
12 天前
12 天前
想象你对着AI说:“帮我把这段代码改写成适配最新系统的版本,顺便参考这个设计图的交互逻辑,再结合昨天我们聊的用户反馈”——不用切换三个工具,不用重复上下文,AI能一次性接住所有信息。这不是科幻场景,而是OpenAI内部正在冲刺的目标。他们砍掉了包括视频生成工具在内的非核心项目,把所有资源砸向代号“Spud”的GPT-6,内部将其定义为AGI的“最后一公里”。为什么一款模型值得如此孤注一掷?答案藏在两个关键突破里。
你可以把传统多模态AI理解成“组装电脑”——文本、图像、音频各有独立的“配件”,最后用连接线拼在一起。这种模式下,AI处理信息时总隔着一层,比如看图片时只能先转成文本描述,再交给语言模型理解,难免丢信息、慢半拍。 GPT-6的原生多模态架构更像“人脑”:所有模态信息从输入开始就被转换成统一的“神经信号”(token),塞进同一个Transformer模型里。视觉的像素、音频的波形、文本的词汇,在模型内部直接对话,不需要额外的翻译环节。就像你看电影时,画面、台词、背景音乐是同时钻进脑子里,自然融合成完整感受的。 但真实的机制比这更精确:它用向量量化技术把图像拆成离散的视觉token,用神经编解码器把音频分成语义和声学两层token,再和文本token排成一串,让模型的注意力机制自由捕捉跨模态的关联。比如看到一张咖啡拉花图,它能同时“看见”奶泡的纹理、“读懂”拉花的图案含义,甚至“联想到”咖啡的香气——这是拼接式模型做不到的深度融合。
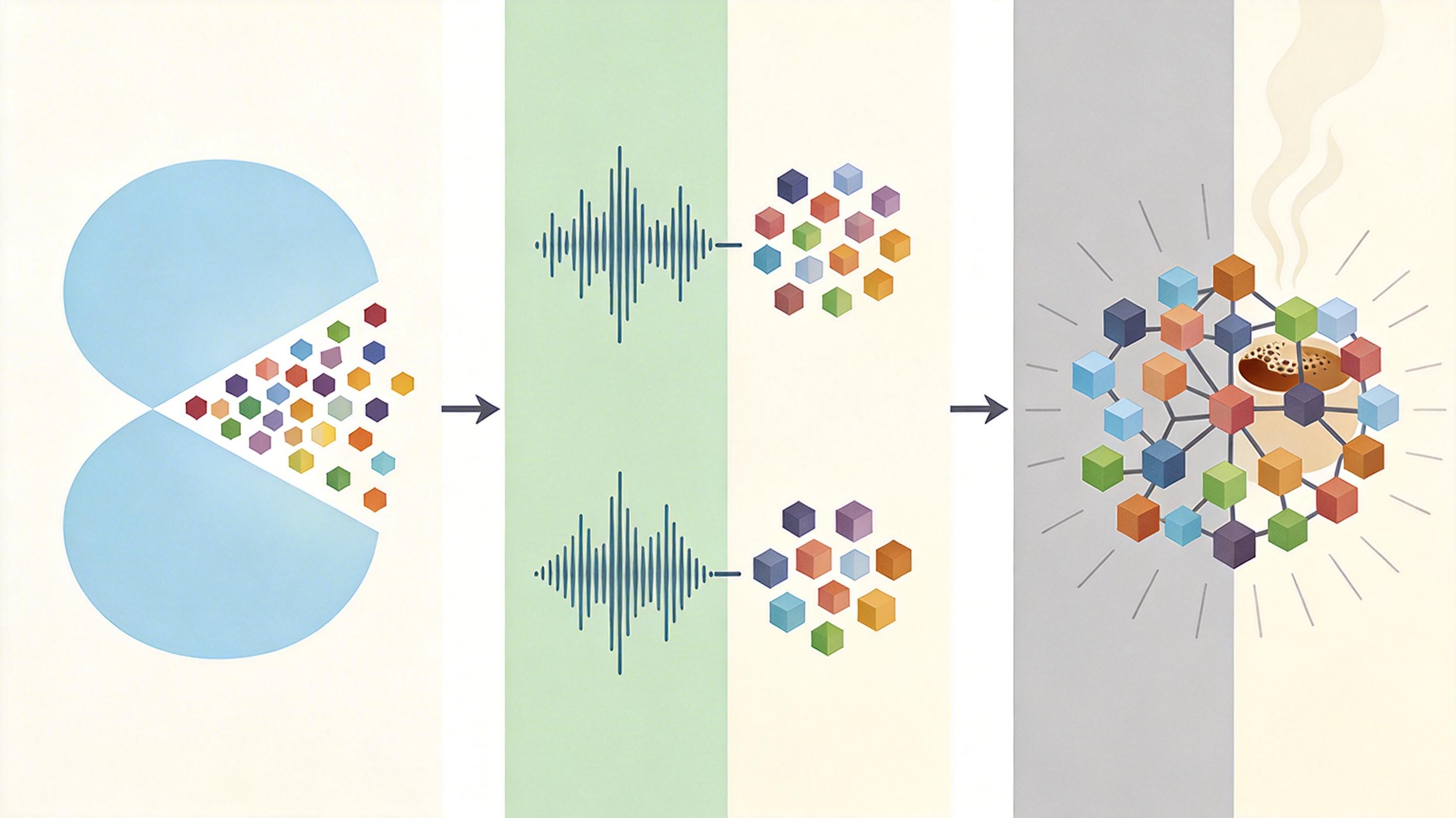
这种设计带来的直接效果是,在代码、推理、智能体任务上,GPT-6比前代性能暴涨40%。它不再是只会单一技能的工具,而是能同时处理多种信息的“通用感知器”。
如果说原生多模态是给AI配齐了所有感官,那200万Token的超大上下文窗口,就是给它装了个大容量硬盘。 传统大模型的上下文窗口像个小记事本——GPT-4只能记住约8000个词,大概是一篇短篇故事的长度。你要是让它处理一本10万字的书,它只能分段读,读了后半段就忘了前半段;让它分析一整部电影的字幕,更是得切成几十段,根本没法理解完整的剧情逻辑。
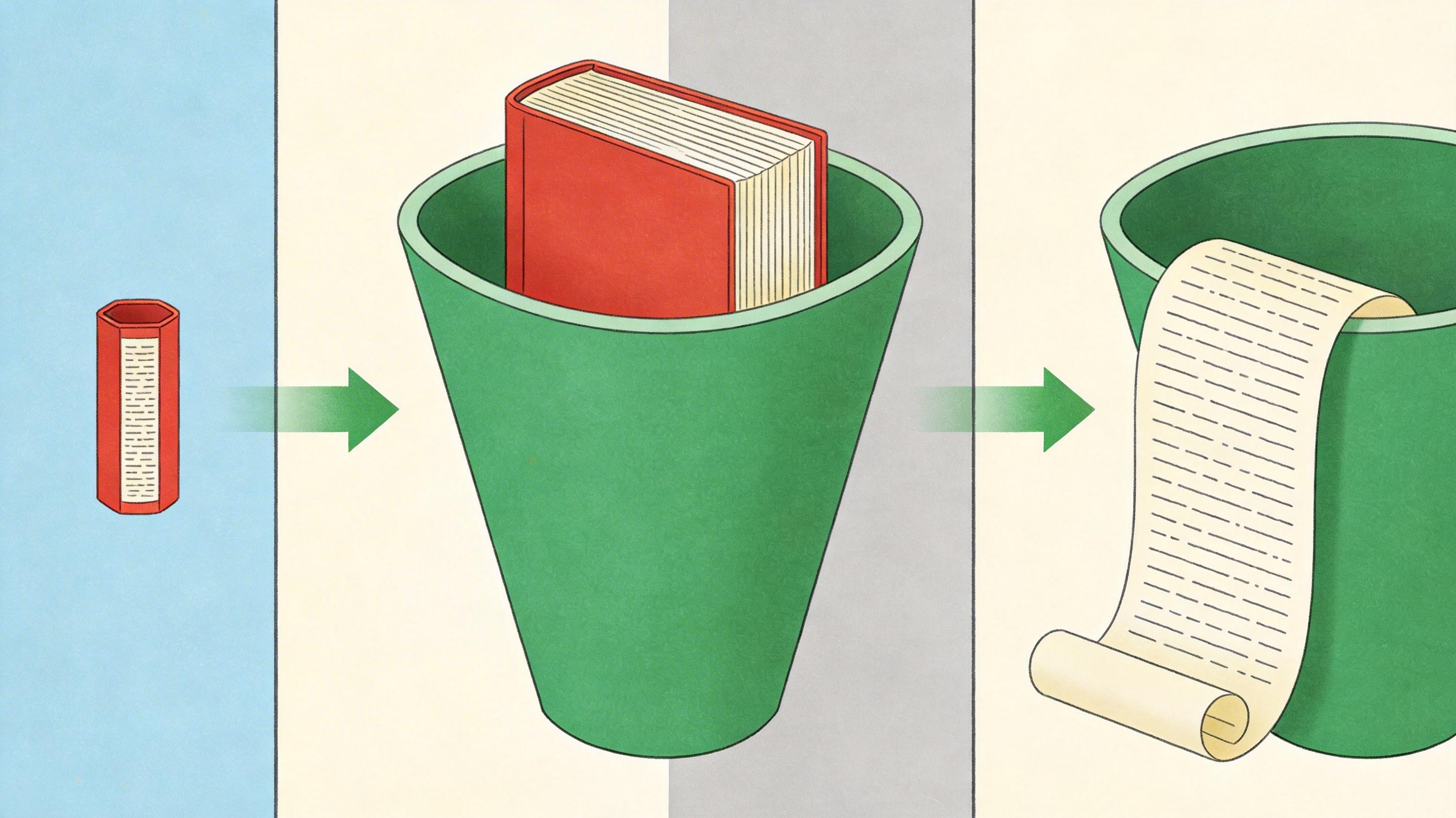
200万Token是什么概念?大概是150万字,相当于一整套《哈利波特》的文本量,或者一部3小时电影的完整字幕加画面描述。GPT-6能一次性“读”完这些内容,并且记住里面的所有细节——比如你可以让它对比《哈利波特》全系列里邓布利多的性格变化,或者从一部电影里找出前后呼应的伏笔。 这背后的关键技术是旋转位置编码(RoPE)的改进版。你可以把它理解成给每个Token贴了个带坐标的标签,不管序列多长,模型都能通过坐标计算出Token之间的相对位置,不会因为内容太长就“迷路”。而且它用了稀疏注意力机制,只重点关注相关的Token,不用把所有信息都算一遍,既省算力又保证了效率。 更重要的是,这种“长期记忆”让AI能胜任复杂的长任务:比如一次性重构整个代码库的逻辑,或者全程跟踪一个持续数天的项目对话,不用反复交代背景。这是从“对话工具”转向“智能助理”的核心一步。
OpenAI的孤注一掷,本质上是一场算力的豪赌。为了训练GPT-6,他们动用了超过10万台NVIDIA H100和GB200加速器,单训练集群的功耗就相当于一个中型城市的电力需求。砍掉Sora等项目,就是为了把算力集中在最核心的突破上。

但这种集中也暗藏风险。原生多模态带来的“模态不平衡”问题还没完全解决——文本数据的语义密度远高于图像和音频,模型可能会不自觉地依赖文本,弱化视觉和音频的理解能力。就像一个人听别人描述风景,总不如自己亲眼所见那么准确。 超大上下文窗口也带来了新的安全挑战:更长的输入意味着更多被攻击的可能,比如恶意用户可以在长文本里藏“越狱”指令,绕过模型的安全防护。而且处理200万Token的计算成本是巨大的,目前的定价虽然只比前代略高,但长期来看,如何平衡性能和成本,是商业化必须解决的问题。 更值得注意的是,OpenAI把安全团队划归到首席风险官旗下,暂时放缓了安全研发的节奏。这种“先突破再补安全”的策略,无疑是在走钢丝——AGI的“最后一公里”,也是风险最集中的一公里。
当GPT-6把文本、图像、音频、视频揉进同一个模型,当它能记住一整套《哈利波特》的细节,它已经不是在模仿人类的某一项技能,而是在逼近人类认知世界的方式——用多感官接收信息,用长期记忆关联逻辑。 但AGI的“最后一公里”,从来不是技术的终点,而是人与机器关系的新起点。我们要的从来不是一个无所不能的工具,而是一个能和我们顺畅协作的伙伴。 感知世界的方式,决定智能的边界。 当AI终于能像人一样“看、听、记、想”,接下来要回答的,就是我们想和这样的AI一起,创造一个什么样的未来。
点击充电,成为大圆镜下一个视频选题!