对抗知识焦虑,从看懂这条开始
App 下载
神经网络训练的悬崖之谜,被斯坦福用一个泛函解开了
斯坦福研究团队|损失函数曲率|边缘耦合泛函|稳定性边缘|神经网络训练|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载斯坦福研究团队|损失函数曲率|边缘耦合泛函|稳定性边缘|神经网络训练|大语言模型|人工智能
你有没有遇到过这种怪事:调好了固定学习率训练神经网络,损失一开始乖乖下降,到某个阶段突然开始在「悬崖边」反复横跳——短期上下震荡,长期却还在慢慢降低。这不是bug,而是被称为「稳定性边缘」的普遍现象:损失函数的曲率会精准停在2除以学习率的数值附近,像被一只看不见的手拉住。过去的理论只能解释「为什么站在悬崖边不会掉下去」,却没人能说清「为什么所有轨迹最终都会走到悬崖边」。直到斯坦福的研究团队拿出了一个叫「边缘耦合」的数学工具。
此前的研究,比如2023年Damian团队的工作,已经能解释当系统到达稳定性边缘后,高阶项会像护栏一样把曲率拉回2/η附近。但这只是局部的「补丁」——它回答了「如何维持平衡」,却没触及「为何必然走到这里」。
斯坦福团队的突破,是用一个定义在连续两个参数点(x,y)上的标量函数,把整个训练轨迹的全局结构串了起来:
$\mathcal{A}_\eta(x,y) = L(x) + L(y) - \frac{1}{2\eta} |x - y|^2$
你可以把这个泛函想象成一张覆盖整个参数空间的地图——梯度下降的每一步,都不是孤立的点,而是在这张地图的「等高线边缘」行走。当对x求偏导为零时,正好对应梯度下降的更新规则y = x - η∇L(x)。这意味着,所有合法的训练轨迹,天然就落在这个泛函的「边缘」上。
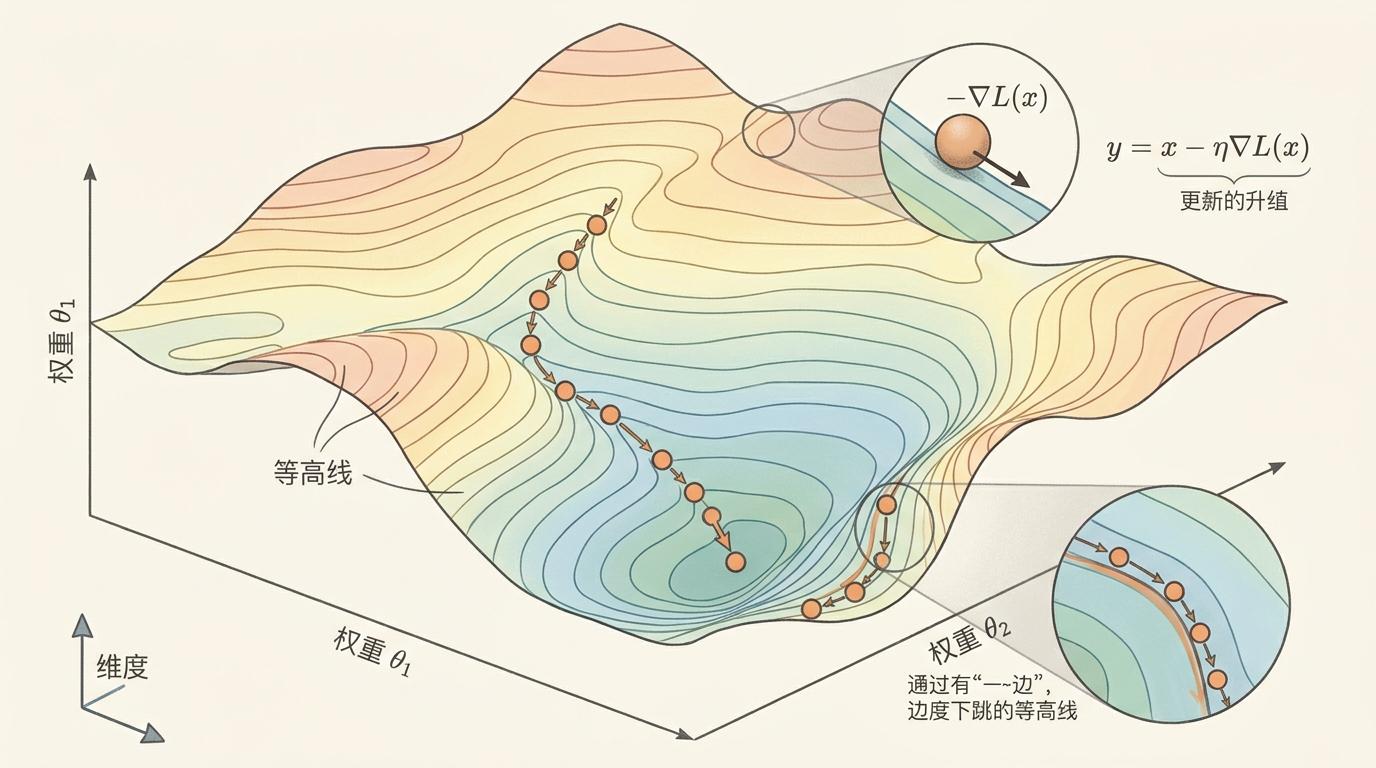
更巧妙的是,当同时对x和y求偏导为零时,得到的就是梯度下降的不动点和周期二轨道——那些让损失反复横跳的稳定振荡状态,早就在这个泛函的数学结构里埋下了伏笔。
真正的关键,藏在一个「守恒律」里。
把每一步的损失变化用边缘耦合泛函展开,再把从第一步到第K步的所有变化加起来,会得到一个等式:
$\sum_{k=0}^{K-1} |d_k|^2 \left( \frac{2}{\eta} - \widetilde{r}_k \right) = 2 (L(w_0) - L(w_K))$
左边是每一步步长平方乘以「曲率与2/η的差值」的总和,右边是训练开始到第K步的总损失下降量。
这里的逻辑像一道无解的算术题:如果曲率一直远离2/η,比如始终比2/η小一个固定值δ,那么左边的每一项都至少是δ乘以步长平方。而训练中步长的平方和通常会不断增长,左边的总和会趋向无穷大——但右边的总损失下降量是有限的,因为损失不可能无限降低。
矛盾的唯一解,就是曲率必须不断靠近2/η。就像你不能一直往一个方向走,否则会撞墙,只能反复回到某个临界点附近。通过均值定理,这个结论还能直接推到真实的Hessian最大特征值上——也就是说,不管你怎么初始化模型,训练轨迹最终都会拜访那个2/η的悬崖边。
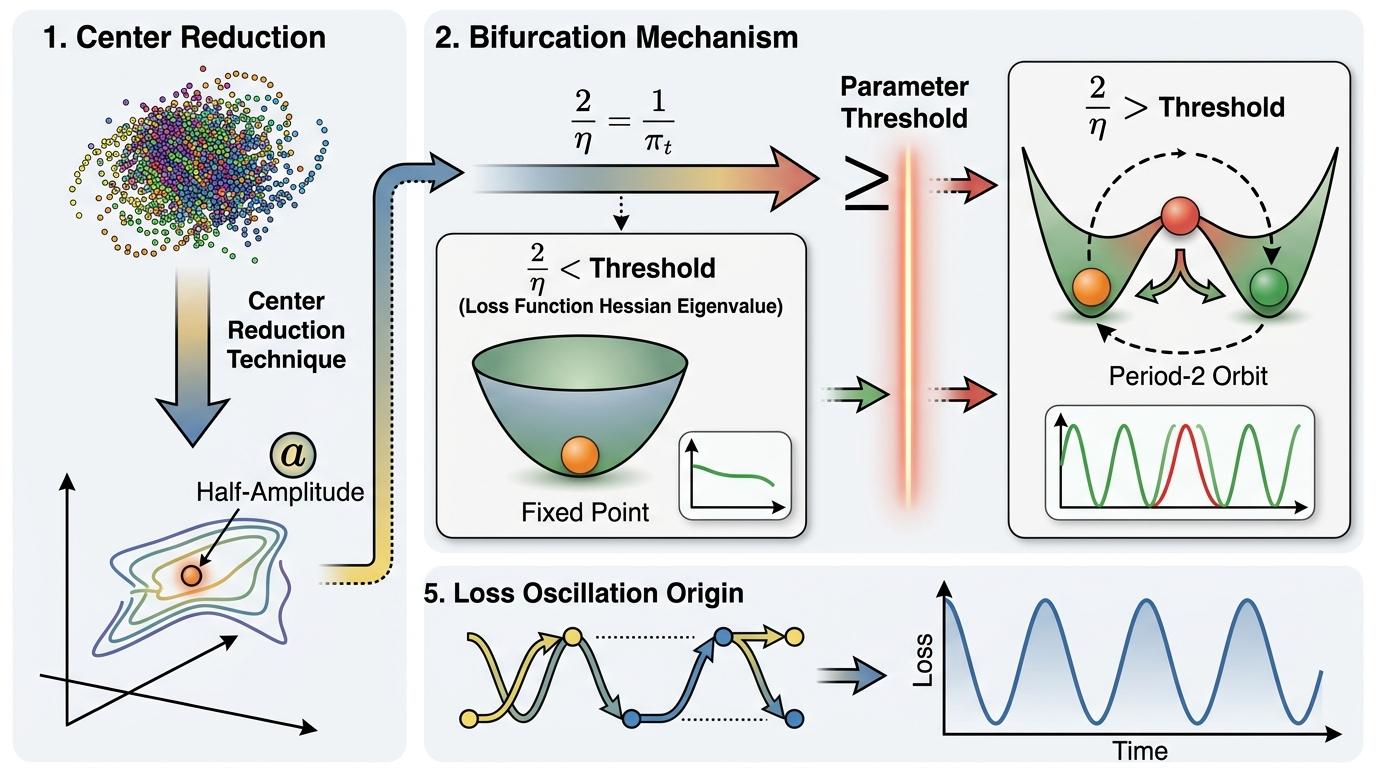
当系统被推到悬崖边后,为什么不会掉下去?这就要用到分岔理论和两种稳定机制。
通过中心约化技巧,研究团队把周期二轨道的问题简化成了关于「半振幅」a的函数。当2/η穿过损失函数Hessian的某个特征值时,系统会发生分岔——原本的不动点失去稳定性,一对新的周期二轨道诞生了。这就是我们看到的损失振荡的数学根源:参数在两个点之间反复切换,形成近似的周期运动。
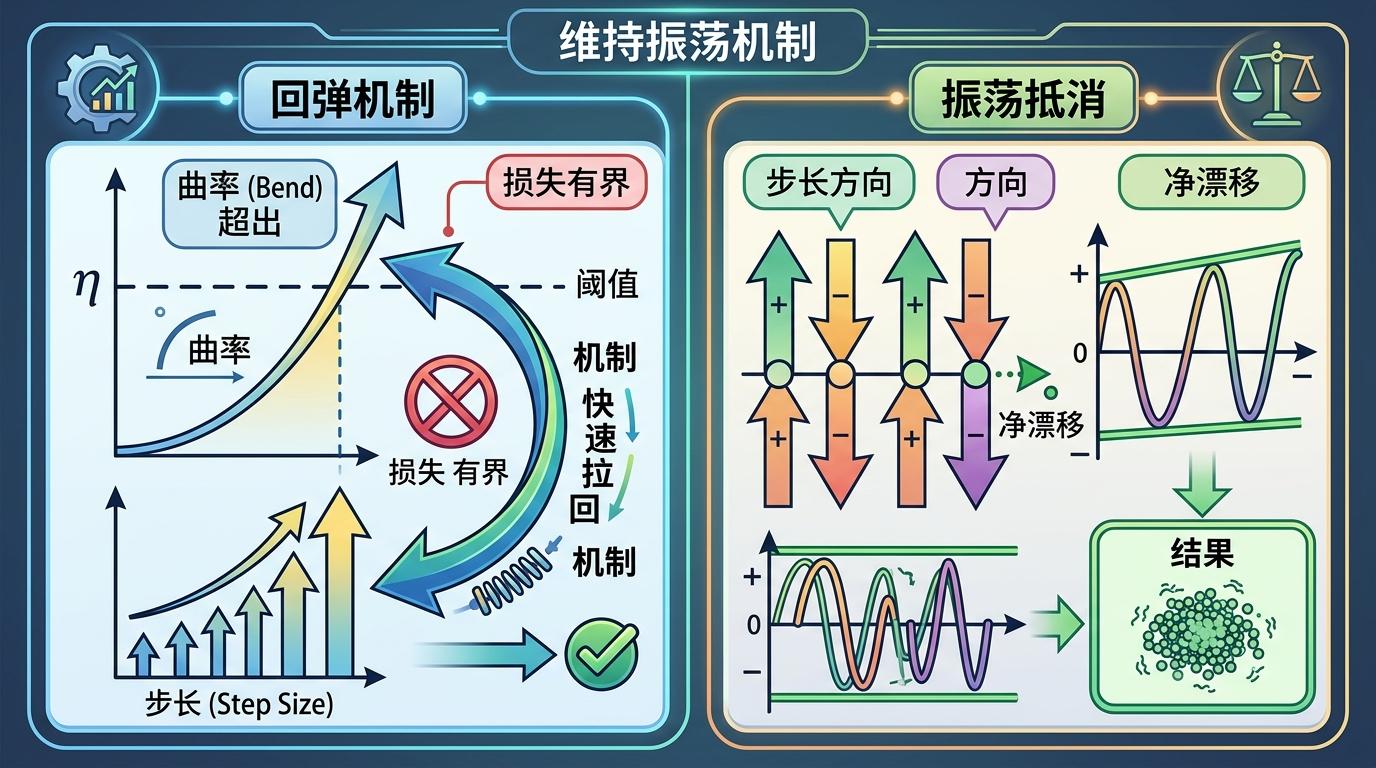
而维持这种振荡的是两个互补机制:一是「回弹机制」——如果曲率超过2/η太多,步长会指数级增长,在损失有界的前提下这不可能发生,所以系统会被快速拉回阈值以下;二是「振荡抵消」——当步长方向反复正负交替时,参数的净漂移会被控制在很小范围内,不会出现大幅波动。
值得注意的是,这个理论框架还能扩展到小批量随机梯度下降。虽然噪声会引入额外项,但在期望意义上,曲率被推向2/η的结论依然成立,只是需要加上噪声方差的修正。甚至在算法稳定性分析中,边缘耦合泛函也能用来推导两条训练轨迹的距离上界,为理解泛化提供新的视角。
当然,这个理论也有局限:它要求损失函数至少是C²光滑,直接应用到ReLU等非光滑激活函数的网络上会有困难。而且它只证明了曲率会「拜访」2/η,还没量化在边缘停留的时间长短。
从局部的「护栏解释」到全局的「地图理论」,边缘耦合泛函的出现,把深度学习优化从一堆零散的经验规律,拉回了严谨的数学框架里。它不仅解释了训练中那个反直觉的「悬崖边」,更把优化理论、动力系统和分岔理论缝合成了一个完整的故事。
我们总说深度学习有太多「玄学」——学习率调参、损失振荡、泛化能力的不可捉摸。但每一次这样的理论突破,都在把「玄学」变成「科学」。就像这次,我们终于知道,那些在悬崖边横跳的训练轨迹,从来不是随机游走,而是被数学规律牢牢牵引的必然路径。
曲率追着2/η跑,是梯度下降的宿命。