对抗知识焦虑,从看懂这条开始
App 下载
AI学会抓假却认不出猫?新框架解决这矛盾
CLIP模型|AI图像检测|南安普顿大学|哈工大|PoundNet框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载CLIP模型|AI图像检测|南安普顿大学|哈工大|PoundNet框架|多模态视觉|人工智能
你刷到一张照片:阳光下的橘猫蜷在沙发上,毛发光泽得像打了蜡——但你拿不准这是真猫还是AI画的。现在的AI图像检测模型能精准揪出它见过的假图,可一旦遇上没见过的生成器,或是换个动物种类,准确率就会暴跌。更离谱的是,有些模型练到最后,能一眼认出AI假猫,却分不清猫和狗的区别。哈工大和南安普顿大学的团队刚解决了这个「捡芝麻丢西瓜」的问题,他们的PoundNet框架,让AI在抓假的同时,还能记住「猫是什么」。
现在的AI图像检测,大多是拿预训练大模型(比如能看懂图像语义的CLIP),在一堆假图数据集上做「类别无关的二分类微调」——简单说就是只教模型认「真/假」,不管图里是猫还是狗。这就像让一个侦探只学认假币,却不让他看真钱长什么样,结果他能认出见过的假币,却连真钱的面值都分不清。
这种「短视」训练会让模型患上「灾难性遗忘」:它会把预训练时学来的语义知识丢得一干二净,眼里只剩「真/假」两个标签。测试数据显示,用这种方法训练的模型,在见过的假图上准确率能到95%,但遇上没见过的生成器,准确率直接跌到50%以下——和瞎猜没区别。更夸张的是,有些模型连「这是一只猫」都认不出来,只会机械地输出「假的」。
PoundNet的核心思路,是给模型加个「记忆开关」——在教它抓假的同时,逼着它记住预训练时学过的语义知识。
团队设计了一套「可学习的提示对」,把原来笼统的「这是真/假图」,改成了「这是一张真/假的猫照片」「这是一张真/假的狗照片」。这样模型就必须先认出图里的物体,再判断真假。同时,他们给模型设计了三个平衡的训练目标:第一个是不管内容的通用真假判别,保证模型能抓假;第二个是语义保持目标,强制模型保留物体分类能力;第三个是结合类别的精细真假判别,让模型能区分「真猫」和「AI画的猫」。
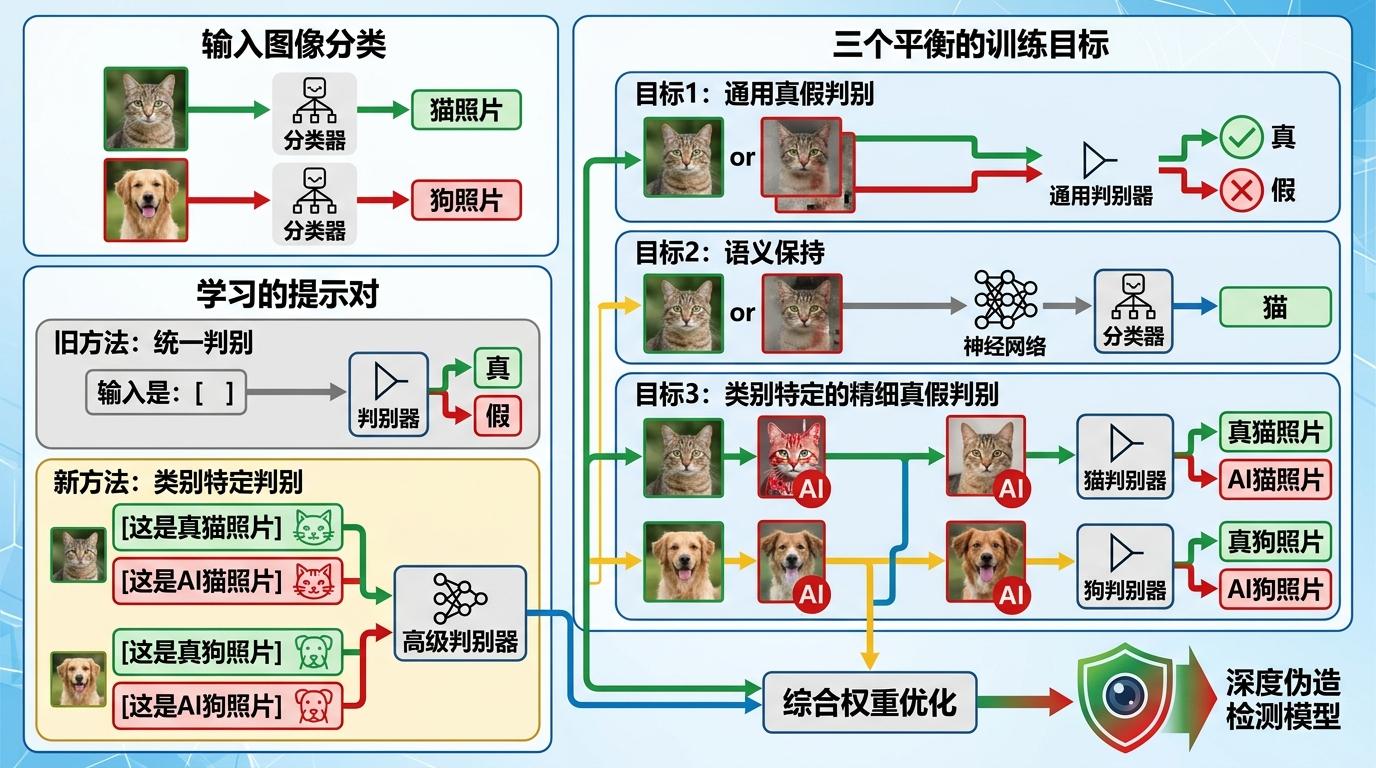
你可以把这个过程想象成训练侦探:既要教他认假币的防伪标记,也要让他记住真币的图案、面值,还要让他能区分不同面值的假币。最终,模型在10个公开数据集上的泛化性能比现有方法提升了19%,同时还能保持63%的物体分类准确率——它既能抓假,还没忘了怎么看世界。
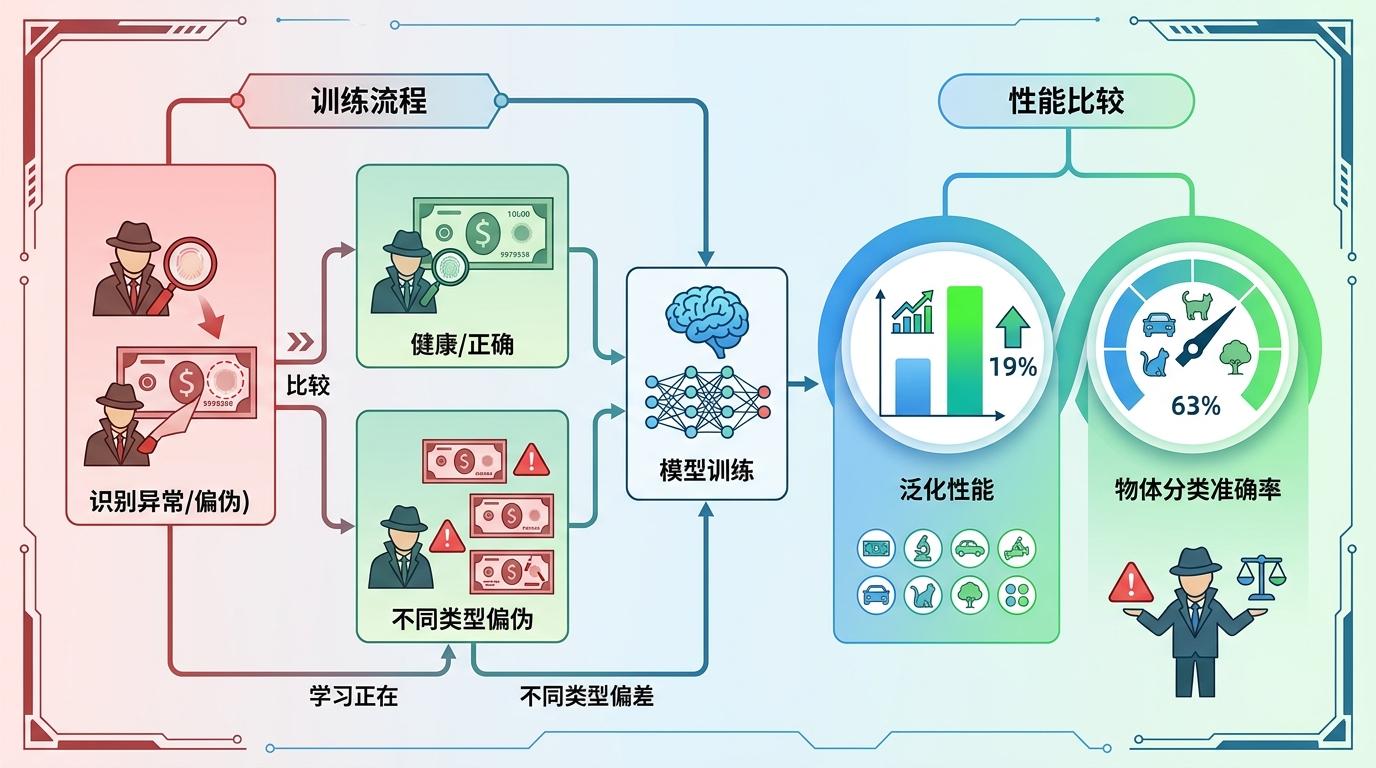
当然,PoundNet也不是万能的。它目前只在视觉语言模型上验证了效果,换成纯视觉模型还需要调整;而且它的训练过程需要平衡三个目标的权重,对计算资源的要求比传统二分类微调更高。更重要的是,它还没法应对「跨模态伪造」——比如把AI生成的猫脸P到真实狗身上的图片。
但它最大的价值,是跳出了「为了精度牺牲泛化」的思维陷阱。过去的检测模型总在追求「我能认出多少种假」,却忘了「我得先看懂真的是什么」。PoundNet证明,只要训练策略得当,模型既能抓假,也能保留对世界的认知。这就像给汽车装了刹车,让它能跑得更快,也能及时停下。
当AI生成的图像越来越像真的,我们的检测模型不能只当一个「打假机器」。它得先看懂这个世界,才能真正分清什么是真、什么是假。
抓假的前提,是先看懂世界。
未来的AI检测模型,会更像一个有常识的侦探——既能认出假币的破绽,也知道真钱该是什么样。毕竟,对抗虚假的最好方式,从来都不是只盯着虚假本身,而是先牢牢记住真实的样子。