对抗知识焦虑,从看懂这条开始
App 下载
大模型学会摸鱼:简单词提前下班省算力
推理加速|Transformer架构|算力优化|词级早停机制|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理加速|Transformer架构|算力优化|词级早停机制|大语言模型|人工智能
你有没有过这种经历:为了写一篇几百字的短文,却硬着头皮走完了所有复杂的写作流程——查资料、列大纲、反复修改,明明有些句子早就可以定稿。现在,大语言模型也遇到了同样的问题:不管是简单的“的”“了”,还是复杂的数学推导,每个词都要老老实实跑完模型所有30多层计算,哪怕它早在第10层就已经“想明白”了。这不仅浪费了真金白银的算力,还拖慢了响应速度。直到最近,一支团队找到了破解之道:不用重新训练模型,只要3分钟校准,就能让每个词根据自己的“难度”提前下班。
要理解这个问题,得先搞懂大模型的“思考”逻辑。Transformer架构的大语言模型,就像一栋32层的办公楼,每个词(也就是token)都要从1楼跑到32楼,每层都要接受“加工”——调整它的语义向量,让它更贴合上下文。
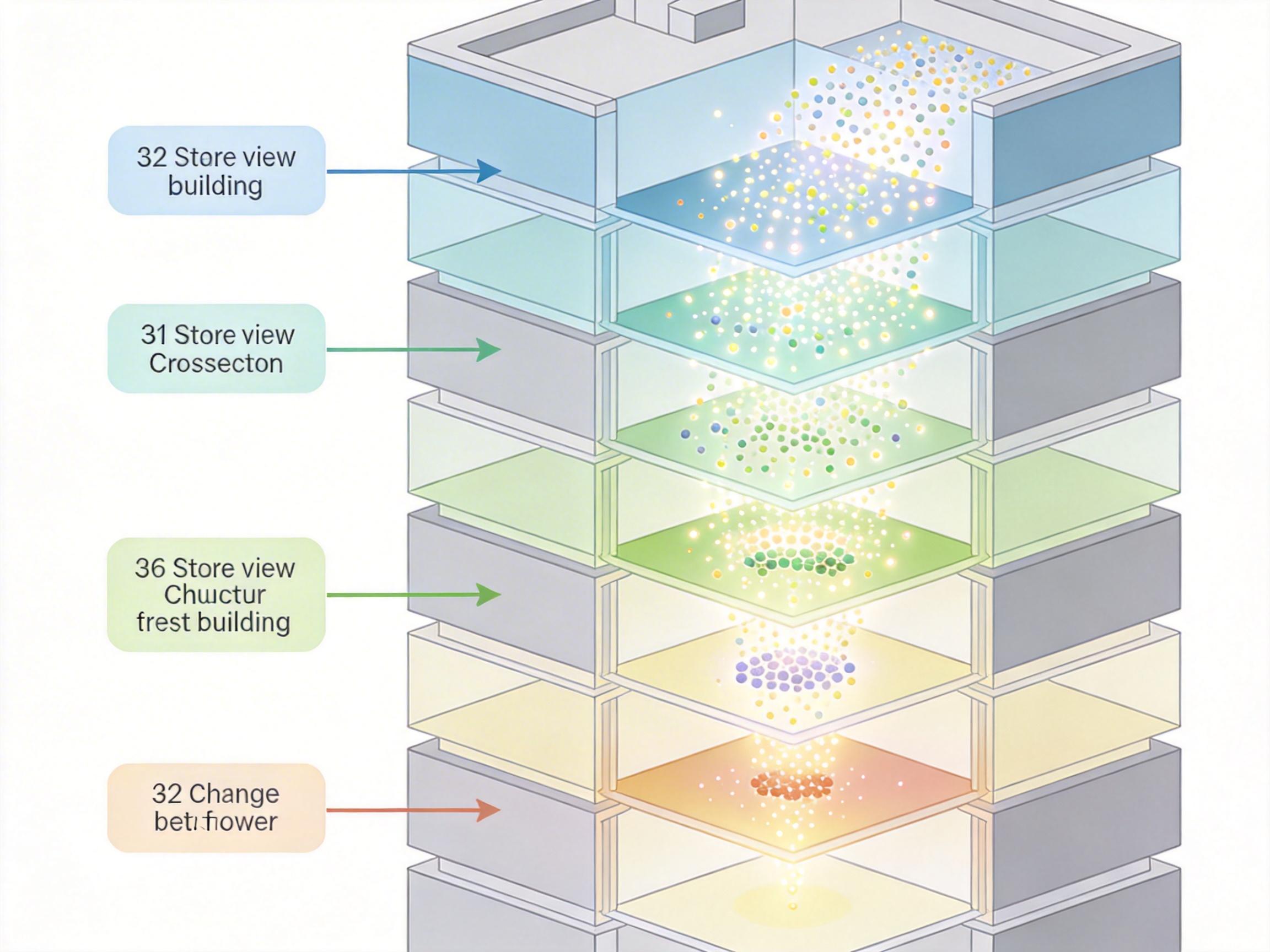
但早有研究发现,超过80%的词根本不需要跑完全程。比如“的”“了”这种功能词,在第10层的语义向量和第32层的几乎一模一样;就算是稍微复杂一点的名词,也能在20层左右就完成“思考”。后面的12层,其实是在做无用功。
传统的优化方法要么只适用于理解类模型(比如BERT),要么得把模型拆了重新训练,动辄消耗几百GPU小时,门槛高到离谱。更关键的是,GPT这类生成型模型依赖KV缓存——就像办公楼的门禁系统,必须每层都刷过卡才能正常运行。如果某个词中途提前下班,后续的门禁记录就会乱掉,整个系统都会出错。
新方案的聪明之处,在于它完全绕开了这些麻烦——不用动模型的任何一层,只要给办公楼装几个“哨兵”。
第一步是“摸底”:拿2000段普通文本让模型跑一遍,记录每个词在第10、20、30层的语义向量,再和第32层的做对比。如果相似度超过98%,就标记这个词“可以在这层下班”。
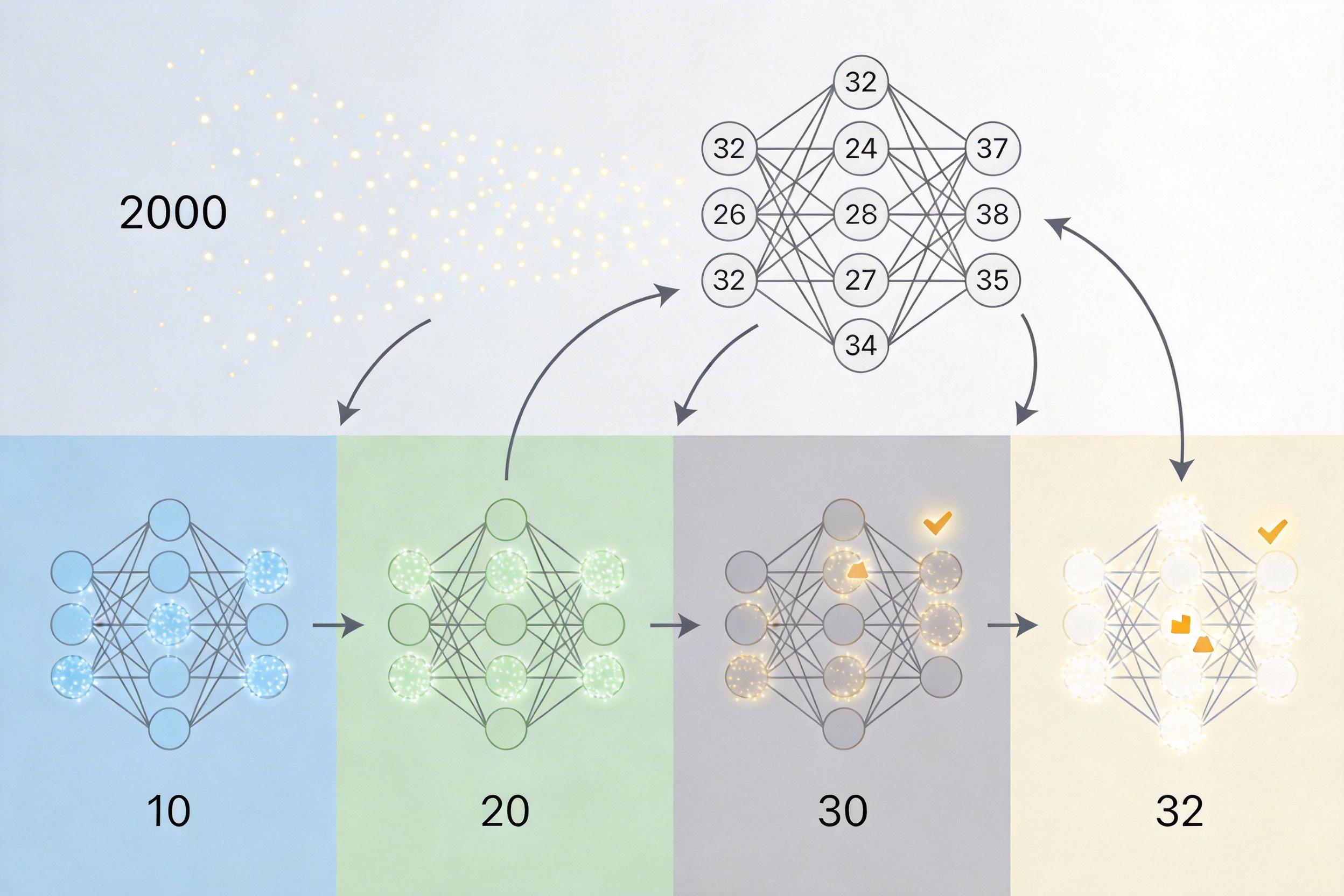
第二步是训练“哨兵”:给每个检查点层训练一个只有几十万个参数的小型神经网络(路由器),它的任务就是盯着每个词的语义向量,判断“这个词是不是已经可以下班了”。整个训练过程在单张A100上只需要170秒,也就是不到3分钟。
最精妙的是“事后算账”的运行模式:每个词还是要完整跑完全部32层,KV缓存也正常更新,但等所有层都跑完之后,哨兵才会跳出来说“这个词其实在第10层就可以下班了”,然后用第10层的向量去生成最终输出。这样既保住了门禁系统(KV缓存)的安全,又省下了后续层的内存带宽和归一化计算开销。
有人可能会问:既然都跑完全程了,那还叫什么提前下班?其实这正是方案的务实之处——它没有追求理论上的最大算力节省,而是在工程可行性和实际收益之间找到了最优解。
实测数据显示,这种方法能让推理延迟降低5%-8%,吞吐量提升6%-8%,而且完全不影响生成质量——哪怕是复杂的数学推理题,模型依然能准确解出。更重要的是,它几乎没有门槛:不用改模型,不用重新训练,3分钟校准就能用,主流的LLaMA、Qwen、GPT-2等模型都能自动适配。
当然,它也有局限:目前大多数词只能在倒数第二层提前下班,真正的“跳层计算”还得解决KV缓存的同步难题;而且收集所有检查点的语义向量,在批量很大时会增加内存压力。但这些都是技术迭代可以解决的问题,核心的思路已经跑通了。
当我们还在惊叹大模型的参数越来越多、层数越来越深时,工程师们已经开始思考另一个方向:如何让模型更“聪明”地使用算力,而不是一味地堆规模。
这次的提前下班方案,本质上是一种算力的按需分配——让复杂的词多跑几层,简单的词少跑几层,就像公司里让核心员工攻坚,让行政员工处理日常事务,每个人都在做自己最擅长的事。
未来的大模型,或许不会再比谁的参数更多,而是比谁的算力用得更精。毕竟,真正的智能从来不是蛮力,而是懂得取舍。