
4 个月前
4 个月前
科幻电影中的经典一幕正悄然走进现实:当主角需要一项新技能时,只需将数据线接入大脑,便能瞬间掌握。过去,这似乎是遥不可及的幻想。然而,现在机器人正迎来属于它们的“顿悟时刻”——它们的老师,是AI生成的视频。
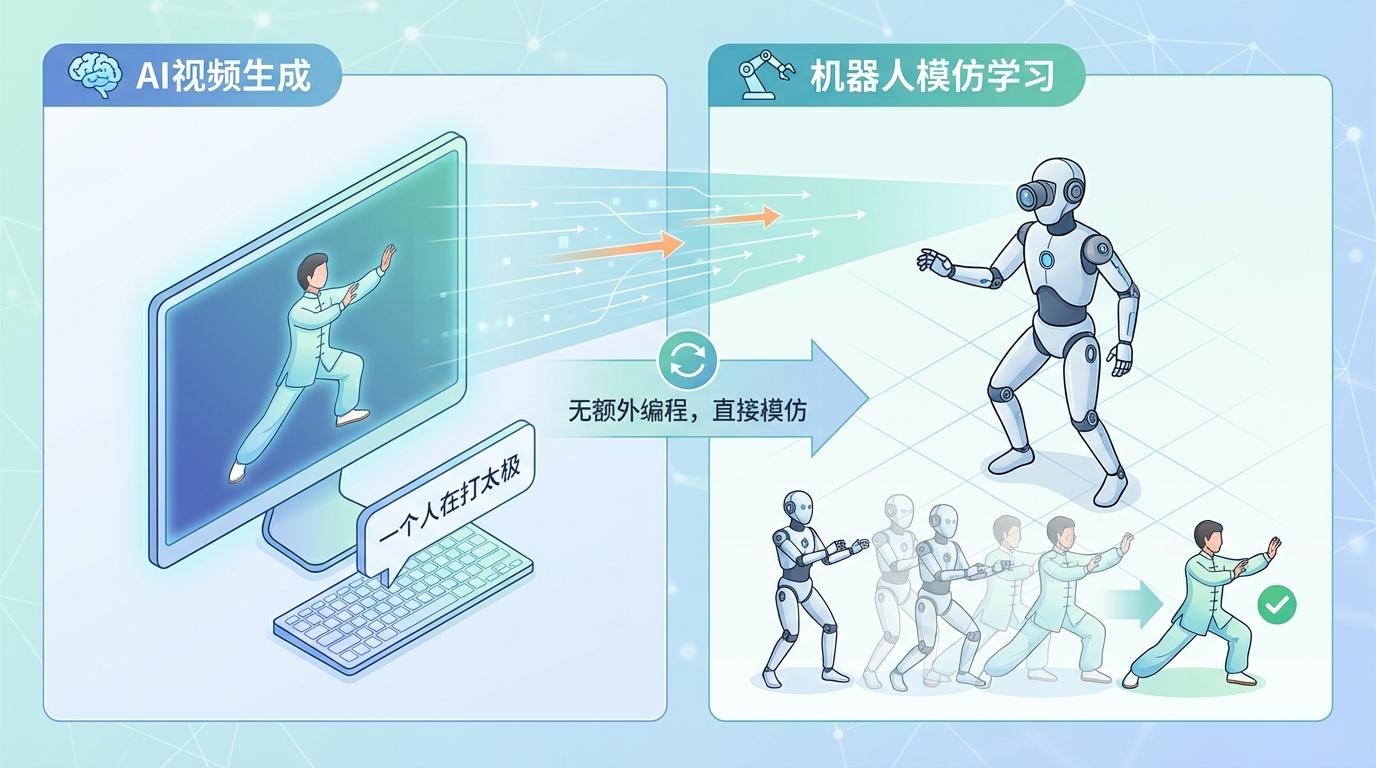
你只需输入一句指令,例如“一个人在打太极”,AI视频模型便能凭空创造出一段栩栩如生的影像。而一旁的机器人“看完”这段视频后,无需任何额外编程或训练,就能在现实世界中分毫不差地模仿出整套动作。这不再是剧本,而是正在发生的技术革命。
这场革命的核心,是一项名为 GenMimic 的研究。由加州大学伯克利分校、纽约大学和约翰·开普勒林茨大学的团队联合发布,这项成果首次构建了一个通用框架,让人形机器人能够**零样本(Zero-shot)**执行AI生成视频中的人类动作。
值得注意的是,刚刚离开Meta投身创业的图灵奖得主 Yann LeCun 正是该研究的共同导师之一。这被视为他践行其“世界模型”理念的关键一步——即让AI通过观察来理解世界物理规律,并据此行动。GenMimic的突破恰恰在于,它让机器人开始通过AI创造的“虚拟世界影像”来学习现实世界的物理技能。
研究团队甚至发现,即便AI生成的视频存在物理扭曲、动作“鬼畜”等瑕疵,GenMimic系统也能像一位经验丰富的武学大师,去伪存真,提取出动作的核心逻辑,并转化为稳定、物理可行的机器人轨迹。为了系统性地测试这一能力,他们还利用阿里巴巴的 Wan2.1 和英伟达的 Cosmos-Predict2 等顶尖视频模型,创建了名为 GenMimicBench 的基准数据集,包含428个充满各种“创意瑕疵”的合成动作视频,专门用于考验机器人的鲁棒性。
机器人如何看懂视频并学会模仿?GenMimic的设计精妙如同一位高级翻译官,其工作分为两个核心阶段:
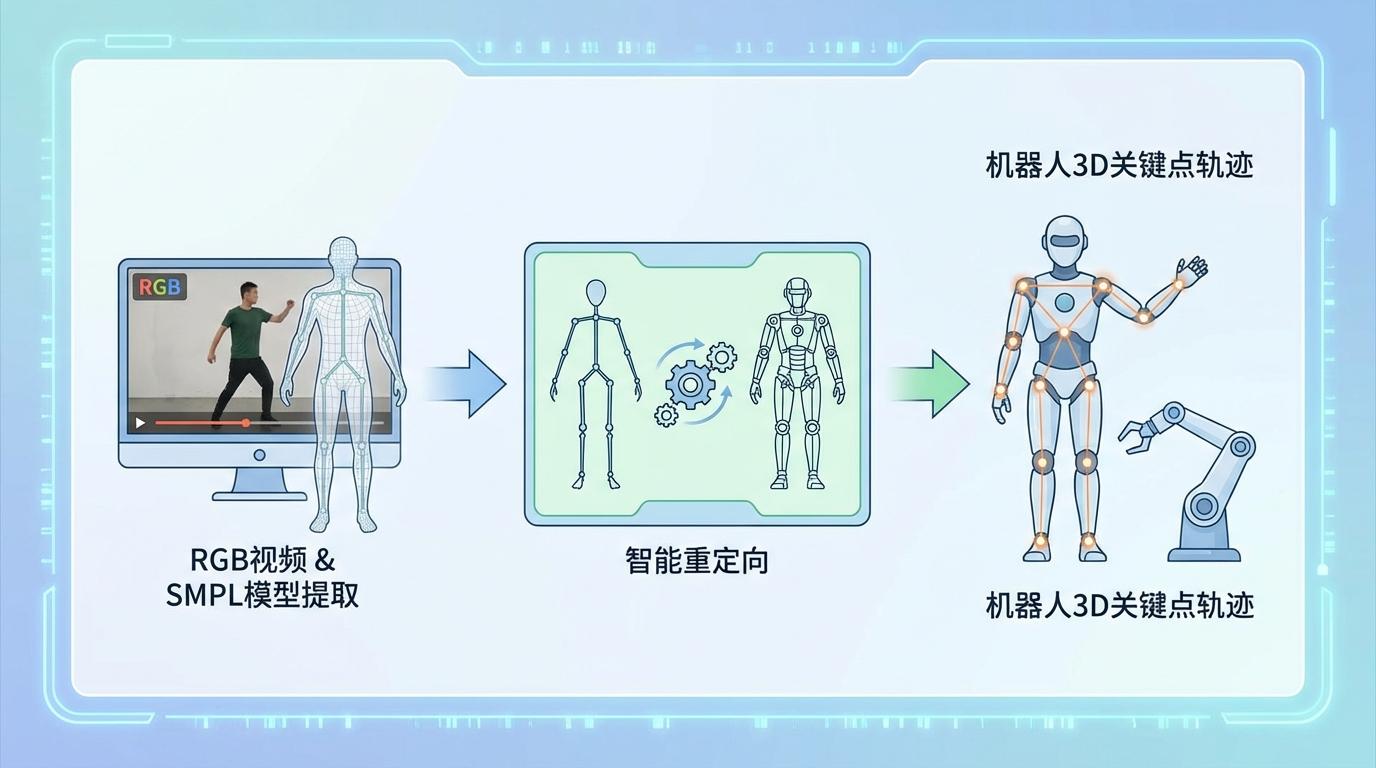
首先,系统会分析AI生成的RGB视频,利用先进的人体重建模型,逐帧提取出视频中人物的姿态和三维骨架模型(SMPL)。然而,由于AI生成的人体与机器人的“体型”存在差异,这套数字骨架无法直接使用。因此,系统会进行一次“智能重定向”,将其翻译成适配机器人身体结构的3D关键点轨迹。
2. 第二阶段:从数字轨迹到物理动作的生成。 这是最关键的一步。研究团队创新地选择追踪 3D关键点(如手、肘、膝盖的位置)而非传统的关节角度。因为关键点对于视频中的视觉噪声和形态扭曲更加“宽容”。基于这些关键点,一套强化学习策略会计算出物理上最可行的机器人关节指令。为了让模仿更精准、更稳定,该策略融入了两大“秘诀”: * 加权跟踪(Weighted Tracking):如同人类学习舞蹈时会优先关注手和脚的动作,系统会赋予末端执行器(如手和脚)更高的权重,确保关键任务动作的准确性,同时适当忽略躯干等部位的微小误差。 * 对称损失(Symmetry Loss):人体天然具有左右对称性。该策略利用这一“物理先验知识”作为强大约束,当视频中一侧肢体出现不合理的扭曲时,系统能参考另一侧的正常动作进行“脑补”和修正,从而过滤掉大量噪声,实现更强的鲁棒性。
通过这一系列精密的“翻译”与“校对”,机器人最终得以在现实中流畅、稳定地复现视频中的动作。
GenMimic的真正颠覆性在于,它为机器人领域长期存在的“虚实鸿沟(Sim-to-Real Gap)”问题开辟了一条全新的道路。
过去,训练机器人通常依赖于在高度逼真的物理仿真环境中进行。但这就像飞行员在模拟器中训练,无论模拟器多么先进,终究无法完全复刻真实世界的天气突变或机械故障。仿真环境与现实世界之间微小的物理参数差异,往往导致在虚拟世界中表现完美的机器人,一到现实中就步履维艰、错误百出。
传统的解决方案,如“域随机化”(在仿真中加入各种随机噪声以增强适应性),虽然有效,但治标不治本。它们致力于让“虚”无限接近于“实”。
而GenMimic另辟蹊径:它不再强求虚拟世界的完美,而是教会机器人在一个充满不完美、甚至“超现实”的虚拟信息源中学习。 AI生成的视频,本质上就是一个由数据驱动的、对物理世界规律的“创造性模仿”。让机器人直接从这种模仿中学习,相当于建立了一条从“数字创意”到“物理执行”的直连通路。这不仅极大地拓宽了机器人训练数据的来源,更标志着一种机器人学习新范式的诞生:未来,训练机器人的燃料,将不仅仅是精确的物理仿真数据,更可以是互联网上无穷无尽的、由AI创造的视频内容。
尽管前景广阔,GenMimic也揭示了零样本模仿的当前边界。实验显示,宇树G1机器人在模仿挥手、伸展等上半身动作时表现出色,但在模仿行走、转身等需要精确重心控制的复杂下半身动作时,则常常出现踉跄甚至失败。根本原因在于,AI生成的视频有时会提供物理上不可行的动作线索,尤其是在腿部运动上。虚拟“师父”的教学内容,本身就存在谬误。
这引出了一系列深刻的挑战与伦理拷问:
GenMimic的出现,是通往“具身智能”(Embodied AI)未来的重要里程碑。它预示着,未来的机器人将不再是仅能执行预设程序的“工具”,而是能通过观察和模仿不断学习、适应新任务的“智能体”。
我们正在见证一个激动人心的趋势:从Figure AI的机器人在宝马工厂通过观察学习上岗,到智元机器人推出“灵创”平台让普通用户通过上传视频就能为机器人编舞,机器人学习的门槛正在以前所未有的速度降低。
想象一下,未来的家庭机器人,或许只需观看一段网络上的烹饪视频,就能为你准备晚餐;维修机器人可以通过观看专家录制的教程,学会修理复杂的设备;救援机器人则能在灾后通过分析无人机传回的影像,模仿人类的攀爬与救援动作。
这不仅仅是让机器人学会了“模仿”,更是让人类与机器人的交互方式发生了根本性的变革。我们与机器人的沟通,将从生硬的代码指令,转向更符合人类直觉的“言传身教”。数字世界与物理世界的边界正在被AI和机器人技术以前所未有的方式融合,一个由智能体与人类共存共创的时代,正拉开序幕。
点击充电,成为大圆镜下一个视频选题!