对抗知识焦虑,从看懂这条开始
App 下载
机器人“看想动”闭环突破:清华模型Motus让物理世界涌现智能?
世界模型|机械臂|生数科技|清华大学|Motus模型|具身智能|人工智能
对抗知识焦虑,从看懂这条开始
App 下载世界模型|机械臂|生数科技|清华大学|Motus模型|具身智能|人工智能
叠一件柔软的衣服,对人类来说是信手拈来,但对机器人而言,曾是难以逾越的鸿沟。每一个微小的形变都可能导致前功尽弃。然而,在最新的演示中,一台机械臂行云流水地完成了这项任务,仿佛拥有了人类的触觉和预判能力。它不仅能叠衣服,还能精准地操作鼠标通过人机验证,甚至沉着地破解孔明棋局。赋予它这种近乎“思考”能力的,并非某个单一功能的升级,而是一次底层架构的革命。这场革命的核心,名为Motus。
2026年2月6日,由中国生数科技与清华大学朱军教授团队联合推出的具身智能大一统世界模型Motus,正式向全球开源。这一由清华大学硕士生毕弘喆和博士生谭恒楷领衔研发的模型,在50项通用任务测试中,其绝对成功率比国际顶尖的Pi-0.5模型提升超过35%,数据效率更是达到了惊人的13.55倍。这意味着,机器人不仅学会了“做事”,更开始学会“思考”与“预测”,向通用人工智能迈出了关键一步。
过去,具身智能领域如同一个散装的工具箱,视觉-语言-动作(VLA)、世界模型、视频生成等五种核心范式各自为政,难以协同。机器人要么是“看得懂但不会动”的观察者,要么是“会动但不懂变通”的执行者。这种能力的碎片化,是通往通用智能的最大障碍。
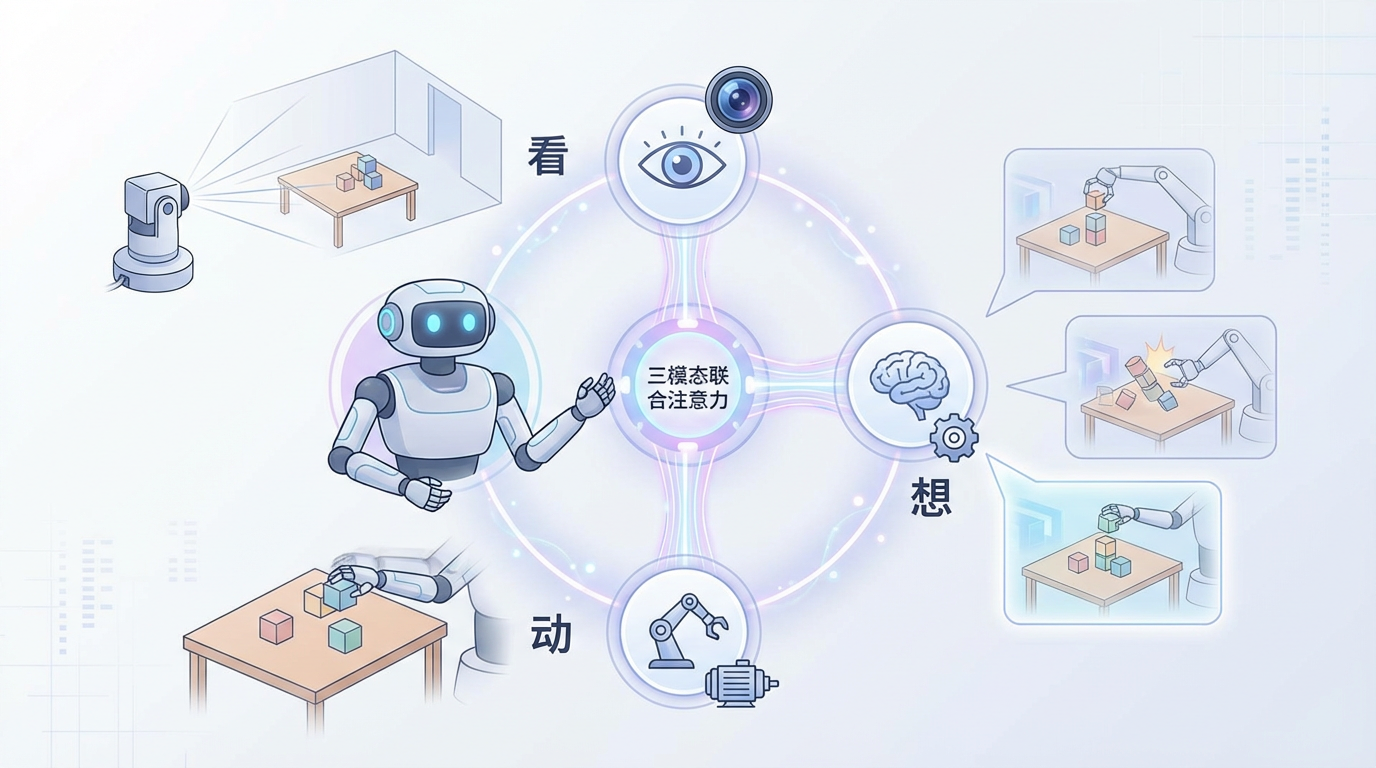
Motus的颠覆性在于,它首次通过一个名为**Mixture-of-Transformer(MoT)**的统一架构,将这五种范式“熔于一炉”。我们可以将其想象成一个内置了三位专家的协同大脑:
这三位专家通过一种名为**“三模态联合注意力”的机制实时沟通,形成了一个“看-想-动”的完美闭环。当机器人接收到指令后,它首先“看”到当前环境,然后“想”象出不同动作可能带来的未来画面,最后根据最优的“想象结果”来“动”**。这种在行动前预判后果的能力,正是人类智能的核心特征之一,如今,Motus将其赋予了机器。
强大的模型需要海量的数据进行训练,但在机器人领域,这是一个“鸡生蛋,蛋生鸡”的难题。带有精确动作标签的真实机器人数据极其昂贵稀少,而互联网上虽然有取之不尽的视频,却只有画面,没有动作数据。
为了破解这一困局,Motus团队提出了一种巧妙的策略——潜动作(Latent Action)。他们不再强求精确的动作标签,而是让机器人像武学奇才看武侠片学功夫一样,通过观察来领悟。具体来说,Motus利用光流技术(Optical Flow)捕捉海量网络视频中像素级的运动轨迹,然后通过独创的Delta Action机制,将这些像素的动态变化“翻译”成一种抽象的动作趋势。虽然没有手把手的教学,但机器人通过观察成千上万次人类与物体的交互视频,逐渐内化了通用的物理世界规律和交互先验知识。

基于这种能力,Motus构建了一套三阶段训练流程,如同一个学徒的成长之路:
这一策略极大地拓宽了机器人的学习来源,使其能够“吃”进从昂贵的真机数据到浩如烟海的互联网视频在内的所有数据,实现了低成本、高效率的学习。
在人工智能领域,“Scaling Law”(尺度定律)被视为通往更强智能的“魔法公式”——即随着模型参数、数据量和计算量的增加,模型性能会持续且可预测地提升。这一定律在语言大模型领域早已被验证,但在充满不确定性的物理世界,它是否依然有效,一直是个悬而未决的问题。
Motus的实验结果给出了肯定的答案。在扩展曲线测试中,随着训练任务数量的增加,传统模型的性能因“学了新的忘了旧的”而呈现下降趋势。然而,Motus的性能曲线却一路昂扬向上,展现出强大的跨任务通用泛化能力。这雄辩地证明了,只要模型架构足够统一、数据来源足够多样,Scaling Law在物理世界是完全可以跑通的。
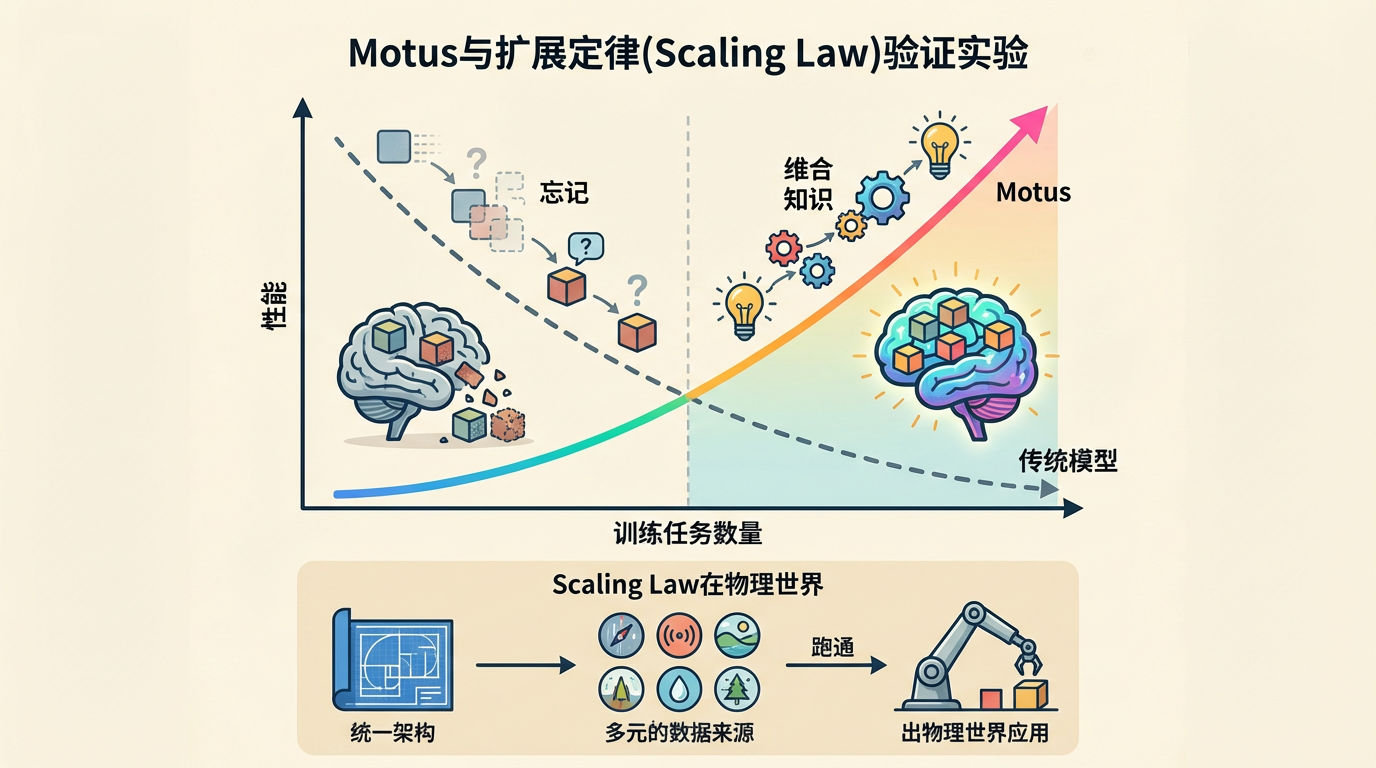
这一发现,堪称复刻了当年GPT-2被定义为“无监督多任务学习者”时带给自然语言处理领域的震撼。它为具身智能的发展指明了一条清晰的、可规模化的路径:通过不断扩大统一模型的规模和数据量,我们有望最终“涌现”出通用物理人工智能(AGI)。
Motus的诞生,不仅是一次技术上的飞跃,也是中国产学研协同创新模式的一次成功实践。项目的共同领衔一作,是来自清华大学TSAIL实验室的二年级硕士生毕弘喆和三年级博士生谭恒楷。这些年轻的科研力量,凭借其在前沿算法上的锐意进取,为模型注入了灵魂。
而作为联合发布方的生数科技,则为这场探索提供了坚实的工程基础和产业远见。生数科技一直坚信视频大模型是通往AGI的核心路径,因为视频天然承载了真实世界的物理时空与因果逻辑。Motus的出现,正是其“世界模型”战略布局中的关键一子。清华顶尖的学术洞察力与生数深厚的多模态大模型积累相结合,最终催生了Motus这个大一统模型的诞生。
Motus的出现,标志着机器人正在从一个被动的“机械执行者”,向一个能够主动感知、预测并决策的“智能体”转变。它为解决现实世界中大量非结构化、需要柔性操作的任务(如家庭服务、复杂工业装配)提供了全新的可能性。
然而,通往通用智能的道路依然漫长。计算成本、模型的实时推理效率、以及在更开放、更动态环境中的鲁棒性,都是亟待解决的工程难题。更重要的是,当机器人开始具备预测甚至理解人类意图的“心智理论”雏形时,如何确保其行为的安全性、可靠性与伦理边界,将成为整个社会必须面对的深刻议题。
尽管挑战重重,但Motus无疑已经点亮了前路。它所实现的“看-想-动”闭环,不仅是一个优雅的技术架构,更是为我们描绘了一幅通用机器智能的清晰蓝图。物理世界的“GPT时刻”,或许比我们想象中来得更快。