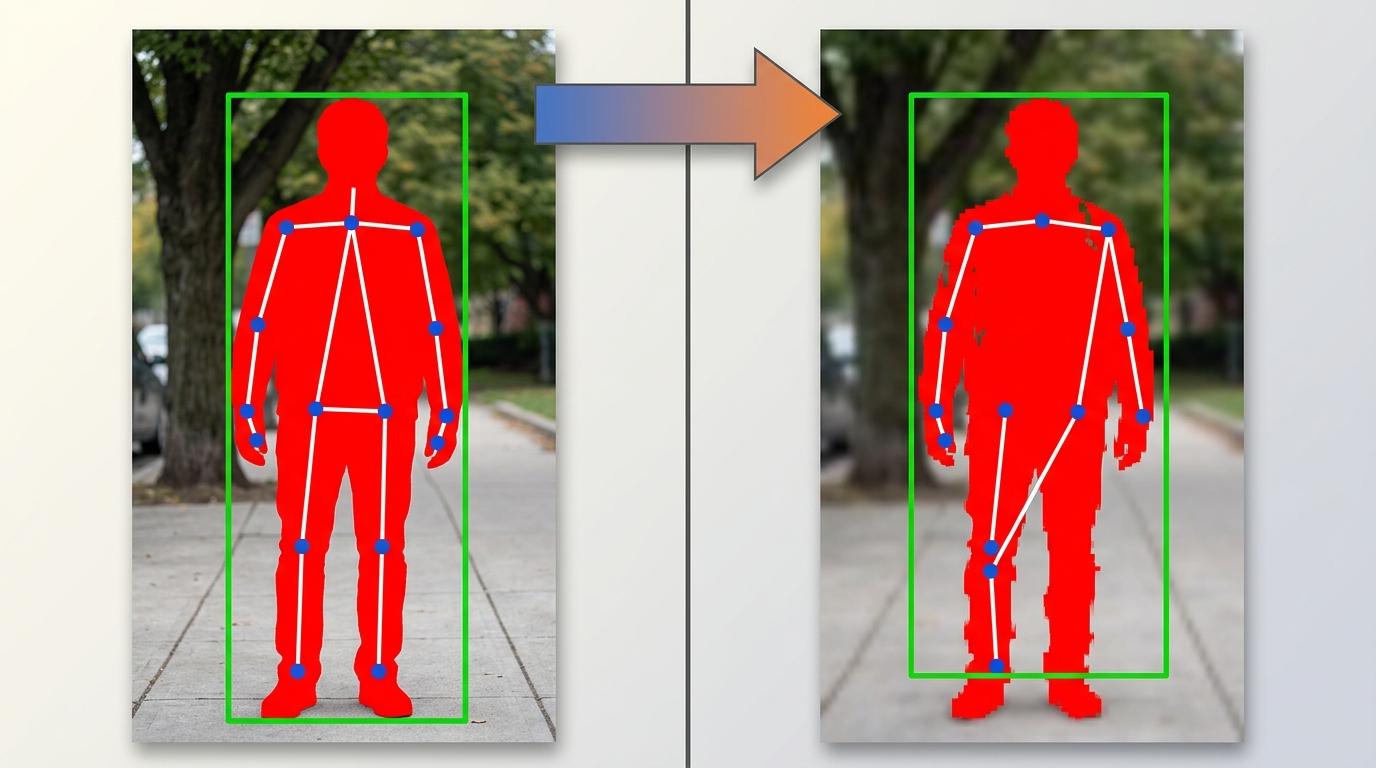
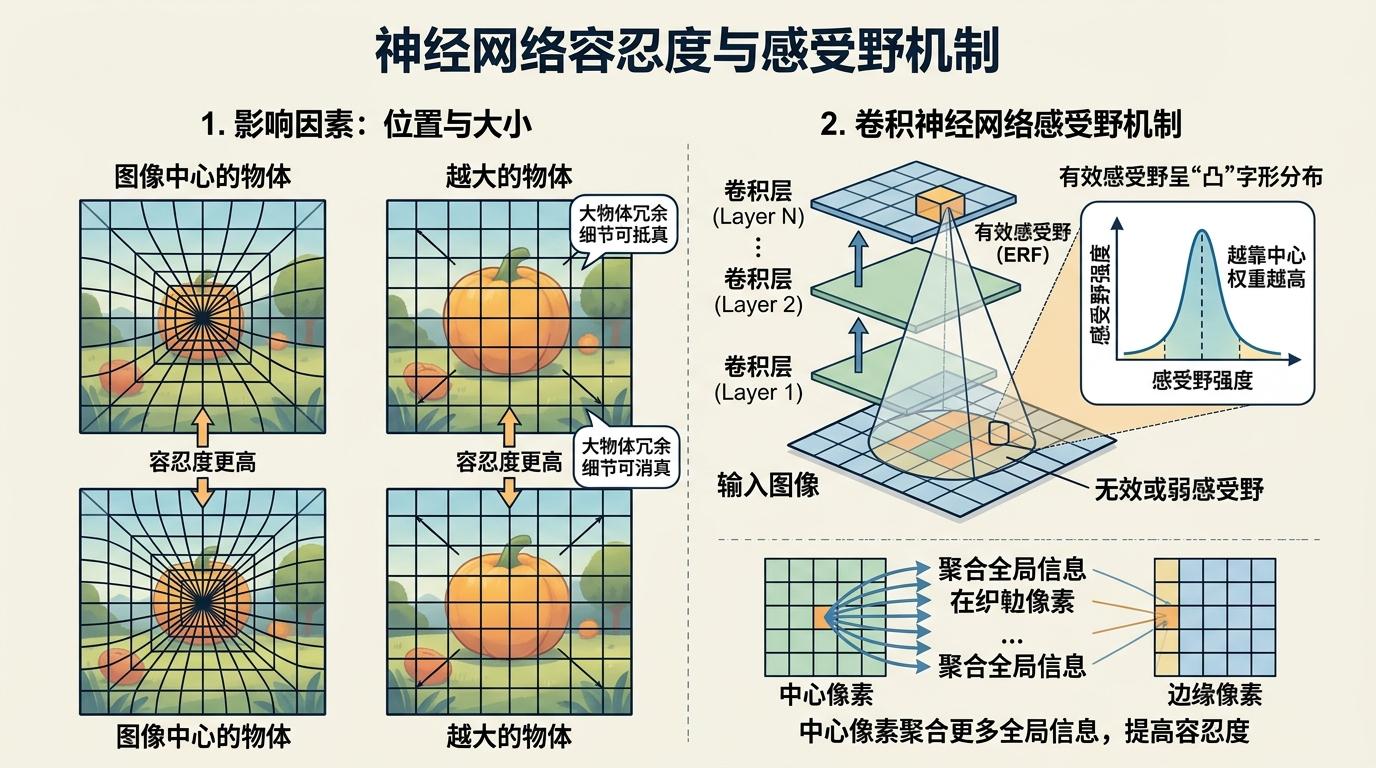
他们还发现了两个有趣的规律:图像中心的物体、越大的物体,AI的容忍度越高——这和卷积神经网络的“有效感受野”机制有关,中心区域的像素能聚合更多全局信息,大物体的冗余细节也能抵消部分失真。
传统的单任务JRD模型需要分别训练三个网络,计算量巨大,还没法共享任务间的信息。中山大学团队设计的AMT-JRD模型,用“公共课+专业课”的思路解决了这个问题:
最终,这个模型能只看一张原图,同时预测出三个任务的JRD值,比单任务模型效率提升了一倍多。
有了JRD数据库和预测模型,就能给视频编码“精准开刀”了。团队提出的VCM(面向机器的视频编码)方案,核心就是“好钢用在刀刃上”:
实验结果让人惊喜:相比标准VVC编码,基于AMT-JRD的方案平均提升了3.861%的BD-mAP(码率相同的情况下,AI识别精度更高);相比JPEG编码,提升更是高达7.886%——也就是说,在保证AI识别精度不变的前提下,能省掉近8%的带宽。
当然,这套方案也有局限:它依赖前置目标检测的准确性,如果目标框本身因为压缩而模糊,JRD预测就会出错;而且目前只针对静态图像,视频中的运动模糊、时间冗余还没解决。
从为人类的眼睛编码,到为机器的算法编码,这不仅仅是技术的迭代,更是对“视频价值”的重新定义——视频不再是给人看的画面,而是给AI用的数据流。
未来,当自动驾驶的摄像头把视频传给云端,当监控系统分析海量画面,这套“精准节流”的逻辑会让每一分带宽都用在刀刃上。给机器的眼睛编码,本质是给AI的效率铺路。而我们要做的,就是在机器的“视觉底线”之上,找到技术与效率的最优解。